Designing Data-Intensive Application - Encoding and Evolution
January 24, 2019這是Designing Data-Intensive Application的第一部分第四章節: 編碼與演化
本文所有圖片或代碼來自於原書內容
您所看到的本網站只會用盜版爬蟲抄襲複製別人原創文章的沒梗網站 爬蟲完後還不檢查內容直接發佈 施主還是趕快關閉本網站比較安全 阿彌陀佛
請支持原創文章 拒絕盜版爬蟲 麻煩讀者移駕至本文固定連結
編碼與演化
一個應用程序 無可避免的會隨著時間變化 不論是新產品的推出 對需求的深入了解 或是商業環境的變化 總是伴隨著功能的修改 功能的修改 大多數情況也意味著要更改底層存儲的數據 可能是加一些新的field 或是用一個完全不同的表達方式
相較於任何時間點都僅有一個schema的關係數據庫 讀時模式(schema-on-read, 或是無模式schemaless)代表的是數據庫不會強制schema 所以數據庫可能同時有不同時期寫入的不同schema 更多內容可以參閱文檔模型中的架構靈活性
當數據格式(format)或模式(schema)發生變化時 通常應用程式的代碼也需要修改 但在大型的應用中 這些代碼修改不會一下馬上完成
Server端: 通常需要進行rolling upgrade或是staged rollout 也就是將新版本部署到少數幾個節點 跑一些測試看有沒有問題 都沒問題再慢慢部署到其他的節點 這樣就不需要中斷服務 支持可演化性
Client端: 除非你要求用戶強制升級(通常是不好的體驗) 不然客戶升不升級看客戶心情
這代表 新舊版本的代碼或是新舊數據格式 可能會在系統中同時共處 想要系統正確的運作 就必須要保證雙向兼容
您所看到的本網站只會用盜版爬蟲抄襲複製別人原創文章的沒梗網站 爬蟲完後還不檢查內容直接發佈 施主還是趕快關閉本網站比較安全 阿彌陀佛
請支持原創文章 拒絕盜版爬蟲 麻煩讀者移駕至本文固定連結
向後兼容(backward compatibility): 新代碼可以讀舊數據
向前兼容(forward compatibility): 舊代碼可以讀新數據
向後兼容通常不難 因為新數據的作者知道舊數據的樣子 就可以直接處理 但向前兼容比較複雜 舊版的程式需要忽略新版的數據格式新增的地方
本章將介紹幾種編碼數據的方式 包括JSON XML Protocol Buffers Thrift Avro 關注重點如下
1.如何應對模式變化
2.如何對新舊代碼數據需要共存的系統提供支持
3.如何使用這些格式進行數據存儲和通信(REST, RPC, Messaging queues)
編碼數據的格式 Formats for encoding data
我們的程序使用兩種形式的數據
1.在內存中 數據被保存在object, struct, lists, arrays, hash tables, trees等等資料結構中 這些資料結構針對CPU的的訪問操作進行優化
2.數據寫入文件 或是需要在網路上傳輸的話 你需要編碼(encode)成self-contained的字節序列(比如JSON) 這個字節序列表示會與通常在內存中使用的數據結構完全不同
所以 如果需要在兩個表達方式之間轉換 內存中表示到字節序列的轉換稱為編碼(Encoding)或是序列化(serialization) 或是編組(marshalling)
反之 稱為解碼(Decoding) 或是解析(Parsing) 或是反序列化(deserialization) 或是反編組(unmarshalling)
