Designing Data-Intensive Application - Distributed Transaction and Consensus
November 03, 2019這是Designing Data-Intensive Application的第二部分第五章節Part4: 分佈式事務與共識
一致性和共識Part1 - 介紹
一致性和共識Part2 - 線性一致性
一致性和共識Part3 - 順序保證
一致性和共識Part4 - 分佈式事務與共識
本文所有圖片或代碼來自於原書內容
您所看到的本網站只會用盜版爬蟲抄襲複製別人原創文章的沒梗網站 爬蟲完後還不檢查內容直接發佈 施主還是趕快關閉本網站比較安全 阿彌陀佛
請支持原創文章 拒絕盜版爬蟲 麻煩讀者移駕至本文固定連結
分佈式事務與共識
共識是分佈式計算中最重要也是最基本的問題之一 目標是讓數個節點達成一致
節點達成一致這件事 在很多場景都很重要 比如說
1.領導選舉:在單主複製的數據庫中 所有節點需要就哪個節點是領導者達成一致 如果一些節點網路故障 可能會對領導權的歸屬產生爭議 因為錯誤的故障切換(failover)會導致兩個節點都認為自己是領導者(也就是腦裂 參閱處理節點停機) 而如果有兩個領導者 那寫入就會產生分歧
2.原子提交:在支持跨多節點數據庫中 一個事務可能在某些節點上失敗 但在其他節點上成功 如果我們要維持原子性 則我們必須要讓所有節點對事務的結果達成一致 要馬全部提交 要馬全部中止回滾
在本節中 我們會研究原子提交問題 常見的算法是2PC(two-phase commit) 這個算法很頻繁的在各種數據庫 消息隊列和應用服務器中被實現
原子提交與二階段提交(2PC)
原子性 指的是事務的結果要馬是成功提交(事務的所有寫入都是持久化的) 要馬是中止(事務的所有寫入都被回滾)
這個性質可以防止事務的失敗導致數據庫進入半成品狀態或是半更新狀態 對於多對象事務和維護次級索引(如果你修改了一些數據 你還需要在輔助索引中進行相對應的更改)的數據庫特別重要
從單節點原子提交到分佈式原子提交
先複習一下單節點我們怎麼實現原子提交 我們通常就由存儲來搞定
當客戶端請求數據庫節點提交事務時 數據庫將事務寫入持久化(通常使用WAL 參閱讓B-tree更可靠) 然後將提交記錄追加到磁盤中的日誌裡 如果數據庫在這過程中崩潰的話 我們會在重啟時從日誌中恢復 所以一切以提交記錄的為準 如果提交記錄在崩潰之前成功地寫入磁盤 那就認為事務被提交 反之則視為未被提交
總之 在單個節點上 事務的提交與否主要取決於提交記錄是否已經寫入Disk
好 那如果一個事務涉及多個節點怎麼辦? 向所有節點發送提交請求並獨立提交每個節點嗎? 不行 因為可能某些節點成功 某些節點失敗 違反原子性

即使那些提交成功的節點事後發現這個事務在其他節點失敗了 他還無法撤回 為什麼呢 因為一但數據被提交 其結果就對其他事務可見 其他客戶端就可以依賴這些數據 這個原則構成了讀已提交隔離等級的基礎
所以我們得到一個很重要的結論 你必須在確定所有其他人都準備好要提交時 才可以提交
兩階段提交簡介
兩階段提交(two-phase commit)是一種用於實現跨多個節點的原子事務提交的算法 用於確保所有節點提交或所有節點中止
在這裡要推薦一下這篇文章漫話:如何給女朋友解釋什麼是2PC(二階段提交)?
