Linux 效能工具 - Intermediate
May 17, 2020最近看到大神 Brendan D. Gregg的演講 覺得自己對於Linux的工具實在是太不熟了 於是想稍微熟讀一下
本系列的目的不是把每個指令的每個option都寫出來 想知道的話man一下就知道了
本文的目的是 希望你看完之後 對於每個有用的指令都有個印象 當你需要偵錯或是研究你的系統哪裡出了問題 你可以知道有哪個指令可以用 然後再去慢慢讀document
本文是照著Linux Performance Tools, Brendan Gregg演講的順序講解
您所看到的本網站只會用盜版爬蟲抄襲複製別人原創文章的沒梗網站 爬蟲完後還不檢查內容直接發佈 施主還是趕快關閉本網站比較安全 阿彌陀佛
請支持原創文章 拒絕盜版爬蟲 麻煩讀者移駕至本文固定連結
strace
system call tracer 就是可以讓你追蹤系統調用
什麼是系統調用呢 就是你跟OS Kernel發出的調用 System call通常發生在
1.Process的創建或管理(fork(), wait(), kill()…)
2.Intormation管理(getpid(), alarm(), sleep()…)
3.檔案讀寫 資料夾管理(open(), close()…)
4.Device I/O(loctl(), read(), write()…)
5.Communication(pipe(), msgget()…)
知道什麼是System Call之後 再來看看我們該怎麼用strace
第一種用法
你可以看到一個你下達一個command之後 這個command到底幫你調用了多少system call
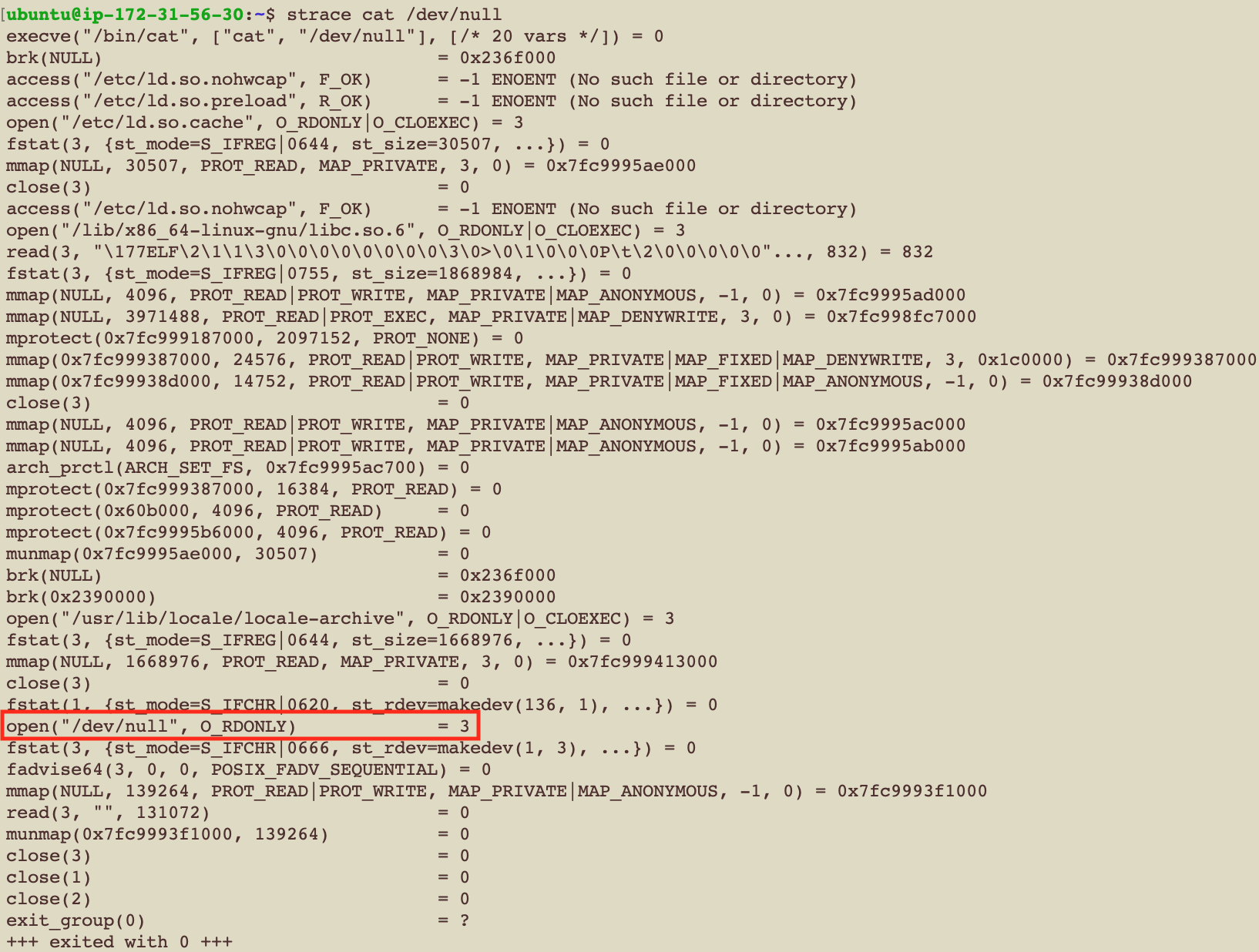
哇靠 原來只是cat一下居然發生了這麼多事 你可以看到所有被呼叫的system call 還有每個system call的參數