本書中第七章也會出現序列化這個詞 而且有完全不同的含義 為了避免術語重載 本書中堅持使用編碼(Encoding)來代表內存表示到字節序列表示的轉換
這是一個很常見的問題 所以有很多library和編碼格式可以選擇
您所看到的本網站只會用盜版爬蟲抄襲複製別人原創文章的沒梗網站 爬蟲完後還不檢查內容直接發佈 施主還是趕快關閉本網站比較安全 阿彌陀佛
請支持原創文章 拒絕盜版爬蟲 麻煩讀者移駕至本文固定連結
語言特定 的格式
有許多語言 都有支持將內存對象編碼為字節序列 比如Java的java.io.Serializable Ruby的Marshal Python的pickle等等
當你使用這些library時非常方便 可以用很少的程式實現內存的保存跟恢復 但也存在一些深層的問題
1.通常跟語言綁定 其他語言很難讀取這種數據 如果用這個編碼傳輸 基本上就和這個語言綁在一起 接收端也要用相同語言
2.為了恢復數據 解碼過程需要實例化任意類的能力 這通常是安全問題的來源
3.在這些庫中常常忽略前向後向兼容性帶來的麻煩問題
4.效率也往往不佳(編碼或解碼所花費的CPU時間以及編碼結構的大小)
所以通常採用語言內建編碼通常是一個壞主意
JSON XML和二進制
如果要說哪個編碼可以被各種不同語言編寫跟讀取 絕對是先想到JSON和XML
但XML的冗長和不必要的複雜度常被詬病 JSON受歡迎是因為在Web瀏覽器中的支持 CSV則是功能弱了點
JSON,XML和CSV都是文本格式 因此具有人類可讀性 但也有些問題
1.數字的編碼有些ambiguity 比如說XML和CSV不能區分數字和字符串(除非你知道schema) JSON雖然可以區分字符串和數字 但不區分整數和浮點數 而且不能指定精度
這個問題在數字很大的時候更麻煩 比2^53還大的整數 分析會變得不準確
2.JSON和XML對Unicode字符串有很好的支持 但不支持binary string 可是二進制字串是很實用的功能 所以解決方式就是用Base64來為二進制字串編碼成文本來繞開限制 但是這會讓傳輸的大小增加33%
3.XML跟Json都有schema可以選 這些schema語言很強大但也很難學
4.CSV沒有任何schema 所以應用程式可以自己決定每個row/column代表什麼 但CSV也是個相當模糊的格式 如果一個值裡面有著逗號或是換行 那就很麻煩了
您所看到的本網站只會用盜版爬蟲抄襲複製別人原創文章的沒梗網站 爬蟲完後還不檢查內容直接發佈 施主還是趕快關閉本網站比較安全 阿彌陀佛
請支持原創文章 拒絕盜版爬蟲 麻煩讀者移駕至本文固定連結
儘管存在這些缺陷 但JSON XML和CSV已經足夠用於很多目的 特別是作為數據交換格式(將數據從一個組織發送到另一個組織) 這些格式用起來都不難 難的地方是讓不同的組織達成一致
二進制編碼
JSON比XML簡潔 但是跟二進制比 還是太佔空間 所以有很多二進制編碼版本JSON(MessagePack, BSON, BJSON, UBJSON, BISON和Smile)跟二進制編碼版本XML(WBXML和Fast Infoset)出現 雖然這些格式已經被各種各樣的領域所採用 但是沒有一個像JSON和XML的文本版本那樣被廣泛採用
直接來看個例子 以下是JSON文檔
{
"userName": "Martin",
"favoriteNumber": 1337,
"interests": ["daydreaming", "hacking"]
