Designing Data-Intensive Application - Linearizability
October 17, 2019這是Designing Data-Intensive Application的第二部分第五章節Part2: 線性一致性
一致性和共識Part1 - 介紹
一致性和共識Part2 - 線性一致性
一致性和共識Part3 - 順序保證
一致性和共識Part4 - 分佈式事務與共識
本文所有圖片或代碼來自於原書內容
您所看到的本網站只會用盜版爬蟲抄襲複製別人原創文章的沒梗網站 爬蟲完後還不檢查內容直接發佈 施主還是趕快關閉本網站比較安全 阿彌陀佛
請支持原創文章 拒絕盜版爬蟲 麻煩讀者移駕至本文固定連結
線性一致性
在最終一致的數據庫中 如果你在同一時刻問兩個不同副本相同的問題 可能會得到兩個不同的答案 這很讓人困惑 如果數據庫可以提供數據庫只有一個副本的假象 那麼事情就簡單太多了 那麼每個客戶端都會有相同的數據視圖,且不必擔心replication delay
這就是線性一致性(linearizability)背後的想法 又稱也稱為原子一致性(atomic consistency) 或強一致性(strong consistency) 或立即一致性(immediate consistency) 或外部一致性(external consistency) 基本的想法是讓一個系統看起來好像只有一個數據副本 而且所有的操作都是原子性的
當我們給了應用程式這層抽象 應用程式就像是解開封印 在一個線性一致的系統中 只要一個客戶端成功完成寫操作 所有客戶端從數據庫中讀取數據必須能夠看到剛剛寫入的值
