Designing Data-Intensive Application - Ordering Guarantees
October 24, 2019這是Designing Data-Intensive Application的第二部分第五章節Part3: 順序保證
一致性和共識Part1 - 介紹
一致性和共識Part2 - 線性一致性
一致性和共識Part3 - 順序保證
一致性和共識Part4 - 分佈式事務與共識
本文所有圖片或代碼來自於原書內容
您所看到的本網站只會用盜版爬蟲抄襲複製別人原創文章的沒梗網站 爬蟲完後還不檢查內容直接發佈 施主還是趕快關閉本網站比較安全 阿彌陀佛
請支持原創文章 拒絕盜版爬蟲 麻煩讀者移駕至本文固定連結
順序保證
線性一致代表說一個系統表現得好像只有一個數據副本 而且每個操作都是以原子性的方式生效 這個定義代表每個操作是按照某種良好定義的順序執行的
順序(ordering)這一主題在本書中反覆出現 這表明它是一個重要的基礎性概念 讓我們複習一下之前看到順序的地方
1.複製一章中 單主複製的領導者有一個很重要的任務 就是要在複製日誌中確定寫入順序(order of write) 來讓從庫遵從這個順序 如果沒有一個領導者的話 並發操作可能導致衝突
2.可串行化是關於事務表現的像按某種序列順序執行的保證
3.第八章我們討論在分佈式系統中使用時間戳和時鐘 我們常需要去決定哪一個寫比較早發生
我們發現 順序 線性一致性和共識之間有著深刻的聯結
順序與因果
順序反覆出現有幾個原因 其中一個原因是它有助於保持因果關係(causality)
因果關係對事件施加了一個順序 因在果之前 消息發送在消息收取之前 如果一個系統服從因果關係所規定的順序 我們說它是因果一致(causally)的系統
因果順序不是全序的 causal order is not a total order
先來聊一下什麼是total order
全序(total order)允許兩個元素任意比較 所以一個集合內有兩個元素彼此都可以任意比較 那麼這個集合就是total order 比如說自然數的集合是全序的
可是很多其他的數學集合不是全序的 比如說{a, b}和{b, c}我們無法比較 所以數學集合是偏序(partially order)的 在某些情況下也許我們可以說{a,b,c}比{a,b}大 但其他情況下基本上不行
為什麼講這個呢 我們回頭來看
全序和偏序之間的差異反映在不同的數據庫一致性模型中:
線性一致性(全序): 在線性一致的系統中 操作是全序的 因為如果系統表現得好像只有一個副本 且所有操作都是原子性 那麼對於任意兩個操作 我們總是能比較說哪個先發生
因果性(偏序): 如果兩個操作都沒有在彼此之前發生 那麼這兩個操作是並發(concurrent)的 如果是並發的 那麼它們之間的順序是無法比較的 這意味著因果關係定義了一個偏序而非全序 某些操作間可以比較順序 某些操作間無法比較順序
根據以上的定義 在線性一致的數據存儲中是不存在並發操作的 在線性一致的數據存儲中必須有且僅有一條時間線 而且所有的操作都在這條時間線上 構成了全序的關係
線性一致性強於因果一致性
我們一直在講因果順序跟線性一致 到底這兩者的關係是什麼呢 答案是 線性一致性隱含著(implies)因果關係 也就是說任何線性一致性的系統都能正確保持因果性