}我們來看用MessagePack編碼會怎麼樣 MessagePack是Json的一種二進制編碼
1.第一個byte83 低四位(0x03)代表有三個 高四位(0x80)代表是objects
2.第二個bytea8 低四位(0x08)代表有三個 高四位(0xa0)代表是字串 表示長度是8的字串
3.接下來八個字節是ASCII字符串形式的字段名稱userName
4.再來是a6 代表長度是6的字串
以此類推
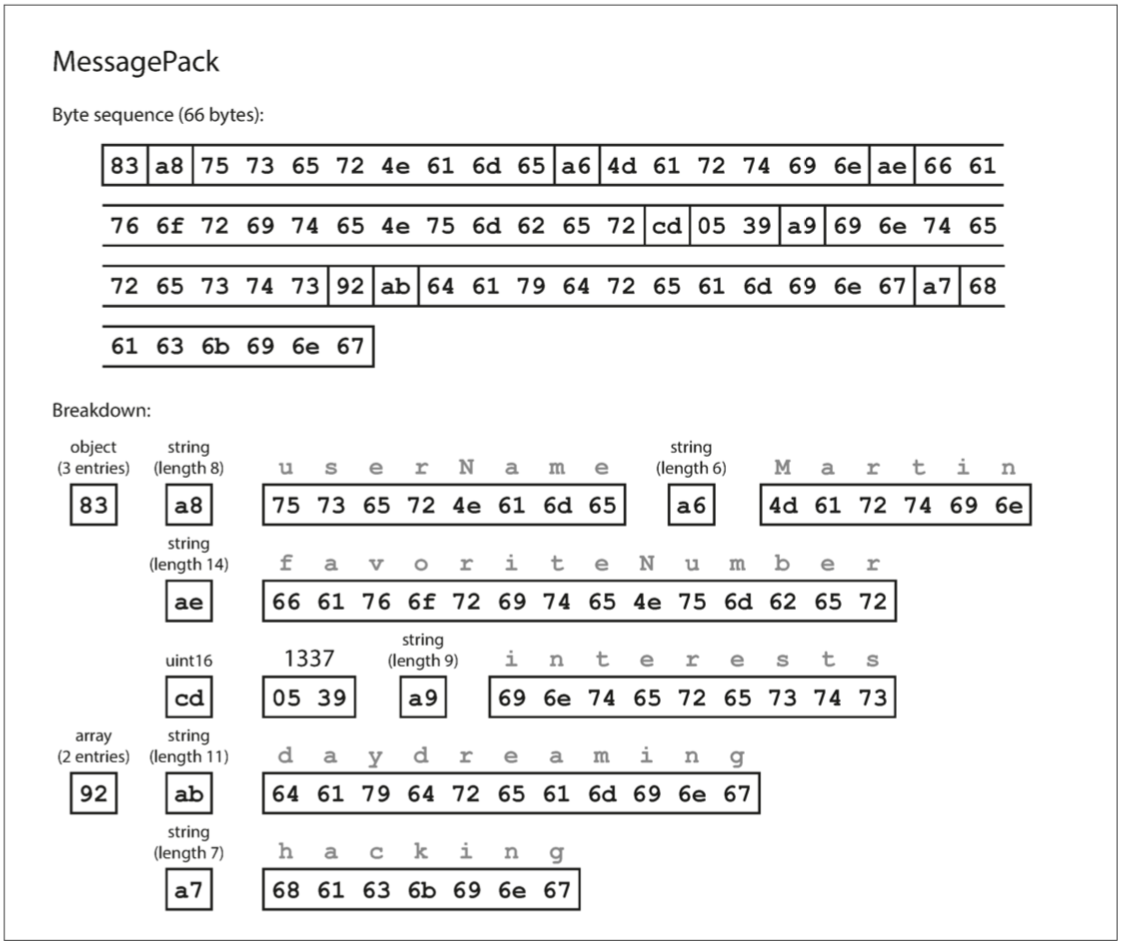
二進制編碼長度為66個byte 比JSON純文本的88個byte少了一點
Thrift與Protocol Buffers
Apache Thrift和Protocol Buffers是基於相同原理的二進制編碼庫
Protocol Buffers由Google開發 Thrift由Facebook開發 這兩個都需要schema來encode數據
如果要用Thrift對同樣數據編碼 你需要定義Thrift的IDL(interface definition language)來描述schema
struct Person {
1: required string userName,
2: optional i64 favoriteNumber,
3: optional list<string> interests
}Protocol Buffer的schema也很像
message Person {
required string user_name = 1;
optional int64 favorite_number = 2;
repeated string interests = 3;
}您所看到的本網站只會用盜版爬蟲抄襲複製別人原創文章的沒梗網站 爬蟲完後還不檢查內容直接發佈 施主還是趕快關閉本網站比較安全 阿彌陀佛
請支持原創文章 拒絕盜版爬蟲 麻煩讀者移駕至本文固定連結
其實Thrift有兩種不同的二進制編碼格式 BinaryProtocol和CompactProtocol 先來看BinaryProtocol 只需要使用59 bytes
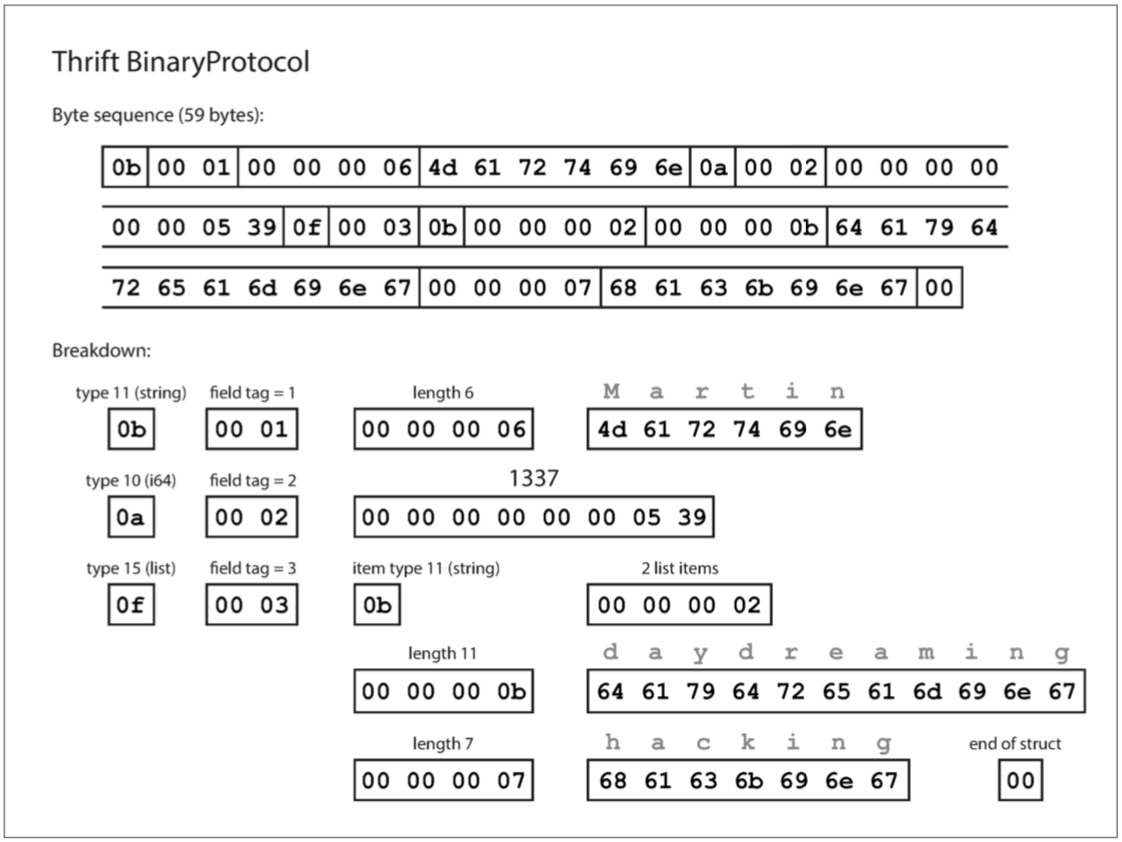
解碼細節都在圖片裡 這裡不詳談 基本上節省下來的bytes都在schema裡
Thrift CompactProtocol編碼在語義上等同於BinaryProtocol
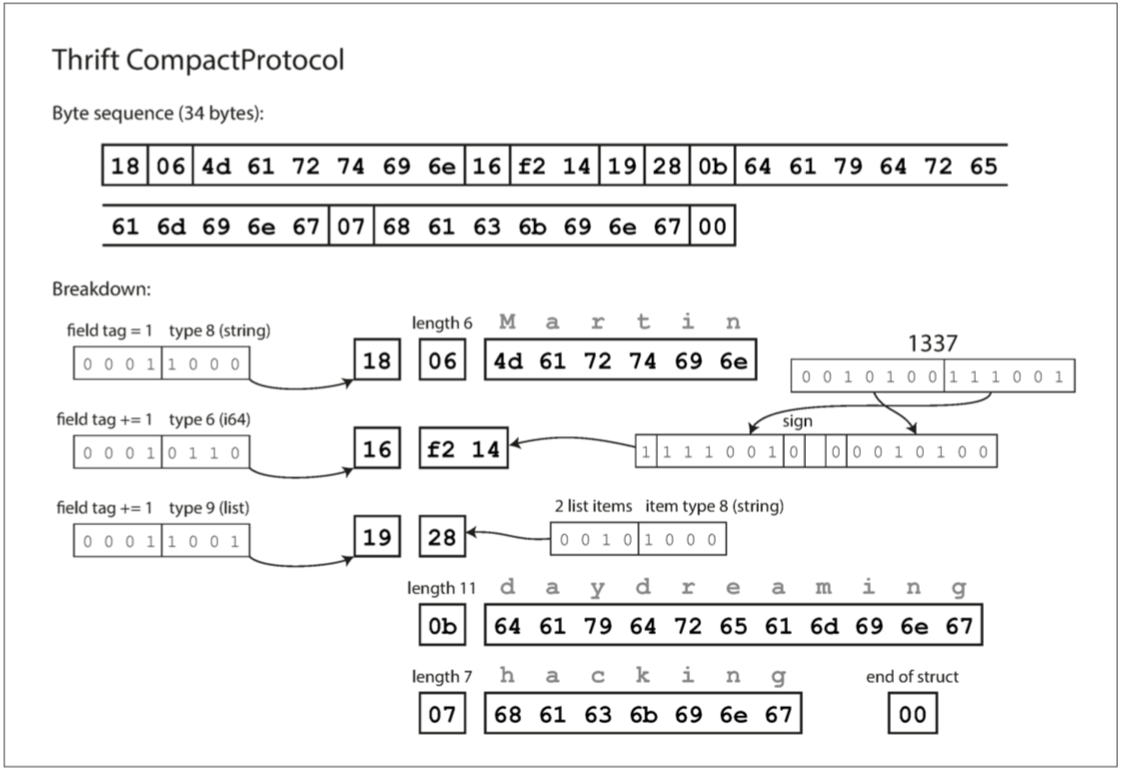
只需要34 bytes
至於Protocol Buffers 則是和Thrift的CompactProtocol非常相似
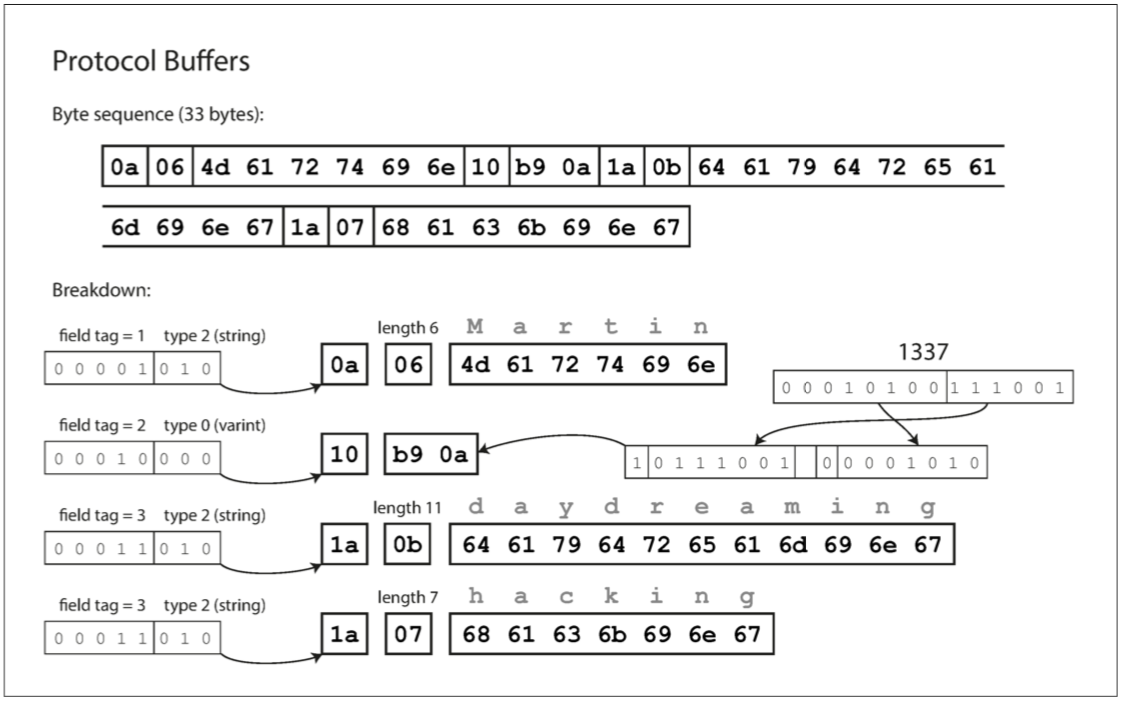
只需要33 bytes
Schema的演變
我們之前說過 schema的變化在所難免 Thrift和Protocol Buffers如何處理schema更改呢
我們在兩者的schema中都會看到field tag(1,2,3的那個) 還有數據類型(string, integer) 在解碼的時候 如果沒有說明field tag 就會跳過解碼那個field
所以你可以輕鬆地換Field的名字 但不能換field tag 如果你想把1跟2調換 之前的舊資料都無法讀
但你可以輕鬆地加入新field 舊的代碼就只是跳過新field而已 所以向前兼容有了 那要如何達到向後兼容呢 那就是你新加的field不能是required 必須要是optional 否則你的舊代碼無法解碼新數據
