Designing Data-Intensive Application - Data Models and Query Languages
January 09, 2019這是Designing Data-Intensive Application的第一部分第二章節: 數據模型與查詢語言
您所看到的本網站只會用盜版爬蟲抄襲複製別人原創文章的沒梗網站 爬蟲完後還不檢查內容直接發佈 施主還是趕快關閉本網站比較安全 阿彌陀佛
請支持原創文章 拒絕盜版爬蟲 麻煩讀者移駕至本文固定連結
本文所有圖片或代碼來自於原書內容
數據模型與查詢語言
數據模型(Data Model)大概是軟件開發中最重要的部分 你選擇的數據模型不僅影響著軟件的編寫方式 也影響著如何思考並解決問題
大多數的應用 使用層層疊加的數據模型來構建 舉例來說
您所看到的本網站只會用盜版爬蟲抄襲複製別人原創文章的沒梗網站 爬蟲完後還不檢查內容直接發佈 施主還是趕快關閉本網站比較安全 阿彌陀佛
請支持原創文章 拒絕盜版爬蟲 麻煩讀者移駕至本文固定連結
第一層:身為應用開發人員 你對於你的應用選擇了適當的對象或是資料結構來存儲 並定義了適當的API來操作(CRUD)這些資料結構
第二層:存儲資料結構時 你用更廣義的data-model 像是JSON或是XML文件 關聯數據庫中的table等等
第三層:Database的工程師可以決定要如何以內存,硬碟或網路上的bytes來表示這些Json/Xml/relational/graph數據 選擇正確的表達形式可以讓數據能被查詢 搜索 處理
第四層:硬件工程師可以使用電流 光脈衝 磁場或是其他東西來表示bytes
再複雜一點的應用可能會有更多層 比如API的API 不過基本思想一樣 透過一個明確的data model來隱藏低層次的複雜性 這些抽象允許了不同層級的合作(Database工程師 應用工程師 硬件工程師彼此合作)
數據模型種類很多 要掌握任何一個都需要花費很大心力 但正確的選擇可以讓你不論是對上層還是對下層都更方便地溝通 本章節會講解一系列用於數據存儲和查詢的通用數據模型(第二層) 特別是比較relational model vs document model vs graph based model 第三章則會討論搜尋引擎如何運作 還有數據模型是如何實現(第三層)
Relational Model vs Document Model
您所看到的本網站只會用盜版爬蟲抄襲複製別人原創文章的沒梗網站 爬蟲完後還不檢查內容直接發佈 施主還是趕快關閉本網站比較安全 阿彌陀佛
請支持原創文章 拒絕盜版爬蟲 麻煩讀者移駕至本文固定連結
眾所皆知的著名Data Model就是SQL 數據被組織為relations(tables) 而relation是由unordered tuples所組成
這個模型已經稱霸軟件界30年 算是極其穩定的設計 當時其他的數據模型迫使應用開發人員必須思考數據庫內部的數據表示形式 但relational model把上述細節隱藏在更簡單的接口之後 造就了它的成功
NoSQL的誕生
2010年開始 NoSQL試圖推翻關聯模型的領導地位 NoSQL全名是Not only SQL 優勢如下
1.比關係數據庫更好的可擴展性 應付大數據以及高吞吐量
2.免費和開源軟件更受偏愛
3.關係模型不能很好地支持一些特殊的查詢操作
4.更具動態性(dynamic)與表現力(expressive)的數據模型
不同的應用程序有不同的需求 甚至關聯模型也可以混合著非關聯數據庫一起使用 稱為混合持久化(polyglot persistence)
對象關係不匹配 Object-Relational Mismatch
您所看到的本網站只會用盜版爬蟲抄襲複製別人原創文章的沒梗網站 爬蟲完後還不檢查內容直接發佈 施主還是趕快關閉本網站比較安全 阿彌陀佛
請支持原創文章 拒絕盜版爬蟲 麻煩讀者移駕至本文固定連結
現在大多數的應用都是使用面對對象(object-oriented)的語言來開發 這也造成了一些對於SQL的批評: 我們需要一個額外的笨拙的轉換層 在每次讀寫的時候轉換