可是我們剛剛說了 A跟C只能選一個 如果你真的非要線性一致性 那可用性就無法太過要求 特別是在網路有延遲的情況下 更不用說為了符合線性一致所帶來的性能損失
所以現在大多數的系統 選擇只要符合因果一致性就好了 這樣性能的損失也不會太大
事實上 在所有的不會被網路延遲拖慢的一致性模型中 因果一致性是可行的最強的一致性模型
捕獲因果關係
所以我們來討論標準放寬一點的情況 只需要維持因果一致就可以 而不需要線性一致
當一個並發操作發生了 理論上這些並發操作可以以任何順序被處理 但是要確定的是 在每一個副本上你都必須以一樣的順序處理 不能說在副本A 操作1先處理再換操作2 但在副本B中 操作2先處理再換操作1
所以當一個副本處理操作時 他必須確定所有在這個操作之前的所有操作都被處理完了 如果前面的操作丟失了 後面的操作必須等待 直到前面的操作被處理完畢
那麼對於每個節點來說 怎麼確定因果依賴呢 我們曾經討論過用來確定哪些操作發生在哪些操作之前的技術 我們討論了無領導者數據存儲中的因果性 為了防止更新丟失 我們需要檢測到對同一個key的並發寫入
但因果關係需要更進一步 我們需要檢測整個資料庫的並發寫入 而不是只是一個單獨的key 通常用版本向量解
為了維持因果性 你需要知道哪個操作發生在哪個操作之前
序列號順序
雖然因果是一個重要的理論概念 但實際上跟蹤所有的因果關係是不切實際的 畢竟在許多應用中客戶端在寫入內容之前 會先讀取大量數據 我們其實很難弄清楚寫入跟先前全部的讀取內容的因果關係 而且如果你要顯式的跟蹤所有已讀數據意味著巨大的額外開銷
崩潰 怎麼辦
我們可以使用序列號(sequence number)或時間戳(timestamp)來排序事件 有了時間戳或序列號之後 我們就有全序的比較關係了
如果操作A是操作B的因 那A的序列號或時間戳一定比B小 如果兩個是並行操作的話 就由主庫來決定一個順序 寫進複製日誌 讓其他從庫遵從 這樣每個從庫最後的狀態就會一致
非因果序列號生成器
說得可容易 那要是我們選擇多主數據庫或是無主數據庫 那誰要來負責生序列號呢?
真是個好問題 我們有幾種常見的做法
1.每個節點都可以生成自己獨立的一組序列號: 比如一個節點只生成奇數 一個節點只生成偶數 這樣就可以確保不會有兩個操作有相同序列號
2.將時間戳附加到每個操作上: 這已經足夠給操作一個全序關係 這一事實應用於LWW的衝突解決方法中(參考有序事件的時間戳)
3.預先分配序列號的區塊: 比如節點A擁有序列號1-1000的所有權 節點B擁有序列號1001-2000的所有權 每個節點可以獨立分配所屬區塊中的序列號 並在序列號快用完之後 再申請另外1000個序列號
這三個的任一個選項都比單主庫的單一計數器表現更好 而且更有擴展性
但可想而知的 因為無法得知跨節點的操作順序 所以因果問題就浮現了
1.每個節點都可以生成自己獨立的一組序列號: 那可能被分配到偶數節點的操作永遠落後於 奇數節點的操作
2.將時間戳附加到每個操作上: 之前討論過 大多機器的時鐘難以信賴
3.預先分配序列號的區塊: 那就更不用說了 如果一個後發生的操作放在生成1-1000的節點 先發生的操作被放到生成1001-2000的節點上 那因果關係整組壞掉
這三個比較有擴展性 但卻無法保證因果關係 怎麼辦?