讓應用程式感覺維護數據的副本只有一個 代表說系統能保障讀到的值是最近的/最新的 而不是來自陳舊的緩存或副本 所以線性一致性也是一個新鮮度保證(recency guarantee)
我們來看一個非線性一致系統的例子
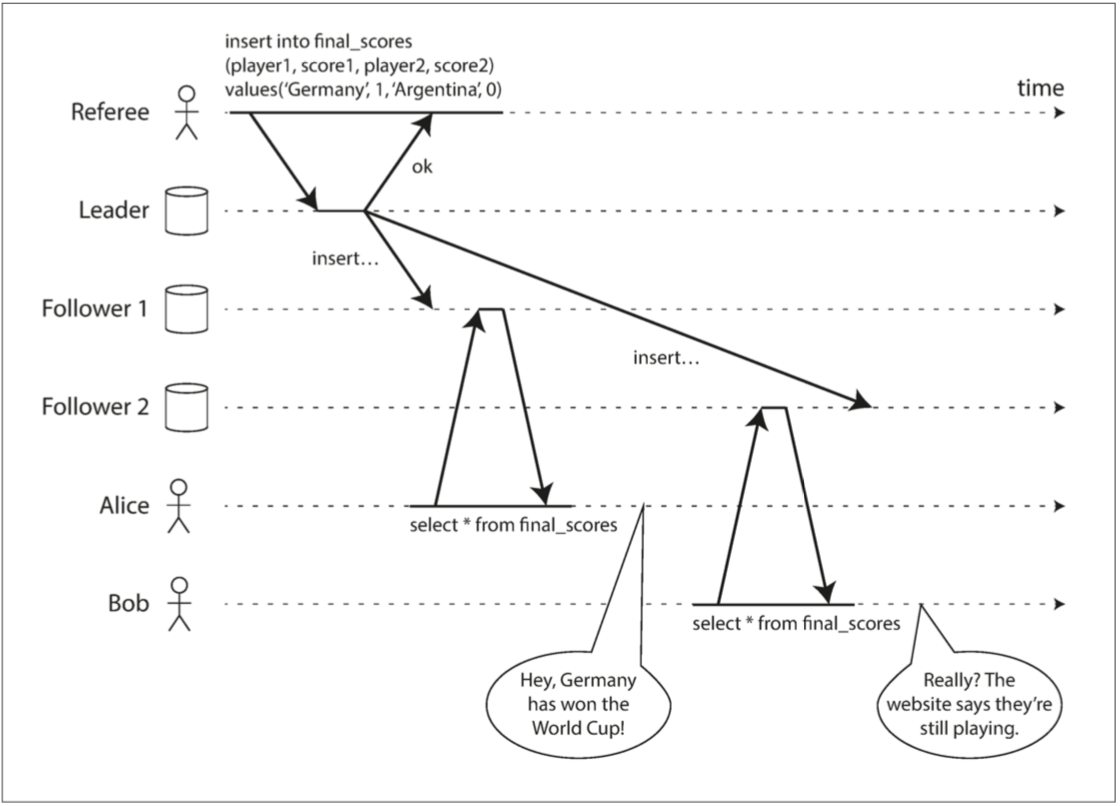
Alice和Bob正坐在同一個房間裡盯著各自的手機 關注著2014年FIFA世界盃決賽的結果 在最後得分公佈後 Alice刷新頁面看到宣佈了獲勝者 興奮地告訴Bob Bob卻難以置信地刷新了自己的手機,但他的請求被倒到了一個落後的數據庫副本上 手機顯示比賽仍在進行
如果Alice和Bob在同一時間刷新並獲得了兩個不同的查詢結果那就算了 但Bob是在聽到Alice驚呼最後得分之後 點擊了刷新按鈕(啟動了他的查詢) 因此他希望查詢結果至少與愛麗絲一樣新 但他的查詢返回了陳舊結果 這一事實違背了線性一致性的要求
如何滿足線性一致
線性一致性背後的基本思想很簡單 使系統看起來只有一個副本 但實際實現起來卻非常的複雜 我們先來看何謂滿足線性一致
下圖表示了三個客戶在同時讀寫線性一致的數據庫的同一個值 在分布式系統的文獻中 x代表register(暫存器) 但在現實生活中可以理解為key-value存儲的key 或是RMDB的一行 或是document-based數據庫的一個document
每個長方形代表一個請求 長方形的左側代表客戶發送請求的時間 長方形的右側代表客戶收到響應的時間 因為網路可能延遲 所以客戶本身並不知道是在長方形的哪個時候真正跟數據庫訪問 只知道是在長方形之間
在這個例子中 客戶有兩種不同請求