那如果cat一個不存在的檔案呢
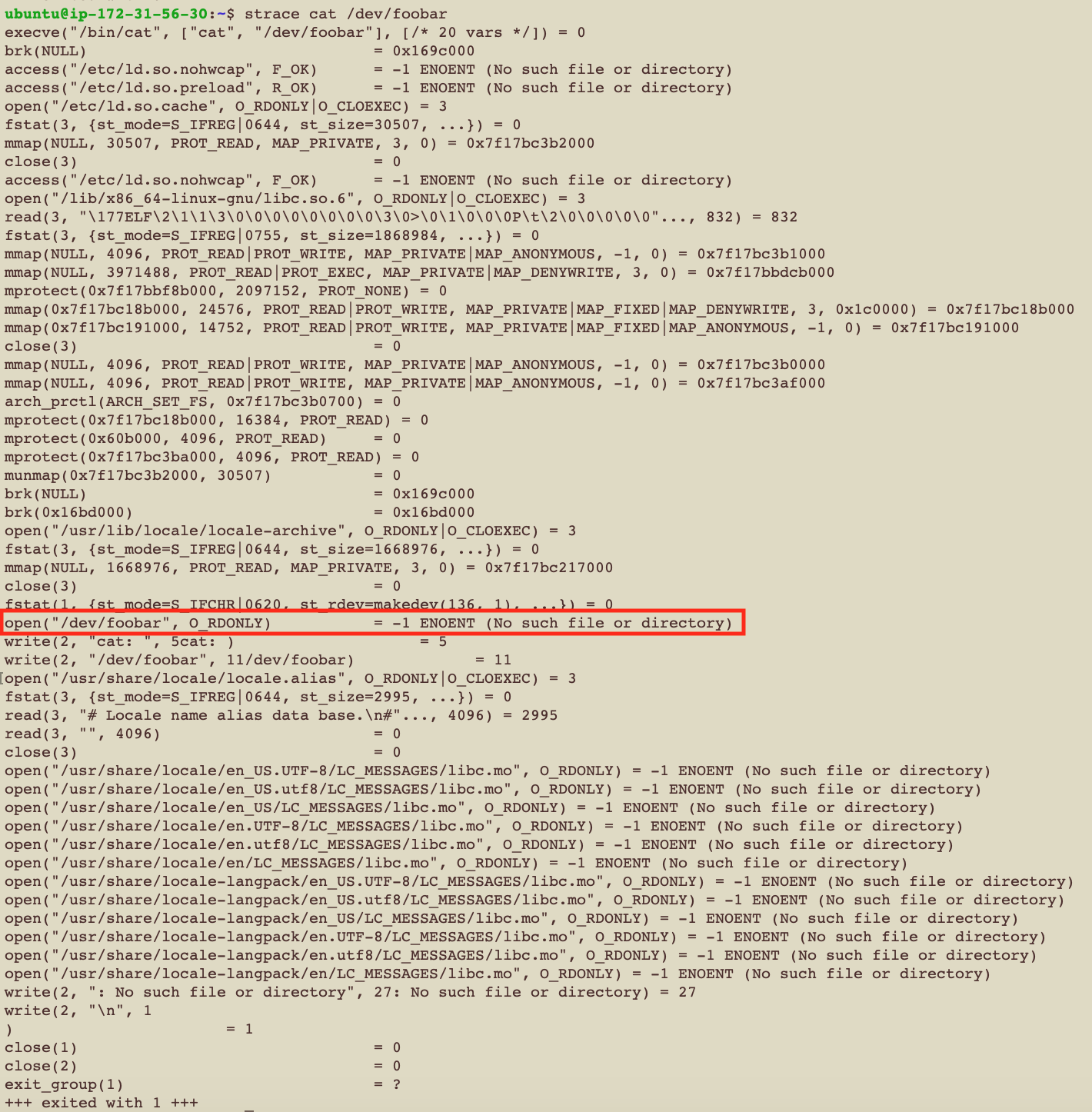
ok 了解 就是可以讓你完完整整地看到我們發給OS的函式和參數 還有OS給我們的回應
可是這是當我們知道command的情況下才有用 我們大多數時候並不知道是哪個command出了問題 那該怎麼debug呢
第二種用法
更高端的用法 strace可以綁定一個process id 然後監控這個process發出的所有system call
我先看一下我現在這個terminal的pid是多少
開另一個terminal監控
你會發現 啊 原來每一個鍵盤輸入 都會調用system call啊 你如果真的想深入研究 可以去看每個指令的document
在我們的demo中常見的read write 的第一個參數fd = 0 也就是輸入是來自standard input 就是我們的鍵盤
我已經示範了怎麼完完全全的監控某個進程的所有系統調用了 你手上的工具又比別人多了一個 以後別人問你
“咦 這個command(或是binary)怎麼跑不起來 error message沒有足夠的訊息 怎麼辦”
你就可以教他怎麼看這個指令跟OS交互的所有過程
注意
容我稍微提醒你一下 因為這個指令需要去監視 然後記下所有system call的細節 所以性能開銷非常大 如果是在production上使用要非常小心
tcpdump
就是可以讓你看所有Network Traffic細節 還可以把所有傳送中的封包看得一清二楚
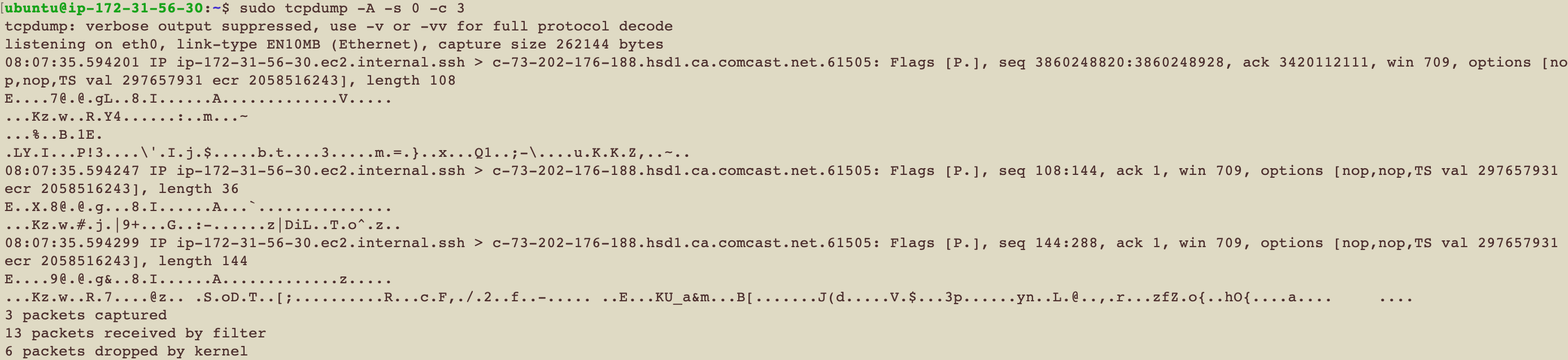
當然封包內容這樣硬看是沒人看的懂的 通常需要搭配Wireshark服用
netstat
顯示所有與Networking有關的資訊 比如IP/TCP/UDP/ICMP等等協定相關的資料