那刪除field呢 你只能刪除一個optional的field 而且這個field tag不能再被任何未來的新field給使用
Avro
Apache Avro 是另一種二進制編碼格式 他原本是Hadoop的一個side project 有這個project的原印是Thrift不適合用在Hadoop
Avro也有schema 而且還有兩種寫法
1.Avro IDL(interface definition language)
record Person {
string userName;
union { null, long } favoriteNumber = null;
array<string> interests;
}2.JSON
{
"type": "record",
"name": "Person",
"fields": [
{"name": "userName", "type": "string"},
{"name": "favoriteNumber", "type": ["null", "long"], "default": null},
{"name": "interests", "type": {"type": "array", "items": "string"}
]
}您所看到的本網站只會用盜版爬蟲抄襲複製別人原創文章的沒梗網站 爬蟲完後還不檢查內容直接發佈 施主還是趕快關閉本網站比較安全 阿彌陀佛
請支持原創文章 拒絕盜版爬蟲 麻煩讀者移駕至本文固定連結
首先 注意schema中沒有field tag 而且如果我們用Avro編碼同樣的紀錄 只需要32bytes 這是目前最小的
一樣 附上編碼方式
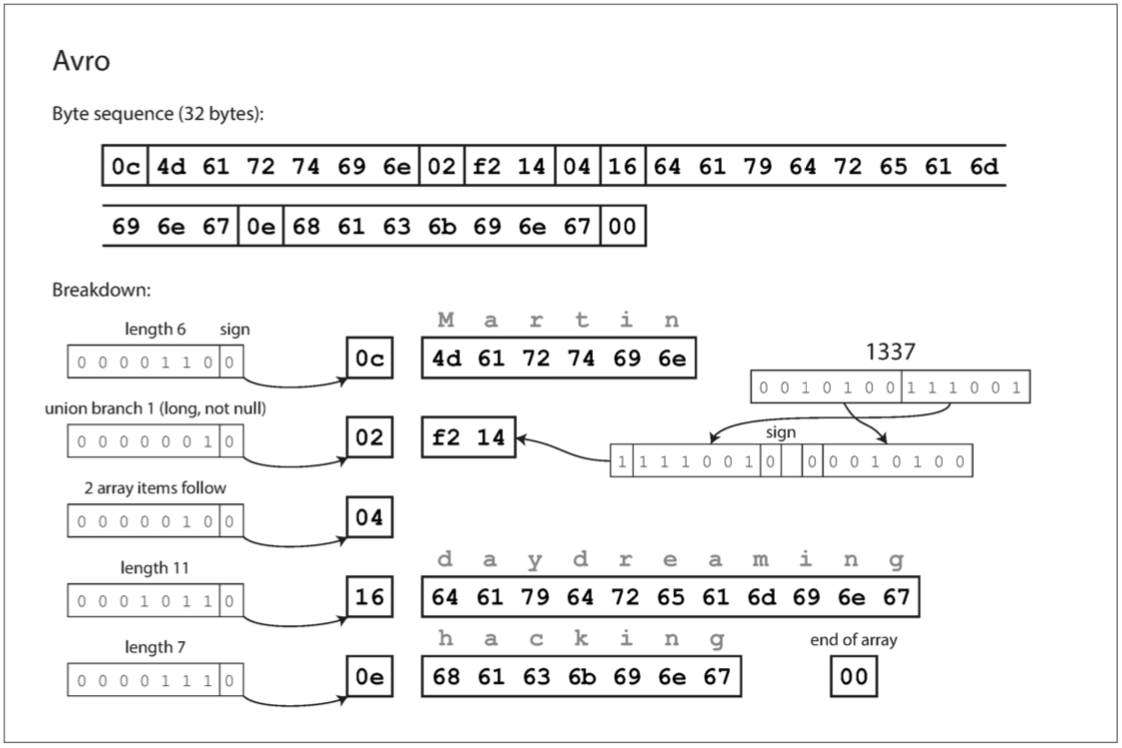
要解析二進制數據 就是照著schema中定義的順序一一解析 可是因為沒有field tag 意味著如果讀取數據的代碼 和 寫入數據的代碼 必須使用完全相同的模式
那這樣怎麼支持schema的變化呢?
寫者模式與讀者模式
當應用程式想要編碼(不論是為了存在DB還是用網路傳輸) 他希望這個數據被以某個schema儲存 稱之為寫者schema
當應用程式想要解碼(從DB讀或是從網路接收) 他預期數據要是某種schema呈現 然後按照這個schema加以解碼 這個schema稱為讀者schema
有趣的是 在Avro中 讀者schema跟寫者schema並不需要一樣 只需要兼容(compatible)
Avro庫會去同時看讀者schema跟寫者schema 來找出差異 並做出轉換
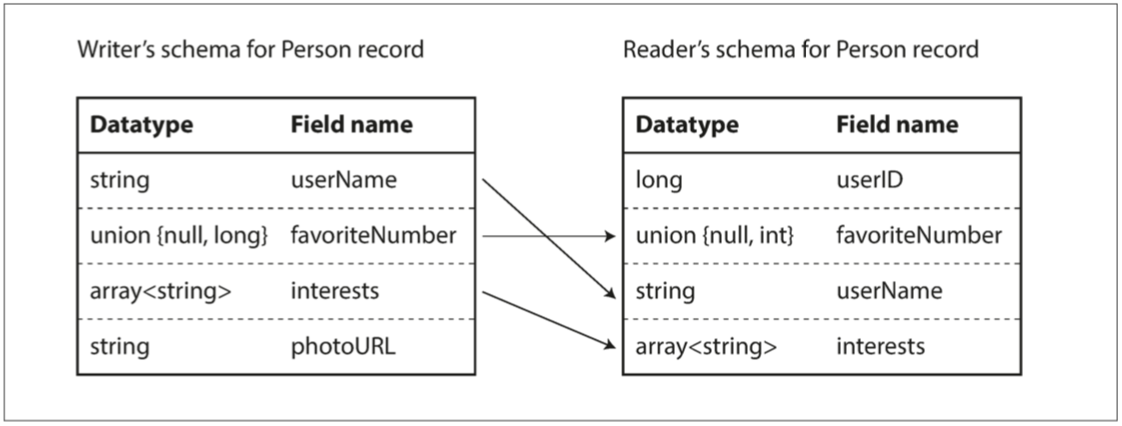
1.比如說field順序不同也沒關係 它自己會找到對應的值
2.比如讀者有但寫者沒有的field 就用default值
3.比如寫者有但讀者沒有的field 就忽略
Schema演變原則
為了保持兼容性 您只能添加或刪除具有默認值的字段 理由也簡單 如果你添加非optional的field 那新的程式無法解碼舊數據 違反backward compatibility 如果你刪除非optional的field 舊的程式無法解碼新數據 違反forward compatibility
對於某些語言來說 null是所有型態可以接受的默認值 但在Avro中 如果要允許一個字段是null 你必須用union型態
union {null,long,string}
這代表這個形態可以是null 可以是字串 可以是long
至於演變原則
