系統設計 - 設計縮網址服務
December 05, 2019設計縮網址服務是系統設計的月經考題 這篇文章我們就來Mock一下迷途書僮 看看這些年來他準備系統設系準備的如何
還記得上次我們跟迷途書僮聊天 聊了許多關於如何大方向的準備系統設計 請參考系統設計 - Design cache
Design 縮網址
jyt0532: 今天我們來設計縮網址的服務 概念很簡單 使用者可以給我一個很長的網址 這個服務要回傳一個短的網址 讓使用者可以傳給其他人使用
Requirement
迷途書僮: 我是聽話的乖寶寶 首先我要先問清楚系統的功能 總之 系統要達到兩件事
1.使用者給一個長網址 回傳短網址
2.使用者給一個短網址 我們要re-direct到長網址
jyt0532: 沒錯
迷途書僮: 那這個短網址多久會過期呢 我們如果永久的保存可能會花很多錢在沒有人在用的storage
jyt0532: 好問題 五年吧 但當初創建的使用者也可以提供多久後失效 但最多五年
迷途書僮: 有其他功能嗎 比如說 我們還要提供Tracker 讓創建短網址的人可以知道有多少人來過 停留了多久等等
jyt0532: 好 這可以當作進階的收費功能
迷途書僮: 那要提供一個密碼嗎 比如說要輸入密碼才可以存取短網址
jyt0532: 聽起來不錯 你想得比我想的還多 我們可以看看基本功能討論完之後有沒有時間可以再討論這個
迷途書僮: 好 現在我要問系統的需求 Consistency跟Availability哪個重要
jyt0532: Availability
迷途書僮: 創建跟存取哪個的latency比較重要呢 你可以接受創建短網址時等久一點 還是access的時候等久一點
jyt0532: access的latency非常重要 創建稍微久一點還沒太大關係
迷途書僮: 還有其他要求嗎
jyt0532: 你生出來的短網址 不可以是predictable的 比如說jyt0532.com/123123 後面都是數字的話 這樣任何人都可以在後面擺上別的數字 去存取到當初創建人不希望被存取的頁面 影響到分析跟使用者的信任
Constraints
迷途書僮: 這個系統是read-heavy還是write-heavy? 大約的QPS分別是多少
jyt0532: 這是個read-heavy的系統 Read:Write = 100:1
假設創建短Url的QPS是100 URL/s 存取短Url的QPS是10000 Request/s
迷途書僮: 真刺激 那要計算storage之前 我們還需要問清楚幾個問題
第一個問題 創建的時候 可以輸入的最長網址長度是多少? 如果不給限制的話 系統可能會被Abuse
jyt0532:就假設500個character吧 也就是500Bytes
迷途書僮: 第二個問題 回傳給他的長度應該要多長才夠 domainName不算的話
jyt0532:你問我囉?
迷途書僮: 對不起!

jyt0532:你覺得多少才夠?
迷途書僮: 我想想 我們總共需要存的對應mapping在五年之內總共有
100 * 3600 * 24 * 365 * 5 = 15B
代表我們需要15 billion個短網址 假設我們短網址是用A-Za-z0-9這62個字母而已的話 需要長度6就很夠了 62^6 = 56B > 15B
所以長度六就可以
jyt0532: 很好 然後呢
迷途書僮:然後我們就可以繼續分析Storage
15B個mapping 每個key是6 bytes, value是500bytes 總共15 * 10^9 * (506) = 7.6TB
jyt0532: 很好 再來
迷途書僮: 再來需要算一下bandwidth 每個讀寫需求的payload size大約500Bytes
Write Bandwidth = 100 * 500 = 50KB/s
Read Bandwidth = 10000 * 500 = 5MB/s
整理一下
Traffic: Write 100 QPS, Read 10k QPS
Storage: 7.6TB
Bandwidth: Incoming 50KB/s, Outgoing 5MB/s
API design
jyt0532: 嗯 士別三日 已非吳下阿僮 接下來來設計一下服務的API吧
第一個: shortenURL(api_dev_key, original_url)
就這麼簡單 等到系統提供複雜功能的時候 可以加上expiration_date或是custom_alias參數 但目前就這兩個
api_dev_key 指的是允許呼叫你的前端的token 讓server知道現在是誰在發送請求 我們就可以分配/控制每個前端發送請求的bandwidth 比如我們可以限制每個使用者一小時可以創造多少短網址 用途一是避免惡意對手DDOS搞爆你的服務 第二當然就是可以依照不同流量需求收費
回傳一個string 就是長度6的字串
第二個: retrieveURL(api_dev_key, url_key)
這就是get的api 回傳original_url
Database design
jyt0532: 再來選擇Database 你要用RMDB還是NoSQL?