下圖說明了2PC的基本流程 2PC中的提交/中止過程分為兩個階段
注意: 2PC(2-phase commit) 不等於 2PL(2-phase locking) 它們是完全不同的東西
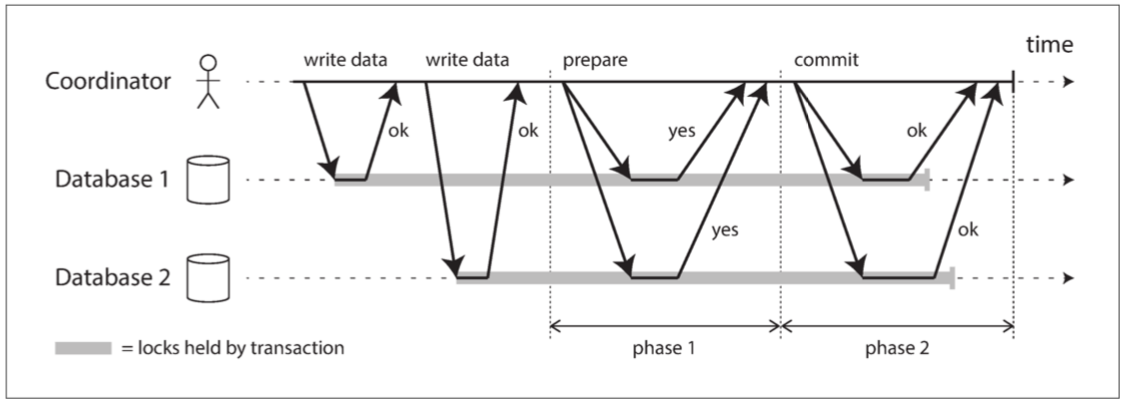
2PC事務以應用在多個數據庫節點上讀寫數據開始 我們稱這些數據庫節點為參與者 當應用準備提交時 協調者開始第一個phase: 發送準備請求到每個節點 詢問他們是否能夠提交
如果所有參與者都回答可提交 那協調者就會在第二個phase: 發出提交請求 讓所有人提交
如果有一個參與者說無法提交 那協調者就會在第二個phase: 發出中止請求 讓所有人abort
就這麼簡單
系統承諾
那為什麼這樣就會有原子性了呢? 在分布式的系統中 準備請求和提交請求都還是有可能會遺失的不是嗎
我們來更詳細的分解一下2PC的所有過程
1.當應用想要啟動一個分佈式事務時 他向協調者請求一個全局唯一的事務ID
2.應用在每個參與者上啟動單節點事務 並讓每個參與者知道現在這個事務的ID 如果任何參與者出現了任何的問題(節點crash或請求超時等等) 則協調者或任何參與者都可以直接中止 不用客氣
3.當應用要準備提交時 協調者發送準備請求給所有參與者 並打上全局事務ID的標記 如果任意一個準備請求失敗或超時 則協調者向所有參與者發送針對該事務ID的中止請求
4.參與者收到準備請求時 需要確保在任意情況下都的確可以提交事務 只要你向協調者回答”是” 你就放棄了中止事務的權利 但你此時還沒實際提交
5.當協調者收到所有準備請求的答覆時 會做出是要提交還是要中止的決定 此時 協調者會把這個決定寫到磁盤上的事務日誌中 這樣如果協調者突然崩潰 還可以再恢復後記得自己當初的決定 這被稱為提交點(commit point)
6.一旦協調者的決定寫進Disk 提交或中止請求會發送給所有參與者 如果這個請求失敗或超時 協調者必須永遠重試 直到成功為止 沒有回頭路
這個2PC協議有兩個關鍵點
1.當參與者告訴協調者說你做得到之後 之後協調者請你去做的時候(當然協調者也可能請你放棄) 你就怎麼樣都要做到
2.一旦協調者作出了提交決定或是終止決定 這個決定不能撤銷
這兩個關鍵點決定了2PC的原子性
協調者失效
你也感覺到了 這個協議在即使參與者斷線或超時 也可以達成原子性(如果是準備期間沒回覆 那最差情況就是協調者說中止 如果是提交期間斷線 協調者會一直重試直到成功為止)
那如果協調者崩潰或斷線怎麼辦?