1.read(x) => v: 客戶請求讀取暫存器 x 的值 數據庫返回 v
2.`write(x,v): 表示客戶端請求將寄存器 x 設置為值 v
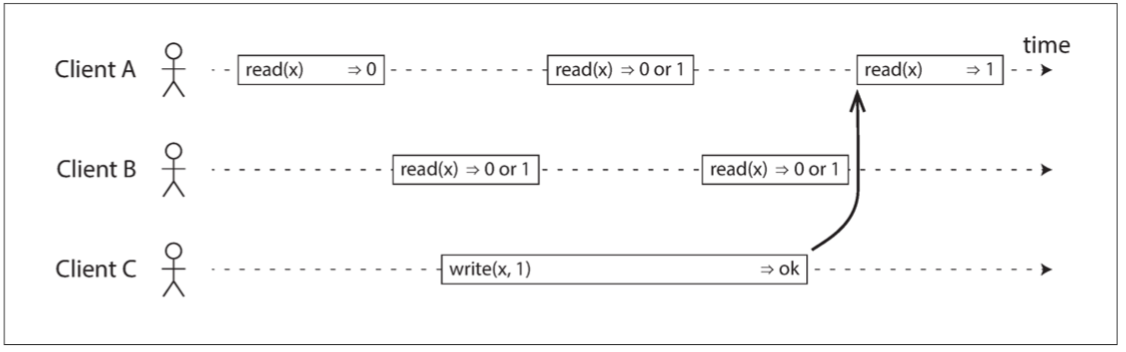
上圖中 x的值最初為0 客戶C執行寫請求將其設置為1 而發生這件事的前後 客戶A跟客戶B一直在同時讀取x
1.客戶端A的第一個讀操作 完成於寫操作開始之前 因此必須返回舊值0 沒有爭議
2.客戶端A的最後一個讀操作 開始於寫操作完成之後 如果數據庫是線性一致性的 它必然返回新值1 沒有爭議
3.與寫操作在時間上重疊的任何讀操作 可能會返回 0 或 1 因為我們不知道讀取時 寫操作是否已經生效 因為這些操作是並發(concurrent)的
那這樣就搞定了嗎? 除了客戶端A的第一個讀操作回傳0和客戶端A的最後一個讀操作回傳1之外 其他都隨便 就可以達到線性一致了嗎?? 如果回傳的結果長這樣呢
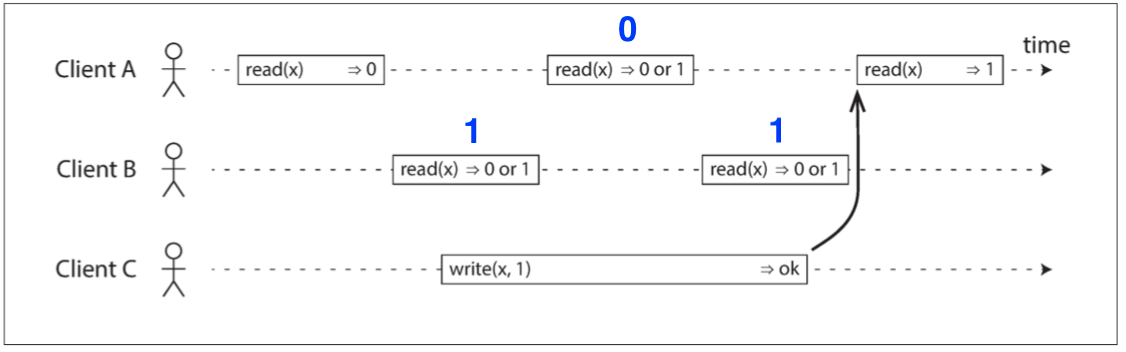
這樣就長得不像是”看起來只有一個副本”的樣子

所以我們需要再加一個約束 那就是 任何一個讀取返回新值後 所有後續讀取(在相同或其他客戶端上)也必須返回新值
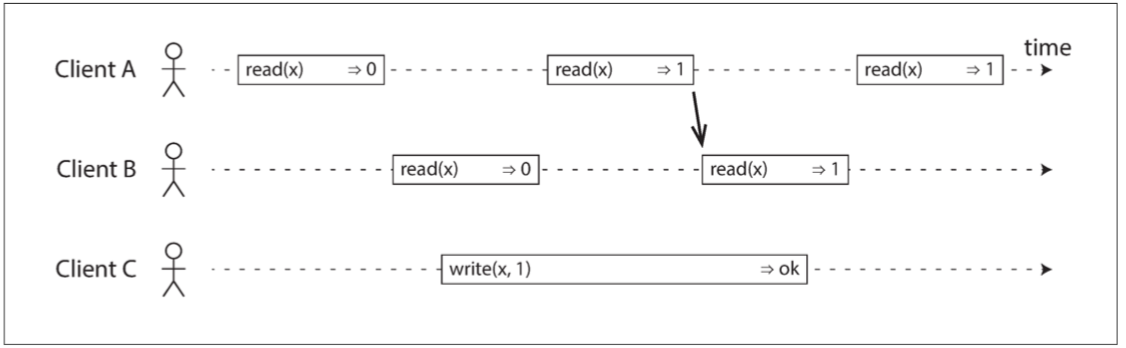
上圖的箭頭說明了這個時序依賴的關係 客戶端A 是第一個讀取新的值 1 的客戶 由於B的讀取嚴格在發生於A的讀取之後 因此即使C的寫入仍在進行中 B的讀取也必須返回 1
我們可以更細化這個例子 在那之前 我們多導入一個操作比較並設置
3.cas(x,v_old, v_new): 如果 x = v_old, 將寄存器 x 設置為值 v_new 不然就返回錯誤