迷途書僮: 先來回頭看一下我們的data
1.我們需要存billion數量級的紀錄
2.每個紀錄本身很小(<1KB)
3.記錄跟紀錄之間沒有強大的關聯relationship 基本上不太需要join
4.Read-heavy
看完這些特性 想必你知道我們該用NoSQL 畢竟scale起來容易一些 選擇key-valye的NoSQL比如說Redis/Voldemort/Dynamo都可以
需要兩個Table
URL Table:
| HashKey(Primary Key) | OriginalURL | CreateDate | ExpireDate | CreatedByUserId |
|---|---|---|---|---|
| varchar(6) | varchar(512) | datetime | datetime | int |
User table:
| UserId(Primary Key) | Name | EnrollAt | |
|---|---|---|---|
| int | varchar(32) | varchar(32) | datetime |
Algorithm
jyt0532: 再來討論Application Server裡面要做什麼吧 給一個長的URL 怎麼生出短的
迷途書僮: 第一個想到的想法就是Hash 我們就用Md5吧 不論你給多長的輸入 輸出都是128bit 我們有62個可能的字元 每個字元需要6 bit(2^6 > 62) 我們就取前六個就可以
jyt0532: 這個方法有個問題
迷途書僮: 有嗎 我感覺挺不錯的
jyt0532: 如果有兩個不同的使用者 想要縮同一個網址 你的算法會產生一樣的短網址 這樣你就無法對兩個相同的長網址分別Analyze
迷途書僮: 說的好 那就在短網址裡面加上一個increasing number就好了 比如說 qazxsw 變成 qazxsw1