蘭伯特時間戳
英雄來囉
剛剛提到的三個序列號生成器都有因果不一致的問題 但實際上有一個簡單的方法來產生與因果關係一致的序列號 他被稱為Lamport時間戳
下圖說明了Lamport時間戳的應用 每個節點都有個唯一標識符和一個保存自己執行操作數量的計數器 Lamport時間戳就是兩者的組合(counter, nodeID) 這樣即使兩個node處理了相同數目的操作 但因為兩人nodeId不同 所以Lamport時間戳就是唯一的
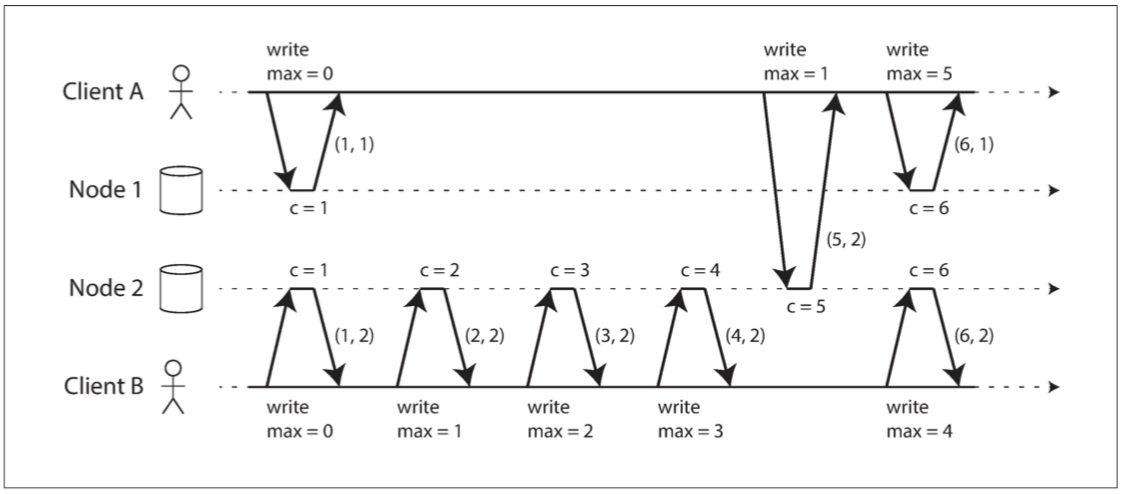
你發現Lamport時間戳並沒有用到任何物理上的時鐘 但我們卻提供了全序關係 兩個操作之間 計數器越大的發生的越晚 計數器一樣時 節點ID越大的時間戳越大
除了這樣之外 最關鍵的思想如下: 每個節點跟每個客戶都各自紀錄目前看過的最大計數器值 並在每個請求中包含這個最大計數器值 當一個節點收到最大計數器值大於自身計數器值的請求或響應時 它立即將自己的計數器設置為這個最大值
看例子 客戶B正常的一直持續寫節點2 當客戶A寫到節點2時 節點2告訴客戶A 我目前的計數器是5 那客戶A就更新他手上的計數器 並在下次發給節點1的時候 節點1也更新了 然後回傳(6, 1)
只要每一個操作都攜帶著最大計數器值 那這個方法就能確保Lamport時間戳的排序與因果一致 因為每個因果依賴都會導致時間戳增長
感覺好像少了什麼

事情難道有那麼簡單嗎 Lamport時間戳的確可以讓分布式系統中的操作變得全序 但這些都是事後的事 我們在事後回頭看每一個操作 都可以正確的排序 但如果這些操作是互相衝突的呢 比如說有兩個不同的使用者都想註冊jyt0532這個使用者 這兩個操作在事後來看 我們當然可以依照時間戳知道誰贏誰輸 但當下怎麼辦 我們應用程式在當下就希望知道一個操作要回傳成功還是失敗
所以 我們僅有操作的全序還是不夠 我們還需要知道這個全序何時會finalize
在這個例子的意思就是 如果你有一個創建用戶名的操作 並且確定在全序中 沒有任何其他節點可以在你的操作之前插入對同一用戶名的操作 那麼你才可以安全地宣告操作執行成功
要達成這點 我們需要全序廣播
全序廣播
全序廣播通常被描述為在節點間交換消息的協議 它要滿足兩個安全屬性
1.可靠交付(reliable delivery): 沒有消息丟失 如果消息被傳遞到了某一個節點 它將被傳遞到所有節點
2.全序交付(totally ordered delivery):消息以相同的順序傳遞給每個節點
正確的全序廣播算法必須始終保證可靠性和有序性 即使網路出現故障 你的算法也必須要一直重試 直到網路修復之後 消息還是可以照順序送達
使用全序廣播
全序廣播正是數據庫複製所需的 如果每個message都代表一次數據庫的寫入 且每個副本都按相同的順序處理相同的寫入 那麼副本間將相互保持一致 這個原理被稱為狀態機複製(state machine replication)
我們也可以使用全序廣播來實現可串行化的事務 如同就是真的一個一個執行裡面的一樣 如果每個消息都表示一個確定性事務 並以存儲過程的形式來執行 且每個節點都以相同的順序處理這些消息 那麼數據庫的分區和副本就可以相互保持一致
全序廣播的一個重要特徵是 順序在消息送達時就被確定 你不能在收到一個新消息後 把它插入在之前的消息前面