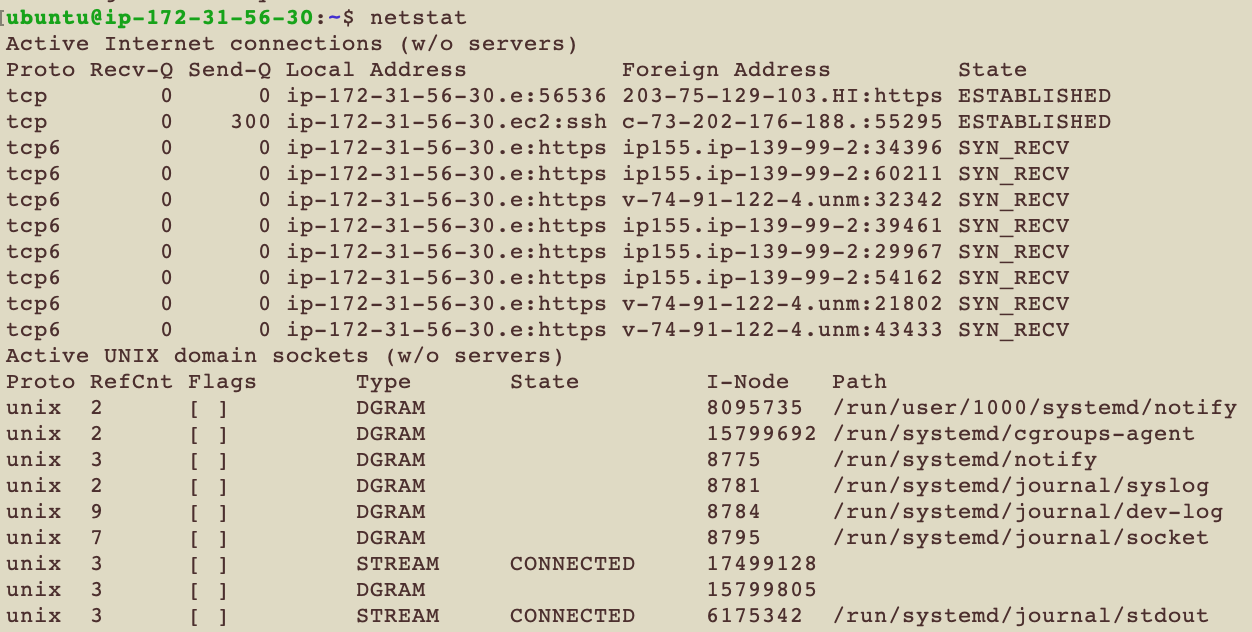
| 代號 | 解釋 |
|---|---|
| Proto | 哪個協定 |
| Recv-Q | 這個socket裡還有多少byte需要被讀 |
| Send-Q | 這個socket裡還有多少byte需要被送出 |
| Local Address | 本地端的Address跟Port |
| Foreign Address | 另外一端的Address跟Port |
| State | 目前狀態 |
基本上Recv-Q跟Send-Q都要是0 不是0代表你的Network出問題了
State的可能值可以參考這裡
這個是列出所有socket的情況 還有一個常見的用法
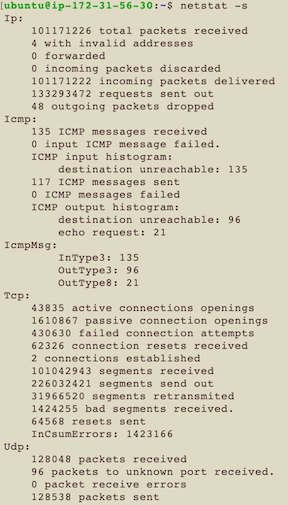
netstat -s
s代表summary 列出每個協定的總結
nicstat
列出關於網路流量的統計數據

| 代號 | 解釋 |
|---|---|
| Time | 現在時間 |
| Int | Interface name |
| rKB/s | 接收到的流量 kB/s |
| wKB/s | 傳送出去的流量 kB/s |
| rPk/s | 接收到的Package/s |
| wPk/s | 傳送出去的Package/s |
| rAvs | 接收到Package的平均大小 |
| wAvs | 傳送出去的Package的平均大小 |
| %Util | Interface使用率 |
| Sat | Saturation 也是這個Interface裡發生的error/s |
| State | 目前狀態 |
pidstat
Linux Task的統計數據
不同的option秀出同一個Task的不同面向的統計數據
pidstat -u
-u 看的是CPU的使用情況 也是預設的選項