jyt0532: 這樣你的輸出就變成predictable了 我可以把後面的1改成2或3 這樣可以搗亂別人的短網址
迷途書僮: 好吧 那就加在input後面吧 當我發現短網址有重複 我就在長網址後面加個increasing number 重新hash
jyt0532: 在分散式系統中要maintain一個increasing counter要怎麼做呢
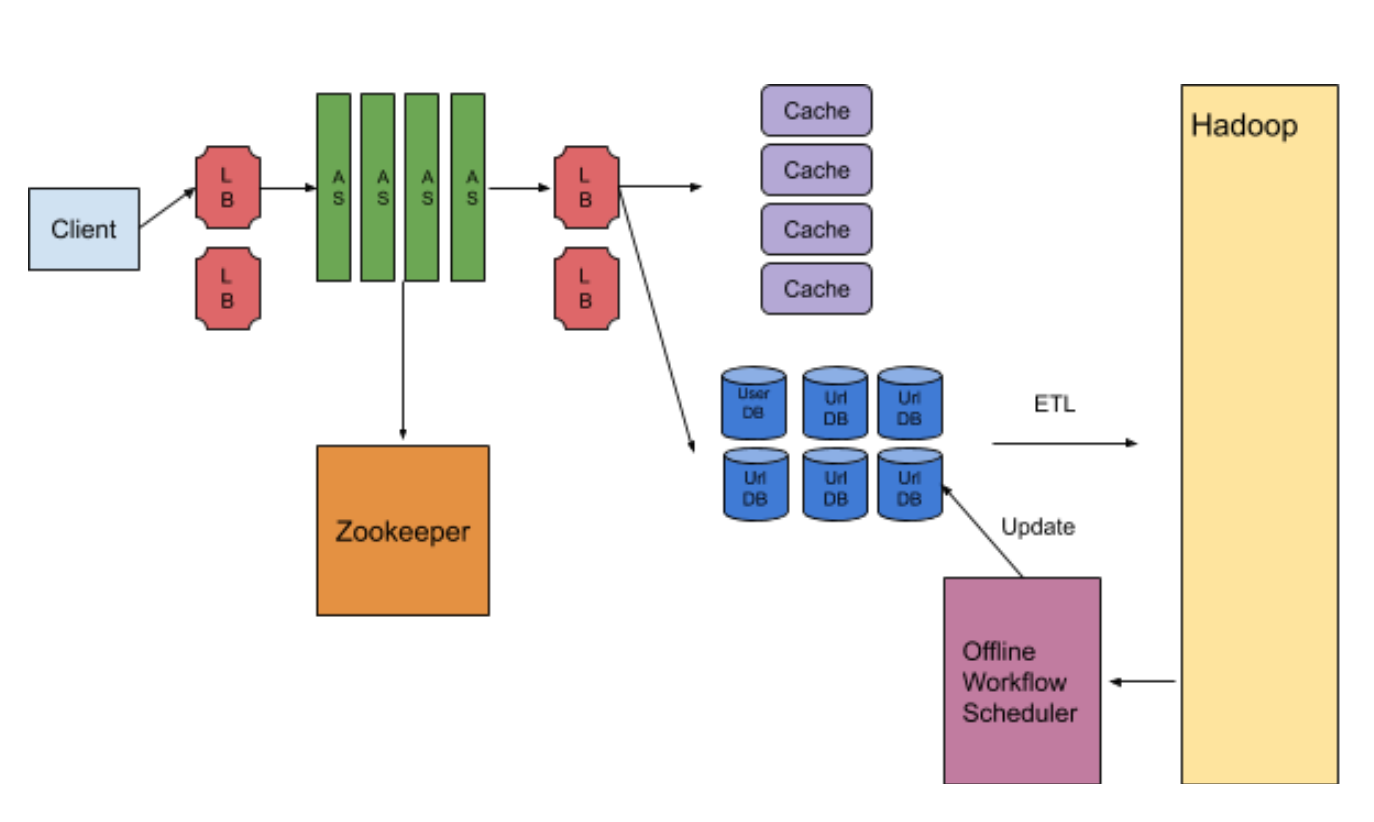
迷途書僮: Zookeeper
jyt0532: 可以多說一點嗎
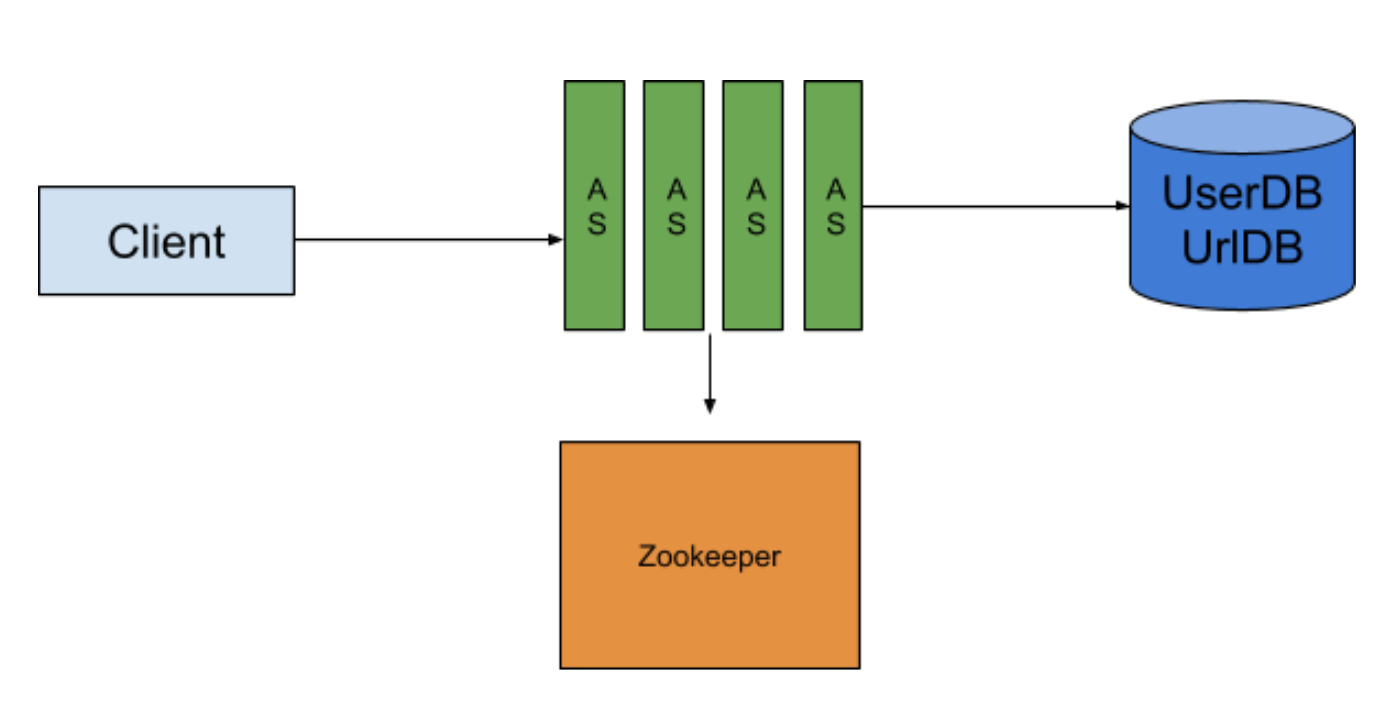
迷途書僮: Zookeeper是分佈式服務框架 是Apache Hadoop的一個子項目 主要用來解決分布式系統中的數據管理協調問題 比如狀態同步服務 集群管理 或是分佈式應用的配置
在這個例子裡 我們把counter交給Zookeeper來管理 我們可以隨意設置怎麼分配counter 比如1~1,000,000給第一台機器 1,000,001~2,000,000給第二台機器
如果有新增新的機器 要先跟Zookeeper註冊 如果有某個機器掛掉了Zookeeper也會知道
有個Zookeeper的分布式協調服務後 我們可以輕易的新增或移除AS 也不用擔心counter亂掉的問題
另一個好處是 有了counter之後 我幾乎不用擔心collision的問題 之前我可能生成了短網址之後 我還需要去DB get看看這個能不能用 如果重複的話再用下一個counter 但如果我無論如何就是拿 (original_url + incrementing_counter) 下去Hash 那我基本上每個Create 短網址的request都少一個DB call

jyt0532: 這個解法本身已經很可行了 今天假設MD5很慢 所有Hash都很慢 Zookeeper很慢 使用者開始抱怨生成短網址的時間太久 有什麼不online生成短網址的方法嗎
迷途書僮: 那不就offline預先生成嗎?