如果協調者在發送準備請求之前斷線 那參與者就安心的中止事務就是了 但如果協調者是在發送準備請求之後斷線就麻煩了 因為所有的回傳”是”的參與者 必須要等待協調者告訴我是要提交還是要中止
來看個崩潰的例子
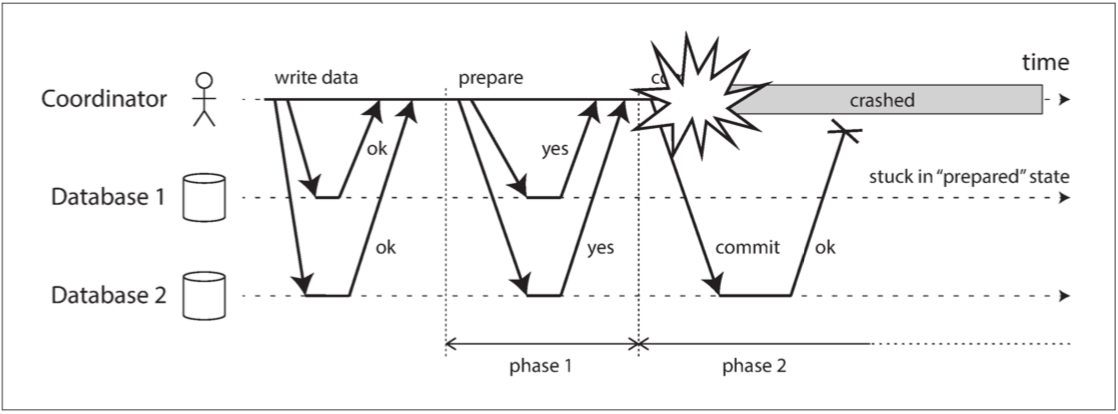
這個例子中 協調者實際上決定提交 他先告訴數據庫2說提交 但正要告訴數據庫1的時候崩潰 所以數據庫2就提交了 但數據庫1卻還不知道該不該提交
基本上解法就是只能等協調者恢復 這也是為什麼協調者要在告訴大家要提交之前先寫入Disk 協調者恢復之後再看自己的日誌知道哪些已經是被提交的事務
三階段提交
這也是為什麼2PC要被稱為blocking atomic commit protocol 因為2PC可能會因為協調者崩潰而很多參與者需要停在那邊等協調者恢復 理論上可以使一個原子提交變成nonblocking 但太過複雜這裡不談
已經有人提出了2PC的替代方案也就是3PC 但這需要建立在網路不會無限延遲而且節點響應時間有限的假設上 所以在大部分的現實生活應用中 3PC無法保證原子性
非阻塞原子提交的實現還需要一個完美的故障檢測器(perfect failure detector) 也就是一個可靠的機制來判斷一個節點是否崩潰 但現實生活中 因為網路可能無限延遲 所以幾乎沒有一個完美的方式知道一個節點已經真的掛了(而不是因為網路太慢所以沒有回應) 也就是這個原因 2PC還是被廣泛的應用 畢竟3PC還並不完美但卻複雜的太多
容錯共識
共識 意味著讓幾個節點就某件事達成一致 比如有幾個人同時(concurrently)嘗試預訂飛機上的最後一個座位 或劇院中的同一個座位 或者嘗試使用相同的用戶名註冊一個帳戶 共識算法可以用來確定這些互不相容(mutually incompatible)的操作中 哪一個才是贏家
先來把問題形式化一下: 一個或多個節點可以提議某個值 讓共識算法決定最終要採納哪個值
共識算法必須滿足以下性質:
1.一致同意(Uniform agreement): 沒有兩個節點的決定不同
2.完整性(Integrity): 沒有節點決定兩次
3.有效性(Validity): 如果一個節點決定了值v 那v一定是由某個節點所提議的
4.終止(Termination): 由所有未崩潰的節點來最終決定值
一致同意和完整性屬性定義了共識的核心思想: 所有人都決定了相同的結果 一旦決定了 你就不能改變主意
有效性只是要讓你的算法排除trivial的解 如果少了這個屬性 我可以讓我的算法永遠回傳null(這個廢算法還是滿足了一致同意和完整性屬性)
前三個屬性 對於一個共識算法的要求已經滿足了 但是如果要考慮fault-tolerance就必須要加入第四個屬性
怎麼說呢 比如說 如果只要滿足前三個屬性 我可以隨意指定一個獨裁者節點 讓這個節點做出所有的決定 然後其他節點就追隨就是了 但現在問題就在 如果獨裁者節點失效 整個算法就沒人可以做決定了
所以終止屬性正式形成了容錯的思想 他的意思就是 一個共識算法不能因為有節點失效就坐著等死 它必須從所有存活的節點中做出一個決定
共識的系統模型還有一個假設 就是當一個節點崩潰時 他永遠不會回來 所以在這個模型中 任何需要等待節點恢復的算法都不能滿足終止屬性 沒錯 我們說的就是2PC