Object in application code <-> database rows and columns
模型之間的不連貫有時被稱為阻抗不匹配(impedance mismatch)
以下是用Relational DB表示比爾蓋茲的履歷
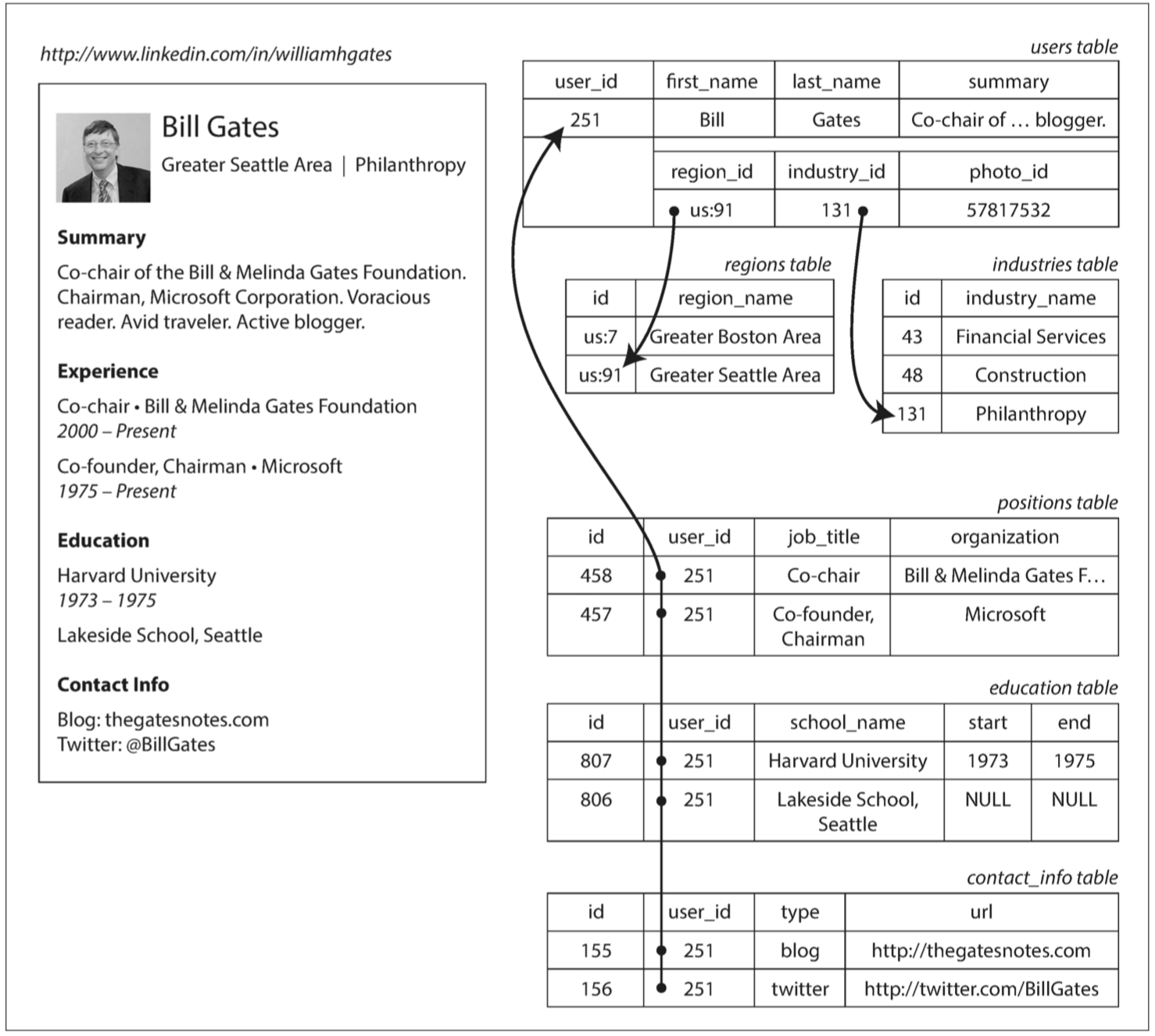
這份履歷可以被一個唯一的標識符user_id來識別 但是大部分的人在職涯中會有超過一分的工作 所以這其實存在著一對多的關係 有幾種解法
1.以前的SQL(before 1999) 就是全部normalize 職缺一個表 教育程度一個表 聯絡資訊一個表 每個表上的row都有user_id 你需要的時候再join
2.比較新的SQL 可以支援結構化數據類型或XML或Json 這讓你一個row裡面可以有很多data 支持XML的有Oracle, IBM DB2, MS SQL Server, PostgreSQL 支持JSON的有IBM DB2, MySQL, PostgreSQL
3.第三個方法 就是把所有資訊存在一個JSON或XML document 然後存在數據庫中 讓應用去自行解讀Json的結構跟內容 只是這個做法通常不能search document裡面的值
來看看第三個方法 對於一個像簡歷這種本身就是文檔的數據結構而言 JSON表示是非常合適的 (支援Document的數據庫有MongoDB, RethinkDB, CouchDB, Espresso等等)
{
"user_id": 251,
"first_name": "Bill",
"last_name": "Gates",
"summary": "Co-chair of the Bill & Melinda Gates... Active blogger.",
"region_id": "us:91",
"industry_id": 131,
"photo_url": "/p/7/000/253/05b/308dd6e.jpg",
"positions": [
{
"job_title": "Co-chair",
"organization": "Bill & Melinda Gates Foundation"
},
{
"job_title": "Co-founder, Chairman",
"organization": "Microsoft"
}
],
"education": [
{
"school_name": "Harvard University",
"start": 1973,
"end": 1975
},
{
"school_name": "Lakeside School, Seattle",
"start": null,
"end": null
}
],
"contact_info": {
"blog": "http://thegatesnotes.com",
"twitter": "http://twitter.com/BillGates"
}
}雖然JSON模型減少了應用程序代碼和存儲層之間的阻抗不匹配 但JSON作爲數據編碼格式也存在問題 我們會在文檔模式中的模式靈活性中 討論這個問題
JSON表達式比RMDB的多table格式具有更好的局部性 比如說你想獲取簡介 你在RMDB裡需要再另外Join 在這裏我所有東西都在document裡了
剛剛一對多的問題也在JSON格式中很好的被處理
您所看到的本網站只會用盜版爬蟲抄襲複製別人原創文章的沒梗網站 爬蟲完後還不檢查內容直接發佈 施主還是趕快關閉本網站比較安全 阿彌陀佛
請支持原創文章 拒絕盜版爬蟲 麻煩讀者移駕至本文固定連結
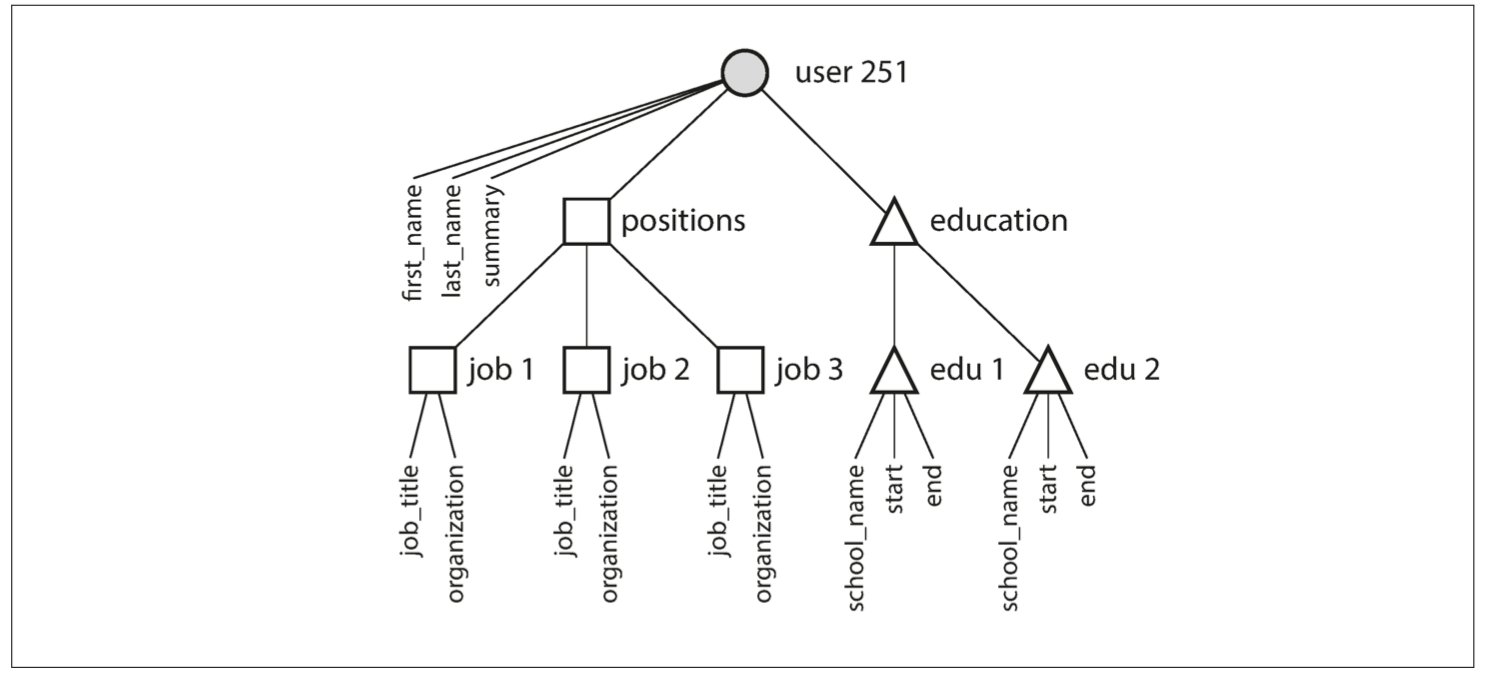
講到這裡 你大概可以區分出關聯模型與文檔模型的差異了
多對一和多對多的關係
如果你有仔細看我們JSON的例子 你會發現region_id和industry_id是以ID形式被記錄 而不是純字串”Greater Seattle Area”和”Philanthropy” 為什麼呢?