jyt0532: 願聞其詳
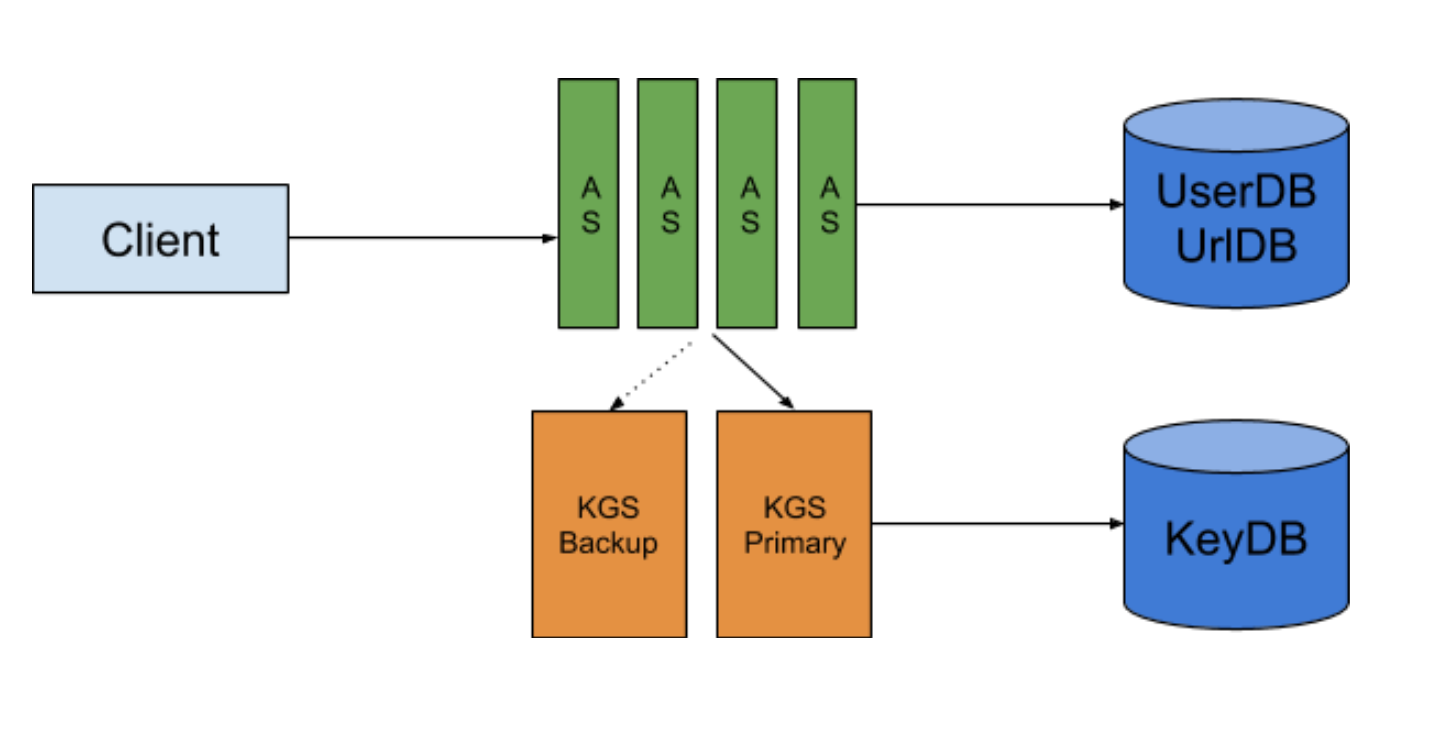
迷途書僮: 我們有一個Key Generating Service先把六碼給生好 每次需要的時候就給一個 這樣我們就完全不用擔心hash collision的問題 或是相同長網址對應到相同短網址的問題
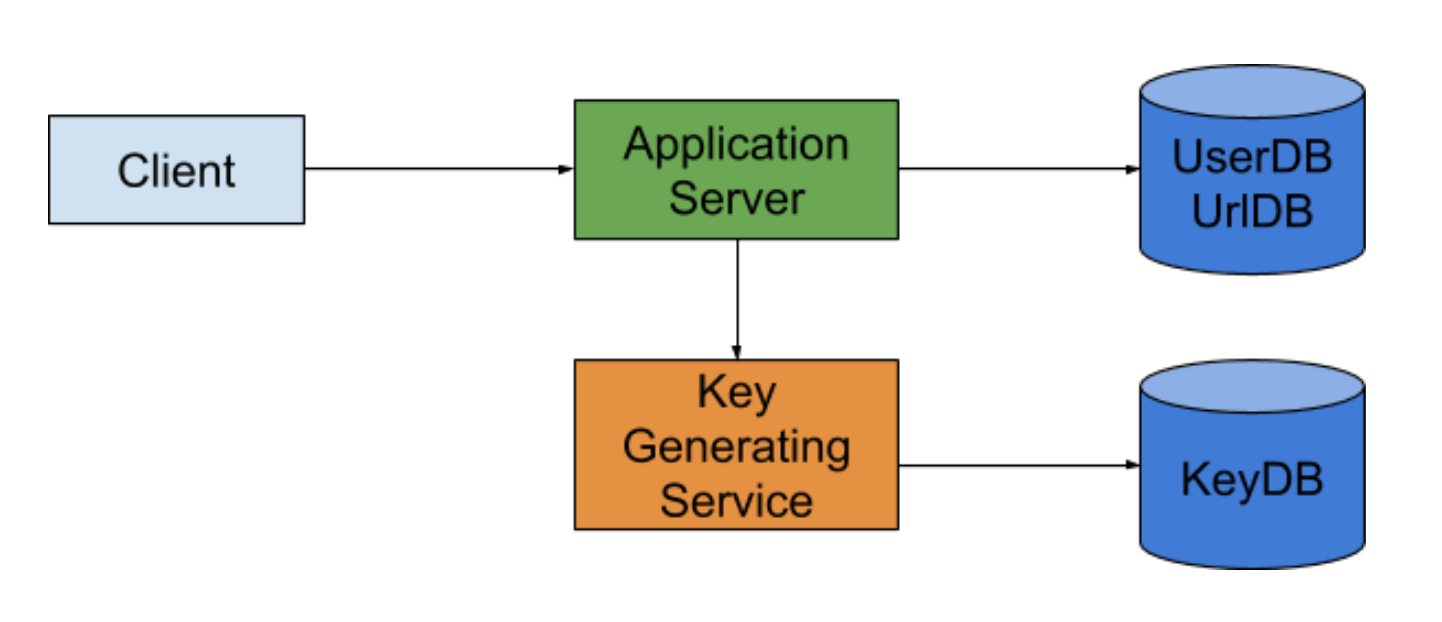
jyt0532: 多了一個keyDB 需要花多少Storage?
迷途書僮: 6 * (62)^6 = 340GB
jyt0532: 雖然少了計算hash的時間 但是多了兩個network call 有辦法加速嗎