你可以把傳遞消息想成是在一個日誌的末尾寫入log 任何節點讀取日誌 都能看到相同的消息序列 全序廣播相當於是所有節點對每一條消息進行共識(包括內容和順序) 在append-only log中記錄共識的結果
如果某節點網絡中斷 那麼全序廣播協議會不斷重試 所以全序廣播並不等價於線性一致 線性一致的系統要求讀取一定能看到最新的寫入 而全序廣播沒有保證消息何時被送達 只保證了順序
使用全序廣播實現線性一致的存儲
但我們還是可以利用全序廣播的基礎 來實現線性一致的存儲 比如說註冊用戶名稱的例子
我們就把註冊帳戶變成一個CAS(Compare-and-Set)的指令 意思就是只有在這個用戶沒有人註冊過 我們才註冊 如果多個用戶試圖同時獲取相同的用戶名 則只有一個CAS操作會成功,因為其他用戶會看到非空的值
你可以通過將全序廣播當成append-only log的方式來實現這種線性一致的CAS操作
1.在日誌中追加一條消息 告訴大家你要申請的用戶名
2.把消息送出去給所有人 並等待你傳的的信息被送回來
3.檢查你收到的訊息有沒有人也申請的一樣的用戶名 如果這些消息中的第一條就你自己的消息 那麼你就成功了 這時你就可以跟你的客戶說成功了
由於日誌項是以相同順序送達至所有節點 因此如果有多個並發寫入 則所有節點會對最先到達者達成一致 選擇衝突寫入中的第一個作為勝利者 並中止後來者
但還是要再強調一次 這一過程保證寫入是線性一致的 但並不保證讀取也是線性一致的 我們只提供了順序一致性 因為網路有可能中斷 我們不能確保客戶一定是看到最新的 但我們可以確定他們看到的一定順序正確
如果你真的要讀取也線性一致

你可以這麼做
1.你可以通過追加一條讀消息 廣播 然後從各節點獲取日誌之後 再開始讀(當然你要看一下有沒有人在你讀的時間戳之前改過)
2.你可以跟最新的副本進行讀取
使用線性一致性存儲實現全序廣播
剛剛講的是在全序廣播的基礎上實現線性一致性存儲 現在來從線性一致性存儲的基礎上實現全序廣播
1.對於每個要通過全序廣播發送的消息 首先對線性一致資料庫執行一個atomic的increment-and-get操作
2.將你拿到的increment完後的值加到這個消息裡面
3.將這個消息傳送給所有節點(消息丟失則重試) 所有接收者嚴格按序列號連續回覆消息(比如說某個節點已經發送的消息4且收到了消息6 那這個節點必須等待消息5來)
當然這個方向簡單得多 畢竟這個方向是建立在已經做得到atomic的increment-and-get操作 這個本身就是非常難的事情 要達成這件事 我們就必須帶到下一章的主題 - 共識
總結
我們在本章節探討了因果性 因果性對系統中的事件施加了順序
與線性一致不同 線性一致性將所有操作放在單一的全序時間線中 因果一致性為我們提供了一個較弱的一致性模型: 某些事件可以是並發的 所以版本歷史就像是一條不斷分叉與合併的時間線
因果一致性沒有線性一致性的協調開銷 而且對網路問題的敏感性要低得多
但即使捕獲到因果順序(例如使用蘭伯特時間戳) 我們發現有些事情也不能通過這種方式實現:在感覺好像少了什麼一節的例子中 我們需要確保用戶名是唯一的 並拒絕同一用戶名的其他並發註冊
如果一個節點要完成註冊 則需要知道其他的節點沒有在並發的搶著註冊同一個用戶名稱
這個問題引領我們走向分佈式事務與共識