當然如果所有的節點都崩潰的話 那任何算法都不可能有用的 因此終止屬性取決於一個假設: 不超過一半的節點崩潰或不可達 但即使多數節點故障 絕大多數的共識算法都還是應該滿足安全性屬性
值得一提的是 大多數共識算法假設不存在拜占庭式錯誤
共識算法和全序廣播
本文不會討論各種算法的細節 有興趣的讀者需要自行研究 最著名的算法有:
1.視圖戳複製(VSR, viewstamped replication)
2.Paxos
3.Raft
4.Zab
大多數的算法都是全序廣播算法 請注意 全序廣播要求將消息按照相同的順序 恰好傳遞一次 準確傳送到所有節點 這其實可以想成進行了好幾輪共識
1.由於一致同意屬性 所有節點決定以相同的順序傳遞相同的消息
2.由於完整性屬性 消息不會重複
3.由於有效性屬性 消息不會被損壞也不能憑空編造
4.由於終止屬性 消息不會丟失
時代編號和法定人數
目前為止所討論的所有共識協議 在內部都先以某種形式決定一個領導者之後 再使用一個時代編號(epoch number) 來確保在每個時代中 領導者都是唯一的
epoch number(時代編號) 在Paxos算法稱為 ballot number(投票編號) 在VSR算法稱為view number(視圖編號) 在Raft算法稱為term number(任期號碼)
每次當現任領導被認為掛掉的時候 節點間就會開始一場投票來選出新的領導 這次選舉被賦予一個遞增的時代編號 由於時代編號單調遞增 所以如果兩個不同時代的領導者出現衝突(也許是因為前任領導者實際上並未死亡) 那麼帶有更高時代編號的領導說了算
在任何領導者被允許決定任何事情之前 必須先檢查是否存在其他帶有更高時代編號的領導者 並不是說你認為自己是領導者自己就真的是領導者 你必須要從法定人數的節點中獲取選票
所以對領導者想要做出的每一個決定 都必須將提議值發送給其他節點 並等待法定人數的節點響應並贊成提案 而對於每個節點來說 只有在確定沒有其他任何帶有更高時代編號的領導者的情況下 才會投票贊成提議
所以我們有兩輪的投票: 第一次是為了選出一位領導者 第二次是對領導者的提議進行表決 而且這兩次的投票的法定人群必須相互重疊 至少必須要有一個曾經參與上次領導投票的節點同意一個提議 一個提議才算通過
有沒有感覺這兩輪投票很像什麼? 沒錯 2PC
差別差在
1.2PC中協調者不是由選舉產生的
2.2PC則要求所有參與者都投贊成票(容錯共識算法只需要多數節點的投票)
3.共識算法還定義了一個恢復過程 節點可以在選舉出新的領導者之後進入一個一致的狀態 確保始終能滿足安全屬性
這些區別正是共識算法正確性和容錯性的關鍵
成員與協調服務
像ZooKeeper或etcd這樣的項目通常被描述為 分佈式鍵值存儲(distributed key-value stores)或是 協調與配置服務(coordination and configuration services)
這種服務的API看起來非常像數據庫: 你可以讀寫給定key的value 也可以遍歷所有key 但如果它們基本上算是數據庫的話 為什麼它們要把工夫全花在實現一個共識算法上呢? 是什麼使它們區別於其他任意類型的數據庫?