迷途書僮: Key Generating Service(KGS)不要每次只拿一個 一次跟Database多拿一點放進Memory就可以
其實Application Server也可以一次跟KGS多拿一點 先放進內存
jyt0532: 你這個圖的Single point of failure有點多
迷途書僮: 矮油 都那麼熟了你還跟我開這種玩笑 AS跟KGS當然是很多台機器的啦
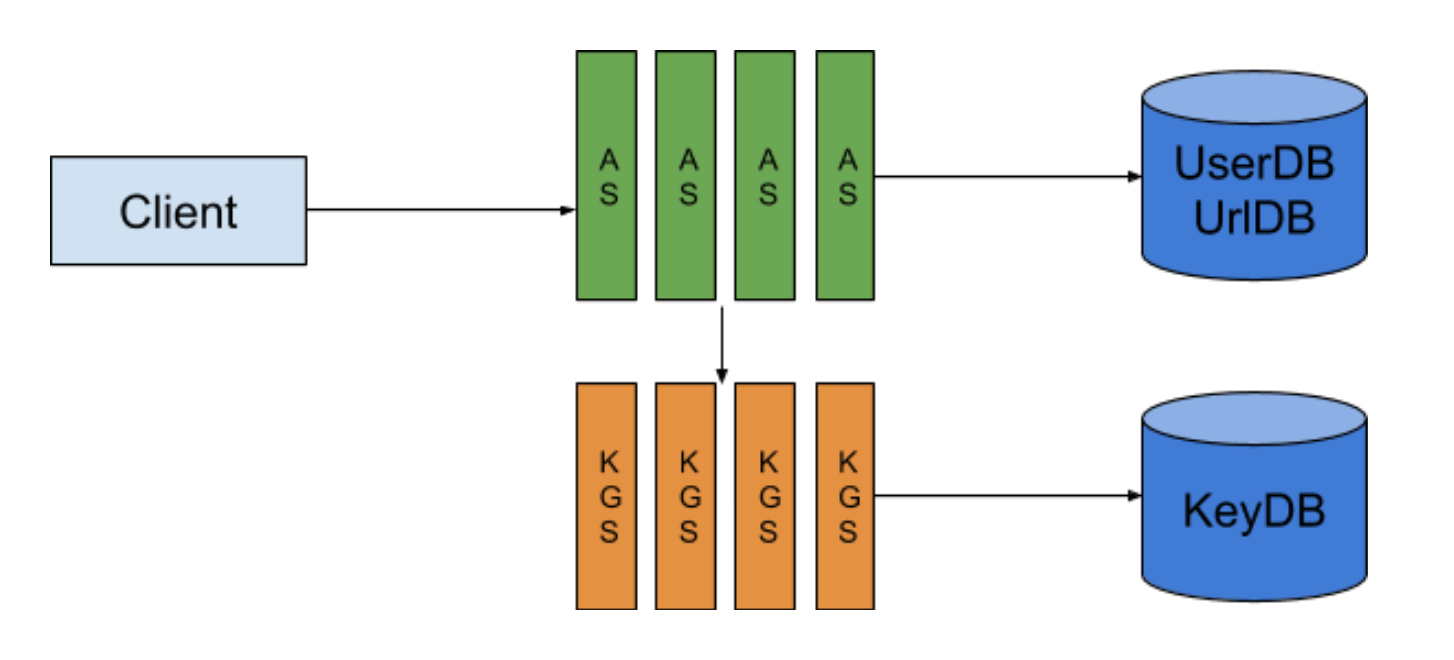
jyt0532: KGS有需要這麼多台嗎 你剛說可以一次跟KGS多拿一點不是嗎? 那為什麼需要這麼多台?
迷途書僮: 說的也是 那我想KGS就兩台就可以 一台主要一台備用
Partition
jyt0532: 該來的還是要來的 總共的Storage 7.6TB一台有點吃力 何況Traffic太大 我們勢必要把資料分區的 你告訴我你想怎麼分