既然都是document了 輸入即使是個自由文本感覺也挺合理 但是使用標準化的列表 比如下拉選單給使用者選擇 或是auto-complete有其優勢 優勢如下
-
各個簡介之間樣式和拼寫統一
-
避免歧義 比如說同樣地區的不同寫法
-
可以輕易改名 比如說政治事件 一個地名要改 不需要改所有文件
-
本地化(Localization) 網站翻譯成其他語言時 標準化的列表可以輕鬆的根據使用者的設定客製化
-
便於搜索 你搜索華盛頓州的慈善家也可以找得到這個document 而不是一定要找西雅圖的慈善家
-
對人類有意義的訊息(比如Philanthropy) 只會存在一處 並在所有引用他的地方使用ID 若是直接使用文本 那麼對人類有意義的訊息會存在所有記錄中
-
ID對人類沒有意義 所以永遠不需要改變 即使他代表的東西發生了改變(比如說改名稱之類的) 不需要改變所有的紀錄 當你需要改變所有紀錄 你就必須承擔不一致(inconsistency)的風險 去除這個duplication就是規範化(Normalization)的關鍵思想
所以你看得出來 要支持多對一的關係(很多人在西雅圖工作 很多人是工程師等等) 這對於document模型是比較不利的 在關聯模型中就直接用id 因為join很簡單 但是在document模型中 join通常不太支持
你能做的 就是在你的應用程式中 對於不同的document自己模擬Join
可喜可賀 你在你的第一版實作中 在你的應用程式成功的實作了Join 然後呢 接下來發生的事就是你的數據會越來越大 很容易你的resume中的organization和school_name就不再只是字串 而是一個實體
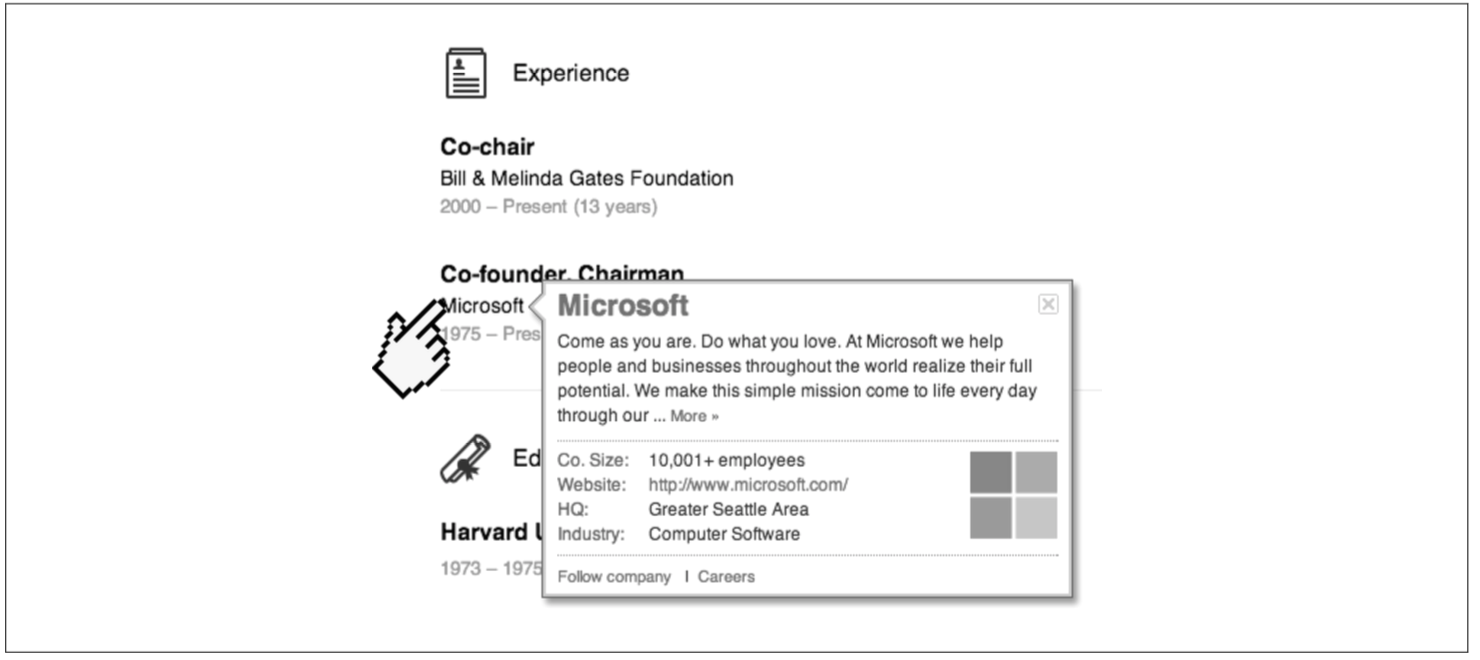
現在你的organization有著Company size和Website等等的資料 這時候你的應用程式就需要跟著改 如果你真的需要在應用程式支援Join的話 這幾乎無可避免 而且隨著資料量的增加 應用程式會越來越複雜
文檔數據庫是否在重蹈覆轍
您所看到的本網站只會用盜版爬蟲抄襲複製別人原創文章的沒梗網站 爬蟲完後還不檢查內容直接發佈 施主還是趕快關閉本網站比較安全 阿彌陀佛
請支持原創文章 拒絕盜版爬蟲 麻煩讀者移駕至本文固定連結
當多對多關係和Join已經在關聯數據庫用的輕鬆寫意時 document數據庫和NoSQL重啟了辯論: 要如何最好的在數據庫中表示多對多的關係
來回顧一下歷史 1970年時最受歡迎的數據處理數據庫是IBM的Information Management System 他只使用了一個簡單的模型 稱為層次模型(hierarchical model)
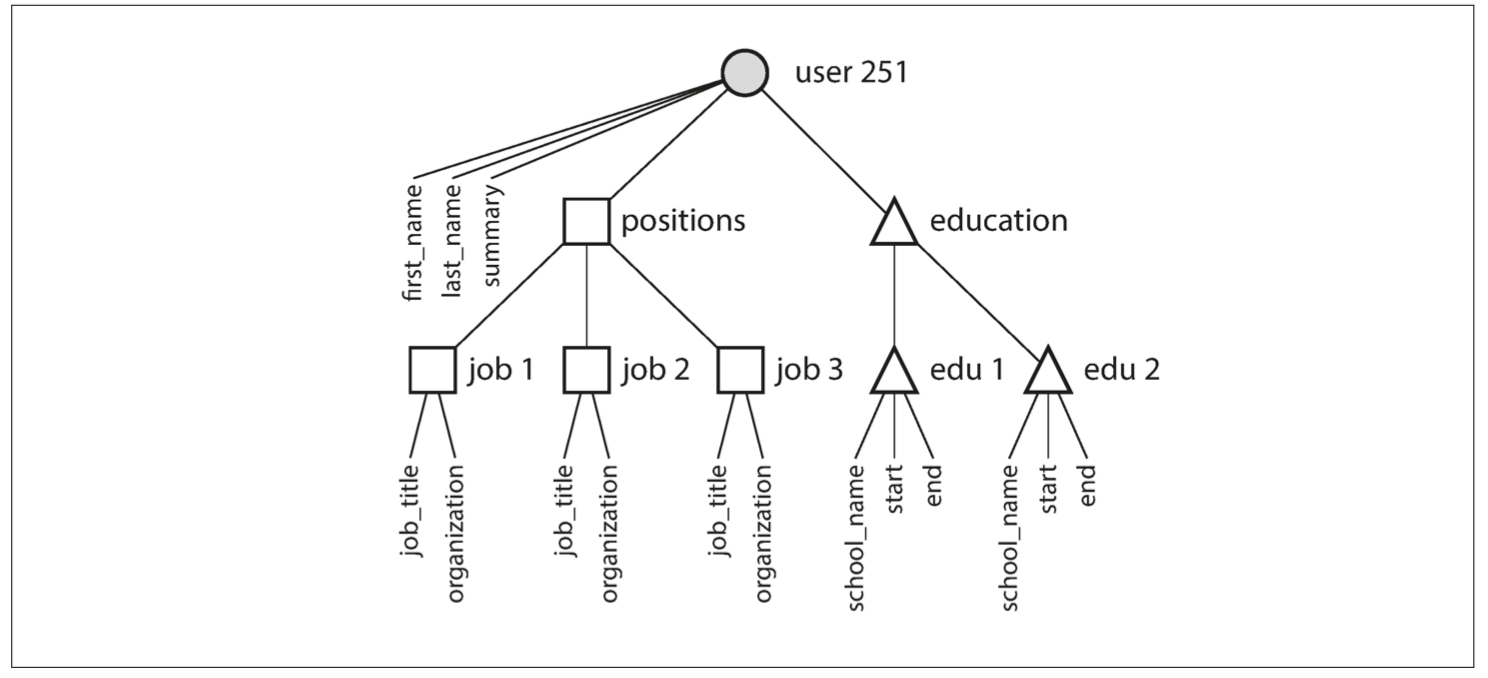
這個模型其實跟JSON非常相似 但也和document數據庫一樣 IMS可以很好的處理一對多 但是對於多對多很難支持Join 開發人員必須決定是否複製數據到每個紀錄 或是手動解決引用 他們當時處理的問題 直到現在都還是document數據庫的問題
而當時最被提倡的兩個解法 第一個是關係模型(relational model)(之後也成為SQL統治了世界) 第二個是網路模型(network model) 這兩個陣營的辯論延續了很長的時間
因為當初這兩個模型要解決的問題 直到今天都還在 讓我們來稍微回顧一下這辯論
網路模型Network model
網路模型由數據系統語言會議(CODASYL)進行了標準化 又稱為CODASYL模型 CODASYL模型也是層次模型的推廣
在層次模型的樹結構中 每條記錄只有一個父節點 但在CODASYL模型中 每條記錄可能有多個父節點 比如說”Greater Seattle Area”是一條紀錄 每個居住在該地區的用戶都可以和其關聯 這也允許了多對一和多對多的關係建模
在網路模型中 記錄和記錄之間不是以foreign key連結 而是像是pointer的概念 要訪問一個記錄唯一的方法是從根記錄開始沿著pointer一路找到你要的記錄 這路徑稱為訪問路徑(access path)
基本上 一個訪問路徑就像是遍歷一個linked list 從根記錄開始一路遍歷到你要的記錄 但在多對多的關係中 一條紀錄可以有不同種訪問路徑去訪問 而網路模型的程序員還必須紀錄追蹤這些訪問路徑
所以網路模型的搜尋功能 是透過遍歷紀錄列在數據庫中不斷移動游標來進行 如果紀錄有多個父節點 還必須追蹤所有路徑 CODASYL委員會成員也承認 這就像在n維數據空間中進行導航
關聯模型Relational model
這個大家就很熟了 一個relation就是一個表(table) 也就是一堆tuples所組成 沒有像迷宮的嵌套結構 也沒有多重複雜的訪問路徑