長方條裡面真正在資料庫被執行的時候 我們畫上粗線 並且投影到DataBase的軸上
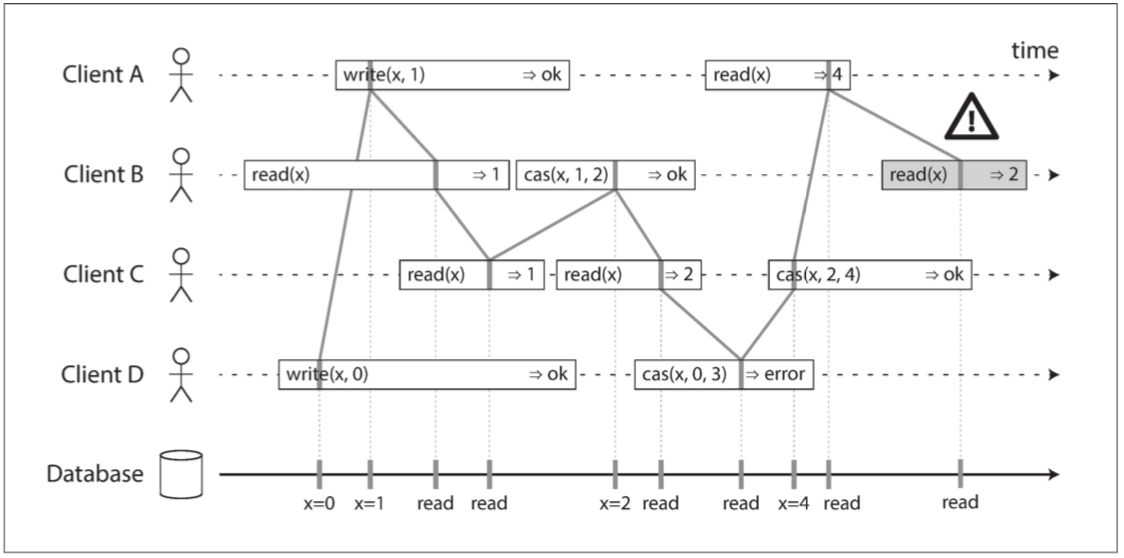
線性一致性的要求是 操作標記的連線總是按時間由左向右移動 這給了我們新鮮度保證: 一旦新的值被寫入或讀取 所有後續的讀都會看到寫入的值
有一些細節值得好好說明
1.雖然對於A,B,D的第一個請求來說 請求開始的時間是B -> D -> A 但真正執行的時候卻是D -> A -> B 數據庫先處理了D的寫 再處理A的寫 再處理B的讀 雖然這跟請求發送的順序不一樣 但這卻是一個對於滿足線性一致性的系統來說 可以接受的順序 畢竟這三個請求是並發的 也許B的網路有延遲你也不能怪我
2.在客戶端A從數據庫收到響應之前 客戶端B的讀就已經返回 1 了 這也是可以的 但不代表在寫之前就讀到了值 這只是意味著從數據庫到客戶端A的正確響應在網路中略有延遲
3.此模型不假設有任何事務隔離 另一個客戶端可能隨時更改值 在這個例子裡 C先讀到1 再讀到2 因為值被B改了 那要怎麼知道你改的值對不對呢 這就是為什麼需要較並設置(compare-and-set)操作來檢查該值是否未被另一客戶端同時更改 在這個例子 B跟C的cas操作成功 但D的cas失敗了 因為當D想改的時候 x已經不是0了
4.注意B的最後一次讀取 因為A已經讀過這個值而且讀到4了 所以B這個明顯比A的結束還晚開始讀的請求一定要是4 不然就不滿足線性一致 比如說 如果沒有A的最後的讀請求 那B最後的讀要回傳2還是回傳4 這個系統都滿足線性一致性
這樣你 理解了嗎?