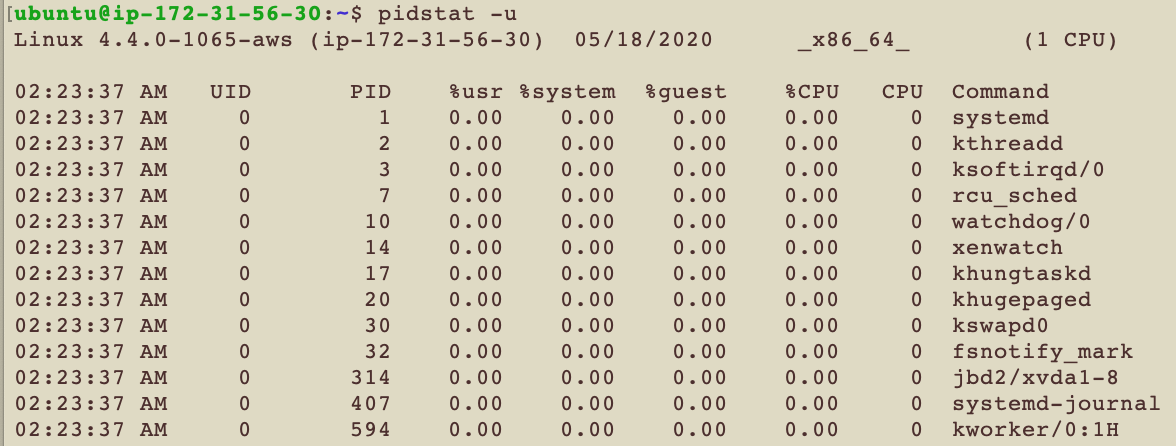
| 代號 | 解釋 |
|---|---|
| UID | User ID |
| PID | Process ID |
| %usr | user-level的CPU使用量 |
| %system | system-level的CPU使用量 |
| %guest | Percentage of CPU spent by the task in virtual machine |
| %CPU | 總共多少百分比的CPU被使用在這個Task |
| CPU | 這個Task跑在哪個Processor上 |
| Commadn | 跑這個task的指令 |
pidstat -d
-d 看的是I/O的使用情況
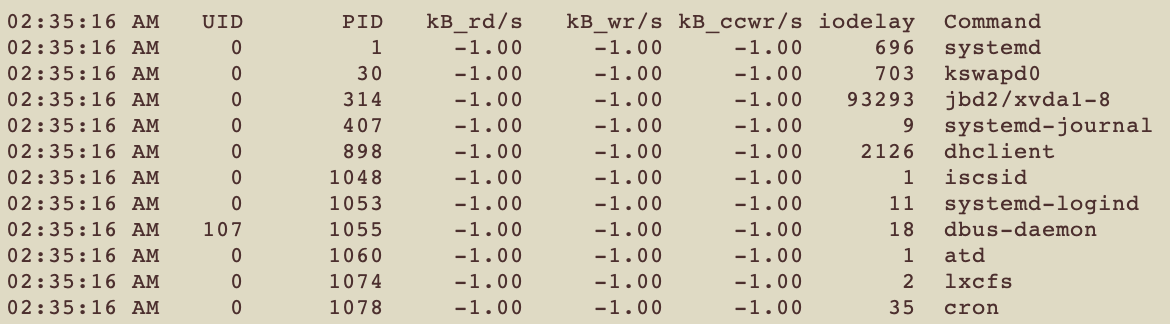
| 代號 | 解釋 |
|---|---|
| UID | User ID |
| PID | Process ID |
| kB_rd/s | 這個Task每秒從Disk讀了幾kB的資料 |
| kB_wr/s | 這個Task每秒寫進Disk幾kB的資料 |
| kB_ccwr/s | 每秒有多少kB寫進Disk之後任務被取消 |
| iodelay | I/O的延遲 |
| Commadn | 跑這個task的指令 |
pidstat -s
-s 看的是stack的使用率
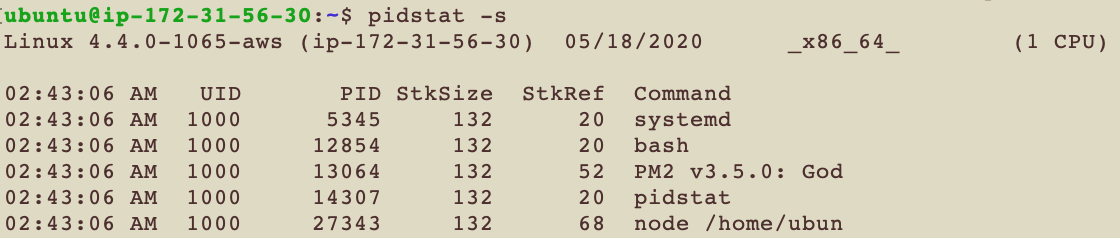
| 代號 | 解釋 |
|---|---|
| UID | User ID |
| PID | Process ID |
| StkSize | 多少kB的記憶體保留給這個Task |
| StkRef | 多少kB的記憶體真的被這個Task使用 |