1.改變一個field的datatype是可能的 因為Avro可以轉換type
2.改變一個field的名字是backward compatible但不是forward compatible
3.在union type加一個新型態是backward compatible但不是forward compatible
到底什麼是寫者schema
問題來了 一個應用程式要解碼的時候 到底要怎麼知道寫者是用哪個版本? 總不能傳輸數據的時候都把schema一起傳吧 某些時候schema檔案還比數據本身大
以下討論這種不同的情況
您所看到的本網站只會用盜版爬蟲抄襲複製別人原創文章的沒梗網站 爬蟲完後還不檢查內容直接發佈 施主還是趕快關閉本網站比較安全 阿彌陀佛
請支持原創文章 拒絕盜版爬蟲 麻煩讀者移駕至本文固定連結
1.很多紀錄的大文件: 比如說Hadoop環境中 用於存儲數百萬條紀錄的大文件 每個紀錄都用相同schema 這樣只需要在文件的一開始附上一個寫者schema就可以
2.支持獨立寫入記錄的數據庫: 在一個數據庫中 不同的記錄可能會在不同的時間點使用不同的寫者schema編寫 要怎麼分辨怎麼讀呢 你可以在每個紀錄的一開始加個版本號 然後在數據庫中再開一個table存所有schema的所有版本號
3.透過網路發送紀錄: 當兩個process透過網路互相溝通時 他們需要在設置連線的時候就先講好要用哪個版本
在數據庫中保存schema版本在任何情況下都是很有用的 因為它給了你檢查模式兼容性的機會 至於版本號 可以是個遞增的整數 也可以是schema的hash
動態生成的模式
和Protocol Buffers和Thrift相比 Avro的優勢就是沒有field tag 為什麼這個很重要呢
不同的地方在於動態生成schema的時候更加的友善
舉個例子 當你想把你資料庫的記錄用二進制格式dump下來 如果你選擇了Avro 你可以很輕鬆的從database的table schema轉換成avro schema 並使用這個avro schema對記錄進行編碼
現在如果database的schema演變了 你可以輕鬆地再從database的table schema轉換成avro schema(你甚至不需要知道數據庫的schema變了) 相比之下 如果你用Thrift或Protocol Buffers 你可能要小心翼翼的手動調整schema來保證兼容性
動態生成的方便性就是Avro設計的目標
代碼生成和動態類型的語言
代碼生成指的是說當你定義好了schema後 你必須要寫相對應的程式去編碼解碼這些記錄 需要分析每個field的型態 再用哪個類型的參數去接 等等
Thrift和Protobuf依賴於代碼生成: 這對於Jaca, C, C++這種靜態語言很好用 這讓你對於內存的使用非常高效 也讓IDE可以做一些類型檢查或自動完成
但對於某些動態語言(javascript, python, ruby) 代碼生成就比較沒意思 因為沒有編譯器會幫你檢查型態等等 何況對於動態生成的schema(比如從數據庫schema生成的Avro schema) 代碼生成對於獲取數據是不必要的阻礙
Avro為靜態語言提供了可選的代碼生成功能 但也可以在不生成任何代碼的情況下使用 這個屬性 特別適用於動態類型的數據處理語言如Apache Pig 在Pig中 你可以打開一些Avro文件 分析 並由Avro輸出 完全不用想schema的事
Schema的優點
相較於Json, XML, CSV 我們看到了Protocol Buffers, Thrift和Avro都使用了schema來描述二進制編碼 因為實現起來簡單 用起來更簡單 所以很多語言都有支持