當你要Query你的數據庫 Query優化器會自動決定查詢的順序或是使用哪些索引 程序員幾乎不需要考慮 但如果你想要用新的方式搜索數據 你就需要建立一個新的索引 建立完後 你的Query也不用變 數據庫內部會自行利用你的新索引
和document model比較
文檔數據庫還原為層次模型 在父節點中儲存了嵌套記錄(比如說像是position或是education的一對多關係) 而不是存在單獨的表中
但在表示多對一或是多對多的關係時 關聯數據庫和文檔數據庫並沒有根本的不同 相關項目都被一個unique identifier引用 在關聯數據庫中稱為foreign key 在文檔模型中稱為document reference 這個identifier會在讀取的時候被join或是後續的查詢來解析
您所看到的本網站只會用盜版爬蟲抄襲複製別人原創文章的沒梗網站 爬蟲完後還不檢查內容直接發佈 施主還是趕快關閉本網站比較安全 阿彌陀佛
請支持原創文章 拒絕盜版爬蟲 麻煩讀者移駕至本文固定連結
所以 document model並沒有走上CODASYL的老路
關聯型數據庫與文檔數據庫在今日的對比
在比較這兩個時 可以考慮許多方面的差異 包含容錯屬性(第五章)和處理並發性(第七章) 本章重點在數據模型中的差異
關聯性數據庫的好處是支持多對一和多對多的關係來 文檔數據庫則是架構靈活性 局部性而擁有的更好的性能 和較少的阻抗不匹配
哪個數據模型更方便寫代碼
直觀地說 應用程序中的模型數據比較接近文檔的結構 我們總不希望應用程式中的數據還要從其他表中join
但是文檔模型的侷限性如下
1.你不能直接引用文檔中的嵌套的項目 你必須說”用戶251的位置列表中的第二項”等等來存取項目
2.多對多關係會是個問題 你也許可以denormalize來減少join的需求 但要保持資訊的一致性是非常困難的 你會需要向數據庫發出多個請求讓你在應用程式中join 但這也讓你把複雜度留在應用程序裡 不但程序複雜 性能也差
很難說哪個數據模型讓應用程序代碼更簡單 取決於數據項之間存在的關係種類 如果是高度關聯的數據 圖數據模型 > 關聯模型 > 文檔模型
文檔模型中的架構靈活性
文檔數據庫有時稱為無模式(schemaless) 小心這個詞很誤導 因為讀取數據的代碼總是假定某種結構 比較精確的講法應該是讀時模式(schema-on-read) 也就是隱藏的數據結構只有在讀取時才知道 相對應關聯數據庫則是寫時模式(schema-on-write) 因為傳統的關係數據庫方法中 模式明確 且數據庫確保所有的數據都符合其模式 才能寫入
讀時模式有點像是Runtime的動態檢查 寫時模式像是靜態的編譯時檢查
今天如果應用程式要改變數據格式 這些方法的區別就更加明顯
假設原本使用者只有儲存名字 現在要姓跟名分開存
文檔數據庫
if (user && user.name && !user.first_name) {
// Documents written before Dec 8, 2013 don't have first_name
user.first_name = user.name.split(" ")[0];
}關聯數據庫
ALTER TABLE users ADD COLUMN first_name text;
UPDATE users SET first_name = split_part(name, ' ', 1); -- PostgreSQL
UPDATE users SET first_name = substring_index(name, ' ', 1); -- MySQL需要改變schema 在改變的過程中 數據庫必須停止運作 而且這通常很慢 因為他會生出一個新的table 再把每一個row都重新寫一次
所以如果一個集合中的每個元素不是擁有同樣結構時 讀時模式更具優勢
您所看到的本網站只會用盜版爬蟲抄襲複製別人原創文章的沒梗網站 爬蟲完後還不檢查內容直接發佈 施主還是趕快關閉本網站比較安全 阿彌陀佛
請支持原創文章 拒絕盜版爬蟲 麻煩讀者移駕至本文固定連結
查詢的數據局部性
文檔通常是以一個很長的字串存成JSON或XML 所以如果應用程式需要經常訪問整個文檔(比如說render網頁) 那局部存儲就有很大的優勢 因為你不需要一直query數據庫去decorate你的id
但是天不從人願 大多數情況 你只需要一個文檔的其中一小部分而已 這對於每次都讀取整個文檔是很浪費的 而且在更新文檔時 通常需要整個重新寫入(除非你不改變文檔的大小 那還有可能容易一些) 這些性能限制大大減少了文檔數據庫的實用場景
值得一提的是 為了局部性而把相關的資訊集合起來 不是只有文檔模型有