| Commadn | 跑這個task的指令 |
pidstat -v
-v 看的是kernel table的使用情況
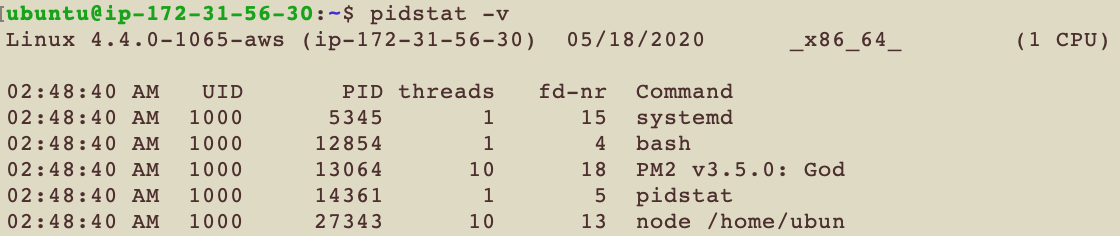
| 代號 | 解釋 |
|---|---|
| UID | User ID |
| PID | Process ID |
| threads | 這個Task使用了多少thread |
| fd-nr | 這個Task使用了多少file descriptor |
| Commadn | 跑這個task的指令 |
pidstat -r
-r 看的是page fault和記憶體的使用量
Page Fault
要了解這個指令 首先要先稍微了解什麼是Page Fault
因為物理內存數量有限 非常珍貴 所以當一個Process跟我們說需要4MB的空間才能執行 即使我們物理內存只有1MB可以給它 我們還是先跟Process說沒問題 包在我身上 但事實上我們需要偷偷記得
1.我們承諾給了它4MB 分別是虛擬記憶體的0~4MB的空間
2.但事實上 只有0-1MB的物理內存是給他的 剩下1MB-4MB的東西在硬碟裡
3.先這樣 等它需要用到1MB~4MB再說
這三點會由MMU(Memory Management Unit)來負責記得
那什麼是Page Fault呢 就是出包的時候 當這個進程說
“安安 我要3MB-4MB的東西 快給我吧”
這時MMU就會跟CPU說
“挫賽 我手上沒有 在Disk裡” 這時候MMU需要做幾件事
1.去Disk要3MB-4MB的東西
2.Swap 替換掉物理內存的那1MB的資料
3.記得現在物理內存的東西是3MB-4MB的東西
這就是Page Fault 也稱為Major Page Fault