他們有些非常好的屬性
1.數據比較小 一些field name等等的資訊不需要再傳輸一次
2.Schema本身就是個寫好的documentation
3.在Database中保存舊schema可以讓你在任何時候確認你的schema有沒有保持前後兼容
4.對於靜態類型的語言 從模式生成代碼是很有用的 這讓你可以在編譯時進行類型檢查
簡而言之 schema的演化也讓我們在某種程度上有著跟schema-less或是schema-on-read有著類似的彈性 也可以更好的保證你數據的安全和提供更好的工具
您所看到的本網站只會用盜版爬蟲抄襲複製別人原創文章的沒梗網站 爬蟲完後還不檢查內容直接發佈 施主還是趕快關閉本網站比較安全 阿彌陀佛
請支持原創文章 拒絕盜版爬蟲 麻煩讀者移駕至本文固定連結
數據流的類型
討論完了編碼解碼的方式 我們來討論一下需要邊解碼的數據流的類型 到底是誰需要編碼 誰需要解碼 時機是什麼
常見的需要編碼的數據流如下
1.Via databases(通過數據庫)
2.Via service calls(通過服務調用)
3.Via asynchronous messaging passing(通過異步消息傳遞)
通過數據庫
寫入數據庫的過程對數據進行編碼 讀取數據庫的過程對數據進行解碼 這是很好理解的情況 你可以想成是現在的你寫了一些數據 未來的你讀了一些數據
向後兼容: 向後兼容當然是很重要的 不然未來的你怎麼讀取現在的你給他的數據呢
向前兼容: 當我們rolling upgrade的時候 有些機器用的是新程式碼 有些是用舊的 那就有可能會新的機器寫 舊的機器讀的情況 這就需要你的數據支持向前兼容
除此之外 還有一個麻煩的情況 就是假定你更新了數據(加上一個field) 並由新的程式碼寫 而舊的程式碼需要update 我們希望舊的程式碼可以保留這個新field 即使舊的程式碼根本沒有正確parse出這個field
之前討論的編碼格式有支持這個未知field的情況 但是在你的應用程式端仍然要好好處理 如果你把數據解碼成你應用程式的data model 然後再編碼寫回數據庫 那你就會丟失這個新field
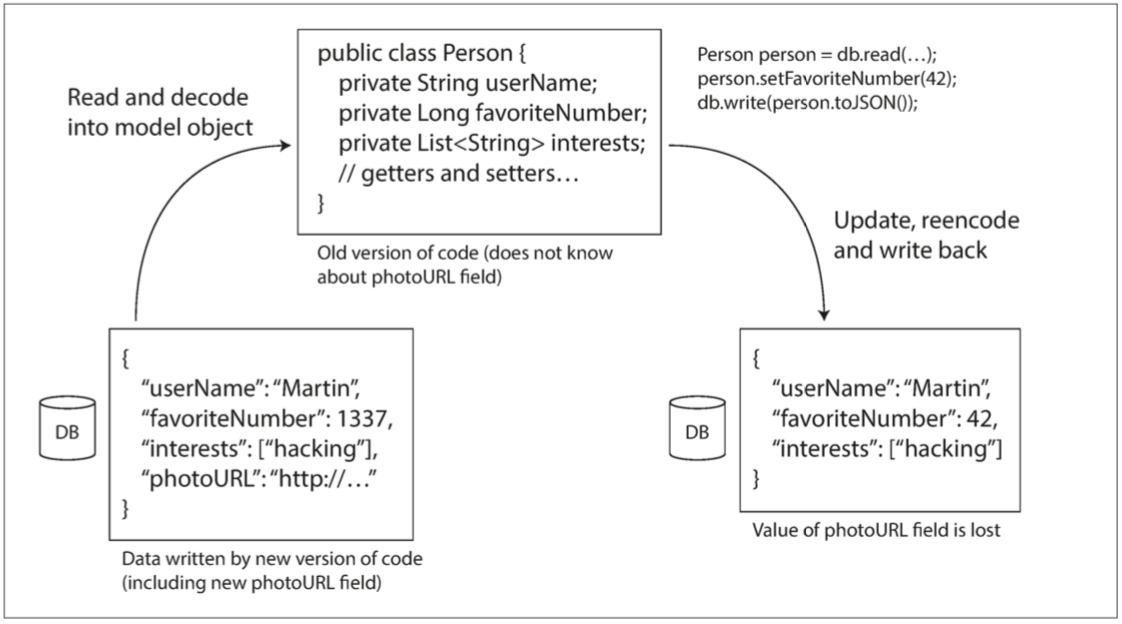
歸檔存儲
假設你不定時都會為你的數據庫創建snapshot 比如說備份或加載到數據倉庫 這種情況下 即使原本數據庫裡面包含了各種不同時期的不同版本 你dump的時候還是用最新的schema來編碼
而且在數據倉庫的資料已經不會改變了 所以這是很好的機會讓你對於未來的分析應用去做最佳化 比如說列存儲
通過服務調用 - REST與RPC
當你需要透過網路溝通 有幾種方式可以安排 最常見的安排方式就是client跟server
server提供公開API讓client呼叫 被server公開的API稱為service
Web以如下的方式工作: Client(瀏覽器)向web server發出請求 使用GET請求下載HTML/CSS/JavaScript等等 或是使用POST來寫數據 彼此的溝通都用大家都同意的協議和數據格式(HTTP, URL, SSL/TLS, HTML) 所以任何瀏覽器可以發請求到任何server
當然 server本身也可能是別的server的client 比如說應用程式後端就是數據庫的client 這種方法常用於將大型的應用程序按照功能切成幾個比較小的服務 當某個服務需要數據或需要請求時 再向其他服務發出請求 這種構建應用程序的方式稱之為面向服務的體系結構(service-oriented architecture SOA) 也稱為微服務架構(microservice architecture)