迷途書僮: 就用Hash完後的key第一個字母分囉 畢竟Hash完後的第一個字母分布比較平均 不會有unbalalnced的問題
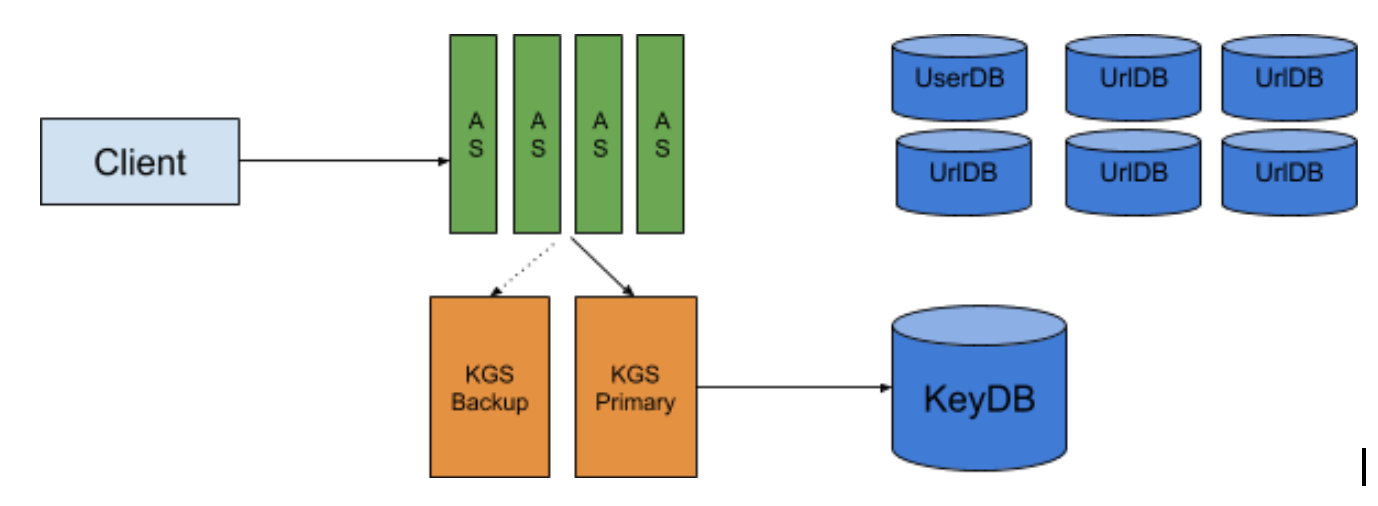
Replication
jyt0532: 這樣的話每台機器都只有一個備份 要是某台機器掛了資料就不見了 怎麼辦
迷途書僮: Consistent Hash搞定備份問題
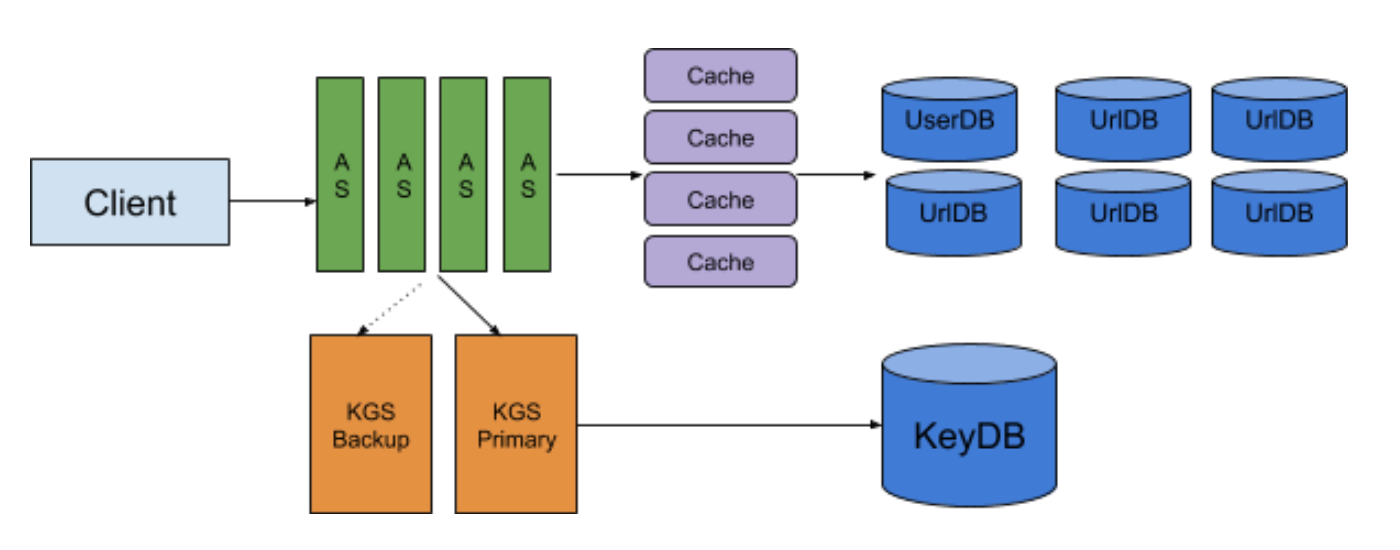
Cache
jyt0532: 好 Create的問題問得差不多了 現在來處理get 這是一個read-heavy的應用 告訴我你怎麼加速get
迷途書僮: 就用Memcache吧
jyt0532: 要幾台 多大的機器
迷途書僮:根據80/20法則 我們大概只需要cache 20%左右的讀需求就夠了
10k * 24 * 3600 * 500Bytes * 0.2 = 86.4GB 這是一天的需求
估算一天已經算是很久了 以一個twitter來說 發出tweet的前幾個小時會很多人存取同樣的連結 但過幾個小時就大量減少 而且可能讀的需求裡面有很多重複的網址 所以事實上不需要這麼大容量 但86.4GB本身就是一台機器的內存可以搞定的事 所以就這樣吧
jyt0532: 那如果我不想apply 80/20法則 我想全部存呢

迷途書僮: 那就多台一點cache囉
jyt0532: Evict strategy?