那什麼是Minor Page Fault呢 就是其實3MB-4MB的東西其實是在物理內存裡的沒錯 但這並不是留給這個進程用的(可能別的進程剛好也需要這個資料) 那這就比較好處理 MMU只要稍微記一下 多了一個進程要用同一個東西 就可以開心得給它用了 不用再去跟Disk要資料來swap
我們回來 pidstat -r
不好意思剛剛離題離得有點遠 我本來不想討論太多OS細節的東西 但發現不講一下Page Fault這個指令講不下去
-r 看的是page fault和記憶體的使用量
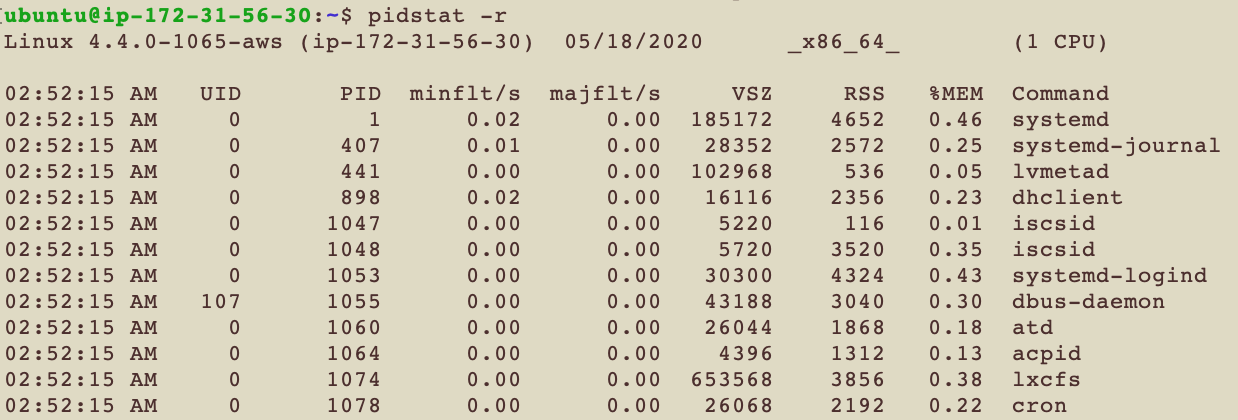
| 代號 | 解釋 |
|---|---|
| UID | User ID |
| PID | Process ID |
| minflt/s | 這個Task每秒鐘有多少Minor Page Fault |
| majflt/s | 這個Task每秒鐘有多少Major Page Fault |
| VSZ | Virtual Size, 這個Task總共用了多少kB的virtual memory |
| RSS | Resident Set Size, 這個Task總共用了多少kB的physical memory |
| %MEM | 這個Task目前使用多少比例的記憶體 |
| Commadn | 跑這個task的指令 |
swapon/swapoff
很簡單 swapon指令下了之後 系統就可以做swapping跟paging
swapoff指令下了之後 則swapping跟paging都會被禁止
如果你的應用在跑的時候physical memory不太夠的話 就可以swapon
lsof
列出所有被開啟的檔案
奇怪了 列出被開啟的檔案有什麼了不起? 別忘了在Linux的世界 幾乎所有的系統資源都是用檔案來呈現 連結檔 裝置檔 管線檔 socket等等 所以當你想知道到底哪些資源被使用了 你就只要看哪些檔案被打開就可以
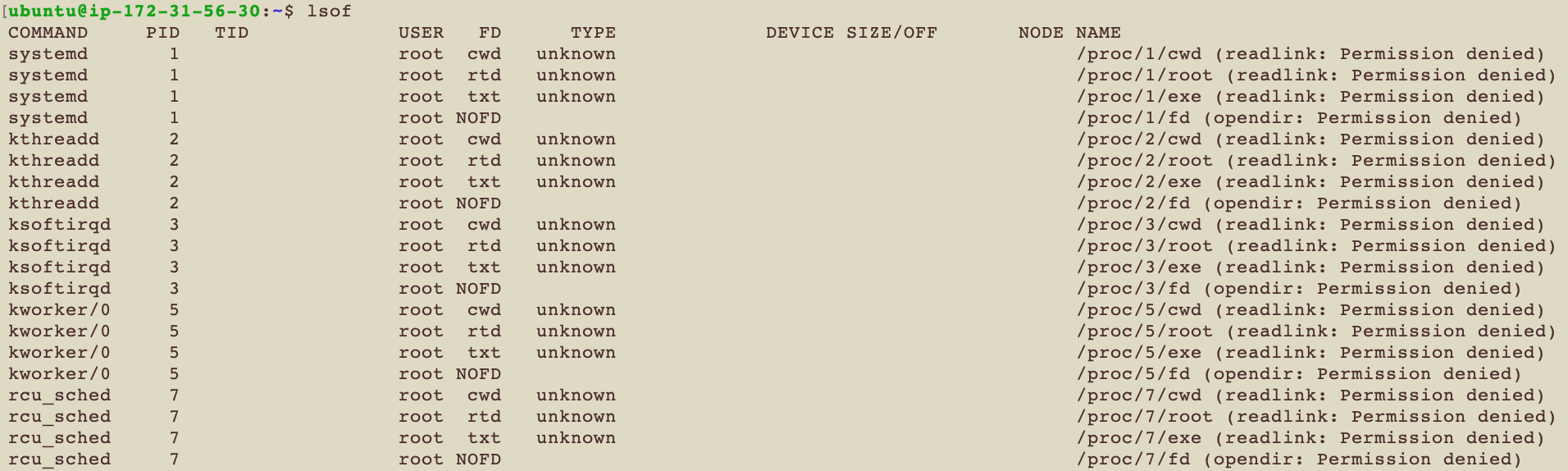