1.Google的Spanner就在關聯模型中支持局部性 藉由允許一個table的row被嵌套在父表內
2.Oracle允許多表索引集群表(multi-table index cluster tables)
3.BigTable數據模型(用於Cassandra和HBase)的列族(column family)概念和管理局部性的概念類似
文檔和關係數據庫的融合
2000年以後 大多數關聯數據庫都已經支援XML(代表著可以使用XML文檔進行本地修改 以及索引和查詢) 這允許應用程序使用和文檔數據相當類似的模型
9.3版本之後的PostgreSQL 5.7版本之後的MySQL 以及10.5之後的IBM DB2 也對JSON文件提供類似的支持 根據JSON在網際網路的使用情況 不難想像其他關聯數據庫也很快會陸續跟進
另一方面 文檔數據的RethinkDB 在查詢時也支援了類似關係的連接 文檔數據的MongoDB也可以自動resolve文檔中的引用(其實也就是多了一層處理client-side join)
隨著時間的推移 關聯數據庫和文檔數據庫似乎變得越來越相似 數據模型互相補充是一件好事 如果可以處理類似文檔的數據 又可以進行關聯查詢 那簡直天下太平
所以結合關係模型和文檔模型 是未來數據庫一條很好的路線
數據查詢語言
關聯模型使用的是聲明式查詢語言 IMS和CODASYL則是使用命令式代碼來查詢數據庫
直接看例子 給定一個動物物種的列表 我們想返回列表中的鯊魚
您所看到的本網站只會用盜版爬蟲抄襲複製別人原創文章的沒梗網站 爬蟲完後還不檢查內容直接發佈 施主還是趕快關閉本網站比較安全 阿彌陀佛
請支持原創文章 拒絕盜版爬蟲 麻煩讀者移駕至本文固定連結
聲明式語言
function getSharks() {
var sharks = [];
for (var i = 0; i < animals.length; i++) {
if (animals[i].family === "Sharks") {
sharks.push(animals[i]);
}
}
return sharks;
}如果你學過relational algebra
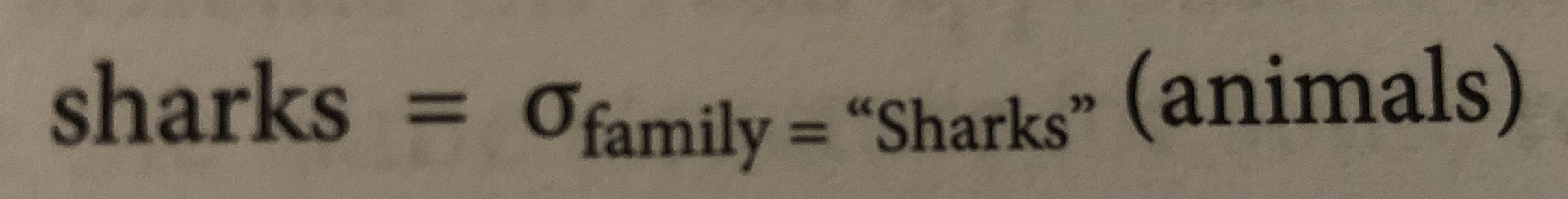
SQL寫法則是緊跟著relational algebra
SELECT * FROM animals WHERE family ='Sharks';命令式語言(imperative)告訴計算機以特定順序執行某些操作 逐行執行 判斷條件 是否再循環等等
聲明式查詢語言(declarative) 你指定所需紀錄要符合什麼條件 還有如何轉換數據(排序 分組和集合等等) 怎麼實現你不管 底層會幫你做到好
還有其他更迷人好處
1.API易懂 把底層包裝的很完善
2.數據庫系統可以在無需對查詢做任何更改的情況下進行性能提升 比如說今天數據庫後台想要回收未使用的空間 可能會導致動物列表的順序改變 那命令式的做法來查詢的話 數據庫並不知道命令式的實作方有沒有依賴於動物列表的順序 就可能出錯 但聲明式查詢語言本來就沒保證順序 所以可以放心優化 而不影響上層的用法
3.聲明式語言往往適合併行執行(parallel) 你想想就知道就只是對每個紀錄做一樣的check 但命令式往往很難並行化 因為他被要求按照動物列表的順序執行
MapReduce查詢
MapReduce是Google推廣的編程模型 用於多台機器上批次處理大規模數據 一些NoSQL數據存儲(包括MongoDB和CouchDB)支持有限形式的MapReduce 作為在多個文檔中執行read-only的query
MapReduce既不是一個聲明式的查詢語言 也不是命令式 而是處於兩者之間 查詢的代碼是命令式 通常寫成map()和reduce() 然後這代碼會被複製到每個需要執行的機器去跑
例子來了 你是個海洋生物學家 你每看到一隻鯊魚就會寫進DB 現在如果你想要知道你這個月看到多少鯊魚
您所看到的本網站只會用盜版爬蟲抄襲複製別人原創文章的沒梗網站 爬蟲完後還不檢查內容直接發佈 施主還是趕快關閉本網站比較安全 阿彌陀佛
請支持原創文章 拒絕盜版爬蟲 麻煩讀者移駕至本文固定連結
SELECT
date_trunc('month', observation_timestamp) AS observation_month,
sum(num_animals) AS total_animals
FROM observations
WHERE family = 'Sharks'
GROUP BY observation_month;那在MongoDB的map-reduce中該怎麼寫呢