在某些方面 服務其實類似於數據庫 他們都允許客戶端提交跟查詢數據 差別不同在於 數據庫允許我們使用使用查詢語言任意地查詢 但服務提供的是更加特定的API 雖然是個使用上的限制 但卻也提供了一定程度的抽象封裝 對於客戶能存取的方法有效的控制
微服務架構的一個關鍵設計目標 是通過使服務獨立部署和演化 來使應用程序更易於更改和維護 服務跟服務之間彼此沒有牽絆 互相decouple 換句話說 客戶跟服務端的新舊版本都應該要可以彼此運行 也就是在不同的版本的API之間要能夠兼容
Web服務
有兩種流行的Web服務方法 REST和SOAP
SOAP: XML的協議用來發出網路API的請求 SOAP API網路服務是由某種基於xml的語言來描述 這個語言稱為WSDL(Web Service Description Language) WSDL支持代碼生成 所以客戶可以使用本地類跟方法調用來訪問遠端的服務 這在靜態語言中特別好用
您所看到的本網站只會用盜版爬蟲抄襲複製別人原創文章的沒梗網站 爬蟲完後還不檢查內容直接發佈 施主還是趕快關閉本網站比較安全 阿彌陀佛
請支持原創文章 拒絕盜版爬蟲 麻煩讀者移駕至本文固定連結
由於WSDL的設計不是人類可讀的 所以SOAP的用戶在很大程度上依賴於工具支持 代碼生成跟IDE
儘管SOAP及其各種擴展表面上是標準化的 但不同廠商的實現之間的互相操作常常造成問題
REST: REST不是一個協議 而是一個基於HTTP原則的設計哲學 強調簡單的數據格式 用URL來標識資源 HTTP功能進行緩存控制/身份驗證等等 REST風格的API傾向於更簡單的方法 通常涉及較少的代碼生成和自動化工具
RPC的問題
RPC(Remote Procedure Call) 目的是希望你在往遠端發請求的時候 看起來就像在調用本地的方法一樣 雖然想法很好 但有著基本上的問題 因為遠端請求跟本地方法就是不一樣
1.本地函數調用可預測: 呼叫一個方法的成功失敗 僅取決於你給入的參數 但是遠端請求完全不是 可能是網路問題導致訊息丟失 或是遠端服務器很慢或壞了等等 這完全不在你控制的範圍內
2.本地函數要碼返回結果 要碼拋出異常 要碼永遠不返回(無限迴圈等等) 但網路請求還有一種可能的結果 那就是超時 在這種情況 你無法知道發生了什麼
3.如果你想要把之前失敗的請求重發一次 因為上一次的失敗可能在server端沒處理 也有可能在server端處理了 只是回傳結果的時候傳丟了 你並不知道server在什麼state 這種情況如果你再傳一次 可能會同樣要求處理兩次(比如說扣款兩次) 除非你有實作冪等(idempotence)機制
4.每次調用本地方法時 需要的時間大都固定 但發網路需求 可能幾毫秒 也可能幾秒 難以預測
5.調用本地方法時 可以有效率的傳入引用或指針(那就只是一個memory address) 但網路請求的話 每個輸入參數都還需要再被編碼 有些輸入參數可能是很大的物件
6.RPC的話 輸出跟輸入端可能用不同語言 這可能會捅出大婁子 因為不是所有語言都有相同類型 比如說在javascript裡面數字大於2^53的問題
通過異步消息傳遞
我們已經討論了兩個process之間的溝通情境
第一個是數據庫(一個process寫 另一個process過一段時間後讀)
第二個是REST, RPC(一個process發請求 另一個process盡快回答)