| 代號 | 解釋 |
|---|---|
| COMMAND | 哪個指令執行的 |
| PID | Process ID |
| TID | Task ID |
| USER | 就是使用者 |
| FD | File descriptor number |
| TYPE | 檔案類型 |
| DEVICE | Device number |
| SIZE/OFF | size of the file or the file offset in bytes |
| NODE | node number |
| NAME | 檔案名稱 |
使用man lsof仔細看了之後 覺得這個指令讓我學到很多
比如說TYPE的介紹 擷取一部分
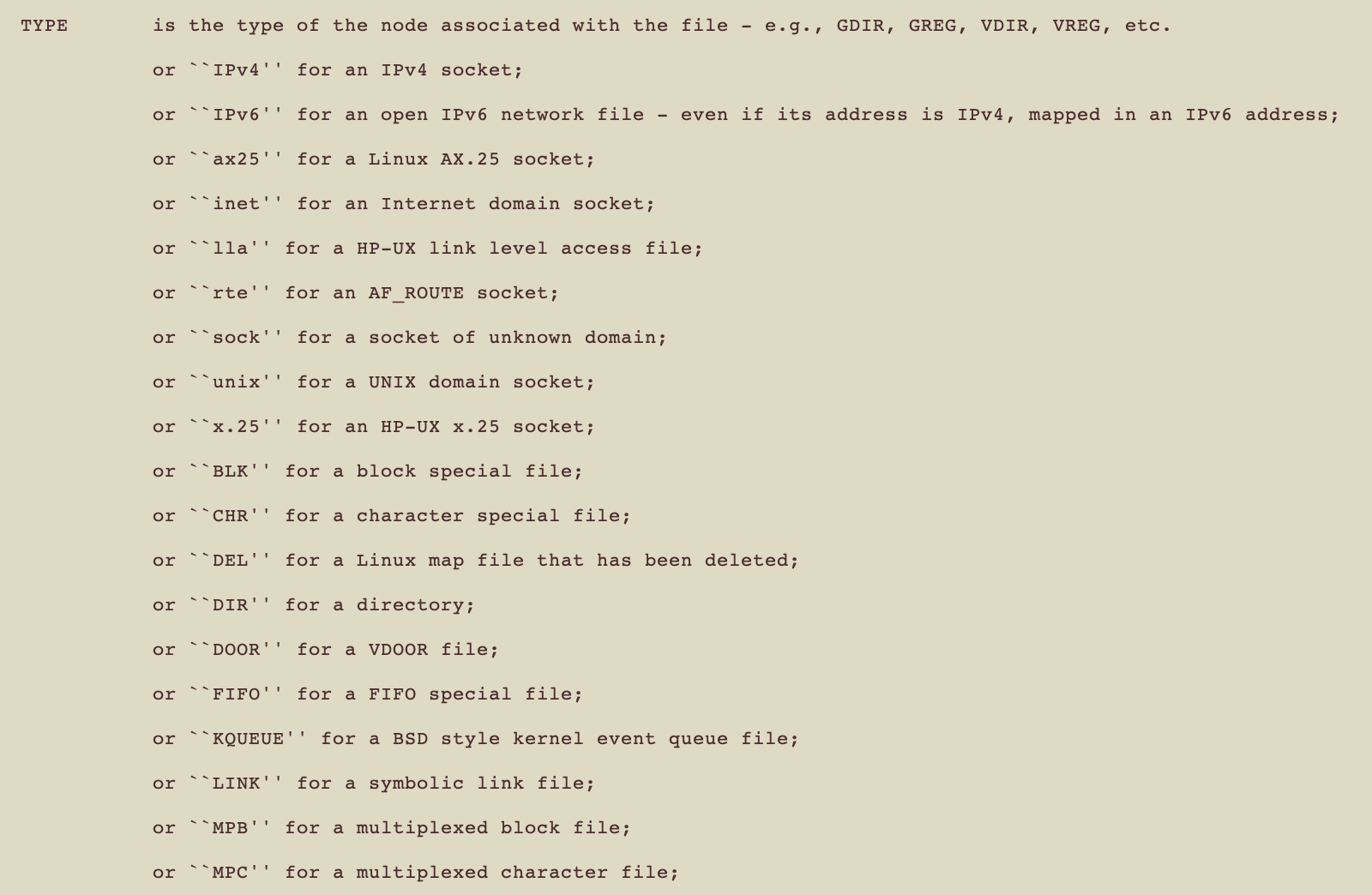
哇靠 原來這些都是檔案喔XD 非常建議各位讀者去讀一下lsof的doc
如果只是輸入lsof的話 秀出的資訊實在太多了 所以你通常會需要加上一些option
lsof +D [Directory] 找在某個資料夾下被開啟的檔案
lsof -c [COMMAND_NAME] 找被某個command執行後而開啟的檔案
lsof -p [PID] 找某個process id 開啟的檔案
lsof [FILE_PATH] 找出被開啟的檔案的細節
我們來試試看吧 先開一個terminal用vim開啟一個檔案
再開另一個terminal 用lsof來看一下

有趣吧
sar
System Activity Reporter 系統活動報告
sar大概是目前Linux上最為全面的系統性能分析工具之一 如果今天有個比賽 要你用最少的指令找出問題 那我會推薦sar 因為它的功能實在太多 給不同的參數可以觀察系統的不同部分
sar -q

告訴你系統的負載
| 代號 | 解釋 |