db.observations.mapReduce(
function map() {
var year = this.observationTimestamp.getFullYear();
var month = this.observationTimestamp.getMonth() + 1;
emit(year + "-" + month, this.numAnimals);
},
function reduce(key, values) {
return Array.sum(values);
},
{
query: {
family: "Sharks"
},
out: "monthlySharkReport"
});你看到了幾個特點
1.可以聲明式地指定只考慮鯊魚種類的過濾器
2.每個通過過濾器的文檔 都會調用map 輸出一個key-value pair, key是年月 value是次數
比如(2013-12, 3)或(2014-1, 5)
3.按照key分組 對於所有相同key的人 調用reduce
4.reduce就會把特定月份內所有觀測記錄到鯊魚的數量相加
5.輸出寫到monthlySharkReport
Map-Reduce在功能上也有所限制 他們必須是純函數(pure function) 意思是說他們只用傳給他們的輸入做運算 不能再發任何數據庫查詢 也不能有任何副作用 這個重要的限制 讓數據庫能以任何順序運行任何功能 並在失敗時重新跑一次
方便是方便 但SQL只要寫一個query 你這裡還要寫兩個密切合作的方法 這通常比編寫單個查詢更困難 所以MongoDB2.2添加了叫做Aggregate pipeline的聲明式語言 你之後可以這樣寫
您所看到的本網站只會用盜版爬蟲抄襲複製別人原創文章的沒梗網站 爬蟲完後還不檢查內容直接發佈 施主還是趕快關閉本網站比較安全 阿彌陀佛
請支持原創文章 拒絕盜版爬蟲 麻煩讀者移駕至本文固定連結
db.observations.aggregate([
{ $match: { family: "Sharks" } },
{ $group: {
_id: {
year: { $year: "$observationTimestamp" },
month: { $month: "$observationTimestamp" }
},
totalAnimals: { $sum: "$numAnimals" } }}
]);看起來有點像SQL了(只要把match看成select就很像了)
這個故事的寓意 是NoSQL系統很可能會慢慢演進而發行SQL 儘管帶著一些偽裝
圖數據模型
剛剛講了那麼長一篇 你知道文檔模型比較大的問題是在處理多對多的關係 雖然關聯模型可以很好處理多對多的關係 但隨著數據之間的連接變得更加複雜 將數據建模為圖形顯得更加自然
一個圖有兩個物件組成
1.點(vertices): 又稱節點(node) 實體(entity)
2.邊(edges): 又稱關係(relationships)或弧(arcs)
有很多常見的數據都可以被建構成圖形 比如說
1.社交圖: 點是人 邊是好友關係
2.網路圖: 點是網頁 邊是彼此的連結link
3.公路或鐵路: 點是車站或交叉路口 邊是路
你可以使用那些大學的演算法課適用的眾所皆知的算法 來導航汽車找出兩點間最短路徑 或是找出一個網頁的流行程度(被cite的次數)等等
但圖數據並不是只能表示這樣的同類(homogeneous)數據 一個點除了是人之外 還可能是地點 事件 簽到 或是用戶的評論 邊除了表示兩人的朋友關係 還可以表示誰發了某個評論 誰參與了某個事件
看個例子 來自愛達荷州的Lucy和來自法國Beaune的Alain 目前已婚住在倫敦
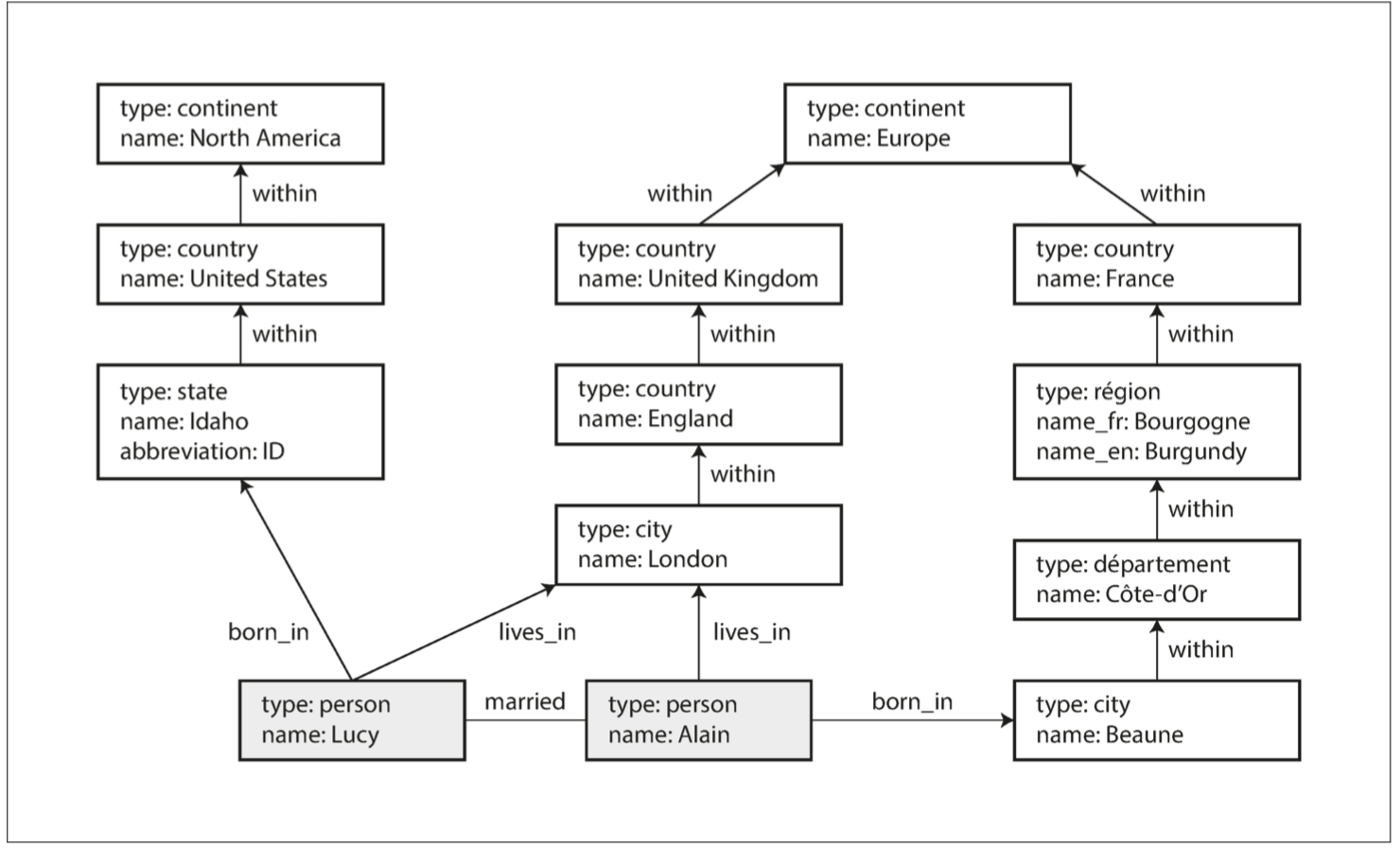
有幾種不同但是相關的方法可以建構和查詢圖中的數據 這一節我們會講到屬性圖(property graph)模型 跟 三元組(triple-store)模型 我們還會看到三種關於圖形查詢的聲明語言:Cypher SPARQL和Datalog
屬性圖 property graph
在屬性圖模型中 每個頂點包括了
1.唯一的標識符(unique identifier)
2.一組出邊(outgoing edges)
3.一組入邊(ingoing edges)
4.一組屬性(key-value pair)
每個邊包括了
您所看到的本網站只會用盜版爬蟲抄襲複製別人原創文章的沒梗網站 爬蟲完後還不檢查內容直接發佈 施主還是趕快關閉本網站比較安全 阿彌陀佛
請支持原創文章 拒絕盜版爬蟲 麻煩讀者移駕至本文固定連結
1.唯一的標識符(unique identifier)