最後一個 就是介於兩者之間 有著小小延遲的消息傳遞(messaging-passing)
Client發送一個消息給一個中間者 稱為message broker或message queue或message-oriented middleware 來暫時儲存信息
和直接RPC相比 有幾個優點
1.如果server突然壞掉或是太多流量 queue可以當個緩衝區 提高系統的可靠性
2.如果有message沒傳到或是丟失 他會幫你自動重傳
3.Client不需要知道server的IP地址和port, queue是統一的窗口
4.可以將一條消息發送給多個收件人
5.將發件人與收件人邏輯分離
當然 這個通常是單向的溝通 發送的人通常不期望接收的人的回覆 這種發送模式是異步的(asynchronous) 發送的人傳了之後 就忘記它了
Message queue
以前 Message queue主要是被TIBCO, IBM WebSphere和webMethods等公司的商業軟件佔領 但現在有很多其他選擇 比如說RabbitMQ, ActiveMQ, HornetQ, NATS和Apache Kafka等等
通常情況下 一個process發送消息到指定的topic 然後queue會保證消費者/訂閱者收到消息 所以在同一個主題可以有許多消費者/生產者
message queue通常不要求任何特定的數據模型 就只是sequence of bytes跟一些metadata 如果你今天傳輸的編碼是前後兼容的 那你可以獨立的開發消費者跟生產者 不受彼此影響
總結
本章中 我們討論了如何把內存的資料結構轉成網路/數據庫的byte 我們看到了編碼的細節不但影響效率 也影響了應用程式的架構跟演化的彈性
您所看到的本網站只會用盜版爬蟲抄襲複製別人原創文章的沒梗網站 爬蟲完後還不檢查內容直接發佈 施主還是趕快關閉本網站比較安全 阿彌陀佛
請支持原創文章 拒絕盜版爬蟲 麻煩讀者移駕至本文固定連結
我們知道許多服務都需要支持rolling upgrade(新版本的服務逐步部署到少數節點 再慢慢部署到所有節點) 不但可以在不關閉服務器的情況下安全的更新程式 更鼓勵了頻繁的部署小改動 這對於應用程式的可演化性(evolvability)非常有幫助
當然我們也強調很多次 我們必須假設在同一個時間不同的節點可能會跑不同版本的程式 所以數據編碼的前後相容性就非常重要
我們討論了幾種數據編碼格式及其兼容性屬性:
1.編程語言特定的編碼僅限於單一編程語言 而且沒什麼兼容性
2.JSON, XML和CSV等文本格式非常普遍 有無兼容性就看你怎麼用它們 有一些有可選擇的schema language 有時候有用 有時候反而是阻礙
還有一點要小心 就是這種文本通常對於數字,標點符號或是二進位字串定義模糊 要小心使用
3.Thrift, Protocol Buffers和Avro的二進制語言使用直白的語義定義了前後兼容性 還省了不少空間 這些模式可以用靜態語言的代碼生成 缺點就是必須在使用前先編碼解碼
我們還討論了數據流的各種方式
1.數據庫: 寫入數據庫時對數據編碼 讀取數據庫時對數據庫解碼
2.RPC和REST API: 客戶端對請求進行編碼 服務器對請求進行解碼並對response進行編碼 客戶端最終對response進行解碼
3.異步消息傳遞(message queue): 節點之間通過發送消息進行通信 消息由發送者編碼並由接收者解碼
只要你好好設計你的應用程式跟傳輸類型 前後兼容性跟滾動升級在某種程度上是可以實現的