|---|---|
| runq-sz | 等待運行的進程數 |
| plist-sz | 總共有多少task |
| ldavg-1 | 最近一分鐘系統負載平均 |
| ldavg-5 | 最近五分鐘系統負載平均 |
| ldavg-15 | 最近十五分鐘系統負載平均 |
| blocked | 有多少task被blocked住(可能是在等I/O) |
sar -u

告訴你CPU的使用率
有沒有感覺秀出的欄位跟mpstat很像? 差別是mpstat可以看到每個單獨CPU的狀況
| 代號 | 解釋 |
|---|---|
| CPU | 第幾個CPU |
| %usr | user-level的CPU使用量 |
| %nice | user-level並且有指定nice的任務的CPU使用量 |
| %system | system-level的CPU使用量 |
| %iowait | 當有I/O request的時候 CPU閒置的時間比例 |
| %steal | 這個CPU等待其他CPU計算佔用的時間比例 |
| %idle | CPU閒置的時間百分比 |
sar -W

可以查看頁面交換發生的情況
| 代號 | 解釋 |
|---|---|
| pswpin/s | 每秒系統換入的交換頁面 |
| pswpout/s | 每秒系統換出的交換頁面 |
等等
這樣要講到什麼時候 sar的功能實在太強 不同的option幾乎就是不同的功能了 有沒有個簡潔的圖讓我知道怎麼用sar呢
有的 Brendan Gregg 早已幫你整理好
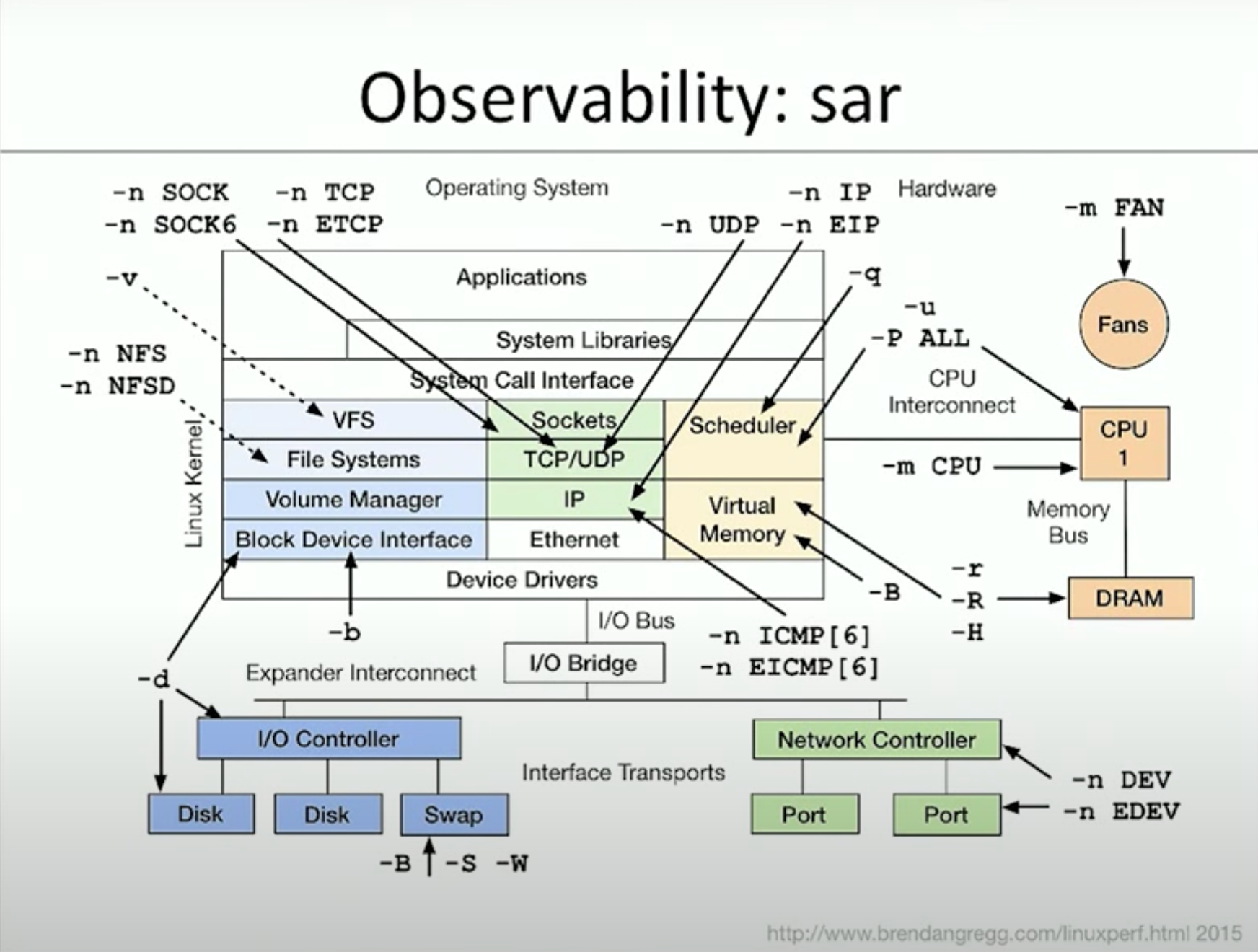
你懷疑哪裡有問題 就去sar一下吧
總結
本篇文章中 提到了許多中階的的查看系統表現的指令
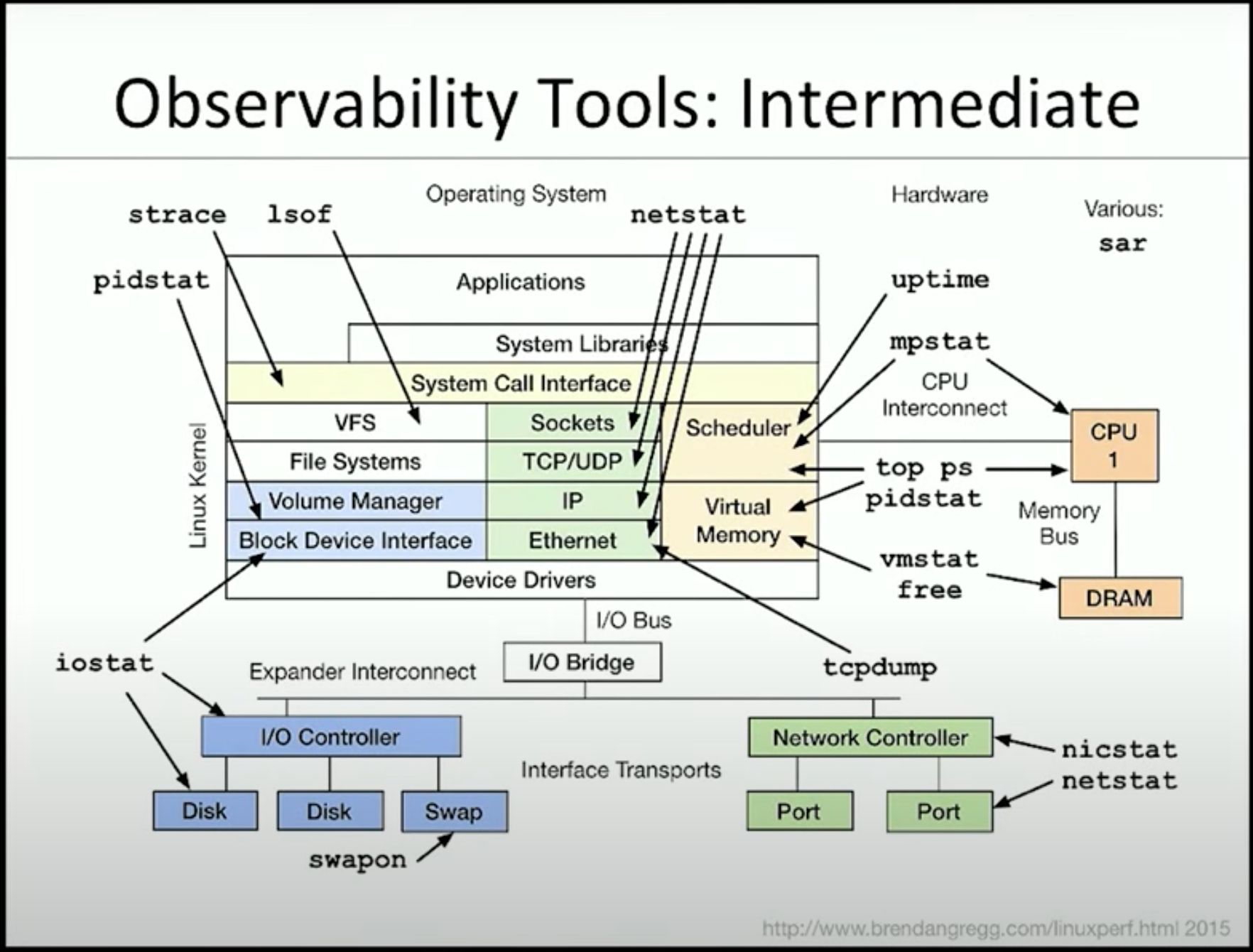
下一篇是進階篇 盡請期待