2.邊的起點
3.邊的終點
4.描述兩個頂點之間關係類型的標籤
5.一組屬性(key-value pair)
然後一個屬性圖就可以當成是兩個relational table 一個存點 一個存邊 每個entity都用一個json來存所有其他屬性
CREATE TABLE vertices (
vertex_id INTEGER PRIMARY KEY,
properties JSON
);
CREATE TABLE edges (
edge_id INTEGER PRIMARY KEY,
tail_vertex INTEGER REFERENCES vertices (vertex_id),
head_vertex INTEGER REFERENCES vertices (vertex_id),
label TEXT,
properties JSON
);
CREATE INDEX edges_tails ON edges (tail_vertex);
CREATE INDEX edges_heads ON edges (head_vertex);你了解過關聯式數據庫 這個表就很容易了解 有幾點重要的事
1.沒有限制哪些事物可不可以關聯 也就是任何點對點都可以產生邊
2.給定任一點 可以很簡單的找到所有出邊跟入邊 然後就可遍歷圖
3.你可以給不同類型的點和邊不同的label(如同剛剛說的這不是只能支持homogeneous) 可是卻還是可以在同一個圖上建模型!
4.非常容易可以延伸圖! 假設今天你想在社交圖上標註哪些人對哪些食物過敏 你就只要加上食物的點(標上label) 然後把人跟食物加上一個邊 就搞定了! 想加什麼就加什麼 這樣關聯是數據庫是要改schema甚至需要migration的
是不是很有趣? 接下來講兩種方式來查詢屬性圖
Cypher查詢語言
Cypher是屬性圖的聲明式查詢語言 由Neo4j圖形數據庫而發明
先看怎麼insert剛剛Lucy跟Alain的例子 進到屬性圖數據庫
CREATE
(NAmerica:Location {name:'North America',type:'continent'}),
(USA:Location {name:'United States',type:'country' }),
(Idaho:Location {name:'Idaho', type:'state' }),
(Lucy:Person {name:'Lucy' }),
(Idaho) -[:WITHIN]-> (USA) -[:WITHIN]-> (NAmerica),
(Lucy) -[:BORN_IN]-> (Idaho)上面的Cypher程式插入了左邊區域的四個點和三個邊
看完插入 我們來看搜索 假設我們現在要找所有從美國移民到歐洲的人的名字 並返回符合的vertex的name
要怎麼找呢 我們要找的頂點需要符合兩個條件
1.擁有一條連到美國任一位置的BORN_IN邊
2.一條連到歐洲的任一位置的LIVING_IN邊
MATCH
(person) -[:BORN_IN]-> () -[:WITHIN*0..]-> (us:Location {name:'United States'}),
(person) -[:LIVES_IN]-> () -[:WITHIN*0..]-> (eu:Location {name:'Europe'})
RETURN person.name您所看到的本網站只會用盜版爬蟲抄襲複製別人原創文章的沒梗網站 爬蟲完後還不檢查內容直接發佈 施主還是趕快關閉本網站比較安全 阿彌陀佛
請支持原創文章 拒絕盜版爬蟲 麻煩讀者移駕至本文固定連結
解讀如下
找到滿足以下兩個條件的所有頂點(稱之為person頂點)
1.person頂點有一條到某頂點的BORN_IN出邊 從那個頂點開始沿著一系列的WITHIN到達一個類型是location 而且
name是United State的頂點2.person頂點有一條到某頂點的LIVE_IN出邊 從那個頂點開始沿著一系列的WITHIN到達一個類型是location 而且
name是Europe的頂點對於這樣的頂點 返回
name屬性
你可能可以想到兩種做法 一種是從人頂點出發 每個頂點都確認看看符不符合條件 一種是從位置頂點出發 看看能不能找到符合條件的人
但是因為是聲明式語言 你不用擔心數據庫實作的細節 查詢優化程序會自動選擇預測效率最高的策略
SQL中的圖查詢
如果是把剛剛的例子用在關聯數據庫上 也可以用SQL查詢嗎
可以 但有點困難 困難的點是在 你並不知道一個人頂點要經過多少個邊 才會到你要的location的點 所以connection的數目是變量!