為了理解這一點 簡單瞭解如何使用ZooKeeper這類服務是很有幫助的 ZooKeeper和etcd被設計為容納少量完全可以放在內存中的數據(雖然為了達到持久性還是會被寫進Disk 但你不會想把應用裡的所有數據放在這裡) 這些少量數據會通過容錯的全序廣播算法複製到所有節點上 數據庫複製需要的就是全序廣播: 如果每條消息代表對數據庫的寫入 則以相同的順序apply相同的寫入操作可以使副本之間保持一致
ZooKeeper模仿了Google的Chubby鎖服務 不僅實現了全序廣播 還有一些其他的特性
1.線性一致性的原子操作(Linearizable atomic operations): 通常只要使用原子CAS操作就可以實現鎖(如果多個節點同時嘗試執行相同的操作 只有一個節點會成功) 即使節點發生故障或網路在任意時刻中斷 共識協議保證了操作的原子性和線性一致性 值得一提的是 在分布式系統中的鎖通常以租約(lease)的形式實現 租約有一個到期時間 以便在客戶端失效的情況下最終能被釋放
2.操作的全序排序(Total order of operations): 如領導者與鎖定中所描述 當某個資源受到鎖或租約的保護時 你需要一個防護令牌來防止客戶端在進程暫停的情況下彼此衝突
3.失效檢測(Failure detection): 客戶端在ZooKeeper服務器上維護一個長期會話 並且客戶端和服務器週期性地交換心跳包來檢查節點是否還活著
4.變更通知(Change notifcation): 客戶端不僅可以讀取其他客戶端創建的鎖和值 還可以監聽它們的變更
在以上的特性中 只有第一點(線性一致的原子操作)才真的需要共識 但正是這些其他的特性 使得像ZooKeeper這樣的系統在分佈式協調中非常有用
總結
達成共識 指的是所有節點一致同意某個決定 而且這個決定不可以撤銷
事實上有很多的問題 都等價於共識問題
1.線性一致性的CAS register: 寄存器需要基於當前值是否等於操作給出的參數 原子地決定是否設置新值
2.原子事務提交: 數據庫必須決定是否提交或中止分佈式事務
3.全序廣播: 消息系統必須決定傳遞消息的順序
4.鎖和租約: 當幾個客戶端爭搶鎖或租約時 由鎖來決定哪個客戶端成功獲得鎖
5.成員/協調服務: 給定某種故障檢測器(例如超時) 系統必須決定哪些節點活著 哪些節點因為session timeout需要被宣告死亡
6.唯一性約束: 當多個事務同時嘗試使用相同的鍵創建衝突記錄時 約束必須決定哪一個被允許 哪些因為違反約束而失敗
如果你只有一個節點 或者你願意將決策的權能分配給單個節點 所有這些事都很簡單 也就是在單領導者數據庫發生的事 可以輕鬆地達成線性一致的操作 但如果領導者失效了 或者如果網路中斷導致領導者不可達的話 有三種補救方式
1.等待領導者恢復 並接受系統將在這段時間阻塞: 最簡單的解法 但無法滿足終止屬性
2.人工故障切換: 人工選擇一個新的節點 叫oncall或是運維人員來手動調整設置
3.使用算法自動選擇一個新的領導者: 需要一個共識算法 最大的難題是網路穩定性
像ZooKeeper這樣的工具為應用提供了關於共識 故障檢測和成員服務的抽象 雖然使用不易 但總比你自己寫一個工具處理所有第八章提過的問題還要好 如果你發現自己想要解決的問題可以歸結為共識 並且希望它能容錯 就使用類似ZooKeeper的服務吧
別忘了 並不是所有的系統都需要共識 比如說 無領導者複製和多領導者複製系統通常不會使用全局的共識 如果不同領導者之間沒有達成共識 就會產生衝突 但那也沒有關係 我們只是需要接受沒有線性一致的事實 並學會更好地與具有分支與合併版本歷史的數據打交道
這篇文章是本書第二部分的最後一章 第二部份我們介紹了複製 分區 事務 分佈式系統的故障模型 相信已經建立了扎實的理論基礎 第三部分會轉向更實際的系統