迷途書僮: 就用LRU吧
jyt0532: 關於緩存的讀寫機制你了解多少
迷途書僮: 看完這篇就全部都馬了解
jyt0532: 算你狠
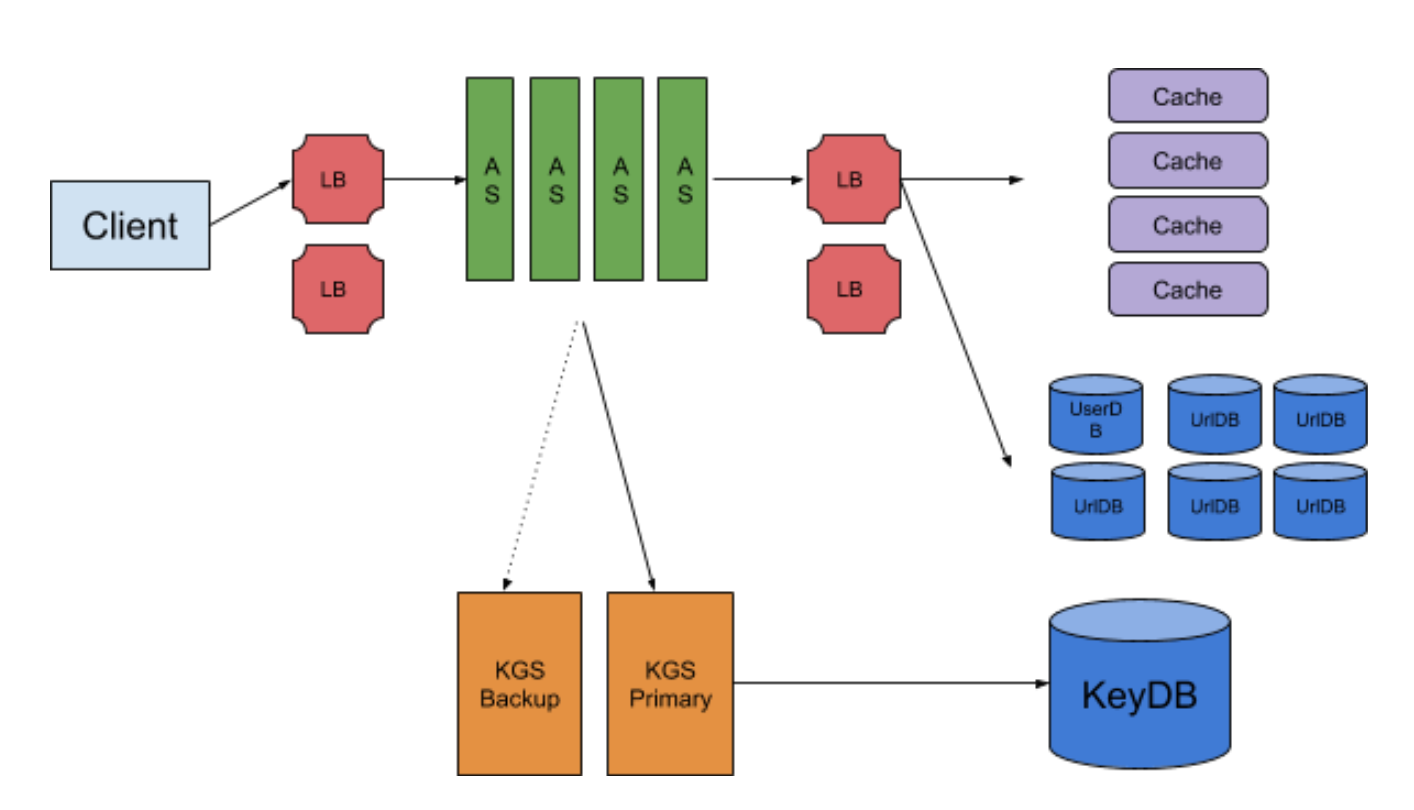
LB
jyt0532: 哪邊可以加上LB呢
迷途書僮: 基本上LB就是一個Reverse Proxy 所以只要底層的機器有多台的都可以上LB
當然別忘了LB本身也要避免Single point of failure的問題
處理過期數據
jyt0532:很好 接下來處理過期的數據 今天如果有數據過期了 你要怎麼處理
迷途書僮: 我們並沒有說一過期的那個瞬間就必須從數據庫中刪除 我們只要保證短網址過期後就不要回傳長網址 我們可以寫個offline的程序慢慢刪

每個禮拜跑一次 然後在Traffic每個禮拜最低的時候直接Update Database 當然除了改UrlDB之外 還要把release出來的短網址告訴KeyDB
jyt0532: 為什麼是把請求發給DB而不是發給AS
迷途書僮: 要發給AS也可以 其實發給AS更簡單 我們只需要在AS跟KGS都多實作一個purge endpoint 讓Server成為DataBase唯一的Access point 這樣如果需要debug還可以從WebServer的log找訊息
最大的問題是 我們不想佔用online traffic的bandwidth
jyt0532: 你在每個禮拜Traffic最低的時候跑不行嗎
迷途書僮: 其實你仔細想想 你現在寫的QPS是100/s 那代表你purge的平均QPS也要是100/s 如果你一個禮拜跑一次 你要7倍的QPS才能在一天跑完 我不想讓purge帶給我的AS這麼吃重的流量
分析
jyt0532: 那現在如果使用者想知道有多少人使用過這個短網址 停留了多久等等 怎麼做
迷途書僮: 推薦你讀這篇事務處理系統還是分析系統 既然我們已經ETL了 就直接跑Pig/Hive/Spark隨便你
jyt0532: ETL的延遲太久 通常是兩三天 使用者看不到最即時的資料 怎麼辦
迷途書僮: 念完流處理搞定 再架個MessageQueue就是了
總結
jyt0532: 其實我們討論了兩個解法
一個是Zookeeper
一個是KGS
其實這兩個設計都很好
迷途書僮: 我感覺用Zookeeper方便一些 少一個Key Generating Server 還少一個DB 這樣就省不少開銷了
jyt0532: 這次的Mock interview也讓我學到了不少 有機會的話再來討論其他的題目吧!