剛剛我們就輕描淡寫的用WITHIN * 0表示沿著WITHIN邊一次或多次搞定
好消息是 SQL支持WITH RECURSIVE
WITH RECURSIVE
-- in_usa is the set of vertex IDs of all locations within US
in_usa(vertex_id) AS (
SELECT vertex_id FROM vertices WHERE properties ->> 'name' = 'United States'
UNION
SELECT edges.tail_vertex FROM edges
JOIN in_usa ON edges.head_vertex = in_usa.vertex_id
WHERE edges.label = 'within'
),
-- in_europe is the set of vertex IDs of all locations within EU
in_europe(vertex_id) AS (
SELECT vertex_id FROM vertices WHERE properties ->> 'name' = 'Europe'
UNION
SELECT edges.tail_vertex FROM edges
JOIN in_europe ON edges.head_vertex = in_europe.vertex_id
WHERE edges.label = 'within' ),
-- born_in_usa is the set of vertex IDs of all people born in the US
born_in_usa(vertex_id) AS (
SELECT edges.tail_vertex FROM edges
JOIN in_usa ON edges.head_vertex = in_usa.vertex_id
WHERE edges.label = 'born_in' ),
-- lives_in_europe is the set of vertex IDs of all people living in EU
lives_in_europe(vertex_id) AS (
SELECT edges.tail_vertex FROM edges
JOIN in_europe ON edges.head_vertex = in_europe.vertex_id
WHERE edges.label = 'lives_in')
SELECT vertices.properties ->> 'name'
FROM vertices
JOIN born_in_usa ON vertices.vertex_id = born_in_usa.vertex_id
JOIN lives_in_europe ON vertices.vertex_id = lives_in_europe.vertex_id;悲劇 你敢看我還真不敢寫 這說明了不同的設計模型完全是為了不同的應用而設計 選擇適合的模型非常的重要
三元組存儲Triple-Stores
除了屬性圖之外 還有三元組存儲可以可以儲存圖結構
在三元組存儲中 所有信息都以非常簡單的三部分表示形式存儲
(主詞, 動詞, 受詞)
比如說(Jim, likes, banana)
主詞:就是圖上的一個頂點
受詞:就是圖上的一個頂點 或是一個字串或數字 像是(lucy, age, 33)
動詞:如果受詞是圖上的一個頂點 動詞就是連結兩者的邊
再回顧一次我們要的結果
您所看到的本網站只會用盜版爬蟲抄襲複製別人原創文章的沒梗網站 爬蟲完後還不檢查內容直接發佈 施主還是趕快關閉本網站比較安全 阿彌陀佛
請支持原創文章 拒絕盜版爬蟲 麻煩讀者移駕至本文固定連結
我們一樣來產生一下左半邊的Lucy的資料
@prefix : <urn:example:>.
_:lucy a :Person.
_:lucy :name "Lucy".
_:lucy :bornIn _:idaho.
_:idaho a :Location.
_:idaho :name "Idaho".
_:idaho :type "state".
_:idaho :within _:usa.
_:usa a :Location
_:usa :name "United States"
_:usa :type "country".
_:usa :within _:namerica.
_:namerica a :Location
_:namerica :name "North America"
_:namerica :type :"continent"_:someName就是頂點的名字
一直重複相同的主詞有點惱人 幸運的是 我們可以寫成這樣
@prefix : <urn:example:>.
_:lucy a :Person; :name "Lucy"; :bornIn _:idaho.
_:idaho a :Location; :name "Idaho"; :type "state"; :within _:usa
_:usa a :Loaction; :name "United States"; :type "country"; :within _:namerica.
_:namerica a :Location; :name "North America"; :type "continent".SPARQL查詢語言
如同Cypher用來查詢屬性圖 SPARQL也可以用來查詢三元組存儲
今天一樣來查找從美國轉移到歐洲的人
PREFIX : <urn:example:>
SELECT ?personName WHERE {
?person :name ?personName.
?person :bornIn / :within* / :name "United States".
?person :livesIn / :within* / :name "Europe".
}結構非常相似 來比較一下 以下兩兩意思相同
(person) -[:BORN_IN]-> () -[:WITHIN*0..]-> (location) # Cypher
?person :bornIn / :within* ?location. # SPARQL
(usa {name:'United States'}) # Cypher
?usa :name "United States". # SPARQL總結
數據模型是個複雜的問題 我們快速的瀏覽了各個不同的模型 希望能讓你有廣泛的了解 要深入研究就看各位施主的應用需要
歷史中 數據最開始被表示為一棵大樹(層次數據模型) 但是這不利於表示多對多的關係 所以發明了關聯模型 但到了最近 開發人員發現某些應用不適合用關聯模型 適用的NoSQL主要分成兩類
1.文檔數據庫:數據通常是來於文檔中,而且文檔之間的關係非常稀少
2.圖形數據庫:和文檔數據庫相反 圖形數據庫適合用在關聯非常多的情況
NoSQL的共通好處是他們不再寫入時強制規定schema 這讓你的應用可以因應變化
這三種模型在今日都被廣泛使用 而且每個模型都有各自的查詢語言和框架 我們討論了SQL, MapReduce, MongoDB的aggregation pipeline, Cypher, SPARQL等等
雖然我們講了不少 但還有一些東西還沒被講到
1.使用基因組數據的研究人員通常需要執行序列相似性搜索 這代表存儲需要很長的字串(代表DNA) 給定一個DNA串 要如何在數據庫裡找一個最相似的 我們目前提到的數據庫都沒有符合這樣的需求 這也是GenBank這樣的專門的基因組數據庫軟件處理的問題
2.粒子物理學家也需要在數百億兆字節的範圍內搜索 這種規模通常也需要特別的解決方案來阻止硬件失控
您所看到的本網站只會用盜版爬蟲抄襲複製別人原創文章的沒梗網站 爬蟲完後還不檢查內容直接發佈 施主還是趕快關閉本網站比較安全 阿彌陀佛
請支持原創文章 拒絕盜版爬蟲 麻煩讀者移駕至本文固定連結
3.全文搜索是一種經常與數據庫一起使用的數據模型 在本書中不會提到太多 我們會在第三章提到搜尋索引