線性一致性與可串行化
很多人會把線性一致性跟可串行化混淆 因為兩個詞似乎都是”可以按順序排列”的意思 但這兩個是完全不同的概念
可串行化: 是事務的隔離屬性 每個事務可以讀寫多個對象(row, document, record) 它確保事務的行為 與它們按照某種順序依次執行的結果相同
線性一致性: 是讀取和寫入對象的新鮮度保證
一個數據庫可以同時提供可串行化和線性一致性 這種組合稱為strict serializability或是strong one-copy serializability
我們討論過可串行化的實現有三種
2.兩階段鎖定
3.串行化快照隔離
前兩者通常是線性一致性的 而串行化快照隔離不是 記得一致性快照的要點就在於它不會包括比快照還要更新的寫入 所以對於快照的讀取就不可能是線性一致
依賴線性一致性
線性一致性在什麼情況下有用呢 剛剛看的體育比賽大概膚淺了點 畢竟過了一下子就會回復正常 但在某些情況 線性一致性是系統正確工作的一個重要條件
鎖定和領導選舉
一個使用單主複製的系統 需要確保領導真的只有一個而不是多個 一種常見的選擇領導者的方法是使用鎖 每個節點在啟動時嘗試獲取鎖 成功者就成為領導者 你可以很直覺的了解 不管這個鎖是怎麼實現的 他必須要是線性一致: 每個節點對於誰現在擁有鎖有一致的共識
約束和唯一性保證
唯一性約束在數據庫中很常見 比如說一個用戶名或電子郵件地址必須唯一標識一個用戶 或是文件存儲服務中 不能有兩個文件有著一樣的路徑名稱 如果要在寫入數據時強制執行此約束 就需要線性一致性
這種情況其實跟鎖很像 當一個用戶註冊了新的用戶名 你可以當作這個用戶名的鎖被拿了 而線性一致性保證鎖一次只有一個人可以拿
還有如果要保證銀行餘額永遠不是負數 或是不能超賣比倉庫還多的物品 這些約束條件都需要所有節點同意一個最新的值
實現線性一致的系統
看完了一些依賴線性一致系統的範例後 現在來討論怎麼實現
我們說過 線性一致性的本質就是表現得好像只有一個數據副本 而且所有的操作都是原子的 那最簡單的方式 就是真的只有一個副本 但最大的問題就是 無法容錯 一個節點掛了就整個服務死掉
所以我們只好再來複習一下我們可愛的複製
單主複製(可能線性一致)
在具有單主複製功能的系統中 主庫具有用於寫入的數據的主副本 而追隨者在其他節點上保留數據的備份副本 所以如果從主庫或同步更新的從庫讀取數據 它們可能是線性一致性的
為什麼是可能呢 因為即使我們都從主庫讀取 也還是依賴一個假設: 我們很確定領導是誰 我們在第八章說過 很可能一個節點已經不是領導了他卻還認為他是 如果具有錯覺的領導者繼續為請求提供服務 那就可能違反線性一致性 而且是異步複製的話 故障切換時甚至可能會丟失已提交的寫入 那就不但違反線性唯一性還違反了持久性(durability)
多主複製(非線性一致)
具有多主程序複製的系統通常不是線性一致的 因為它們同時在多個節點上處理寫入 並將其異步複製到其他節點 因此非常容易產生具有conflict的寫入
無主複製(可能線性一致)
對於無領導者複製的系統 有時候人們會聲稱通過要求法定人數讀寫(w + r > n)就可以獲得強一致性 但這其實取決於法定人數的具體配置以及強一致性如何定義
基於時鐘(參見依賴同步時鐘, Cassandra是個最具代表性的例子)的LWW衝突解決方法幾乎可以確定是非線性的 由於時鐘的偏差 也不能保證時鐘的時間戳與實際事件順序一致 即使你說要使用非常嚴謹的法定人數 還是有可能會有非線性一致的行為
直接看例子 直覺上在Dynamo風格的模型中 嚴格的法定人數讀寫應該是線性一致性的 但這在有網路延遲的情況下不成立 這個例子中 我們設定n = 3, w = 3, r = 2 是個嚴格的法定人數限制
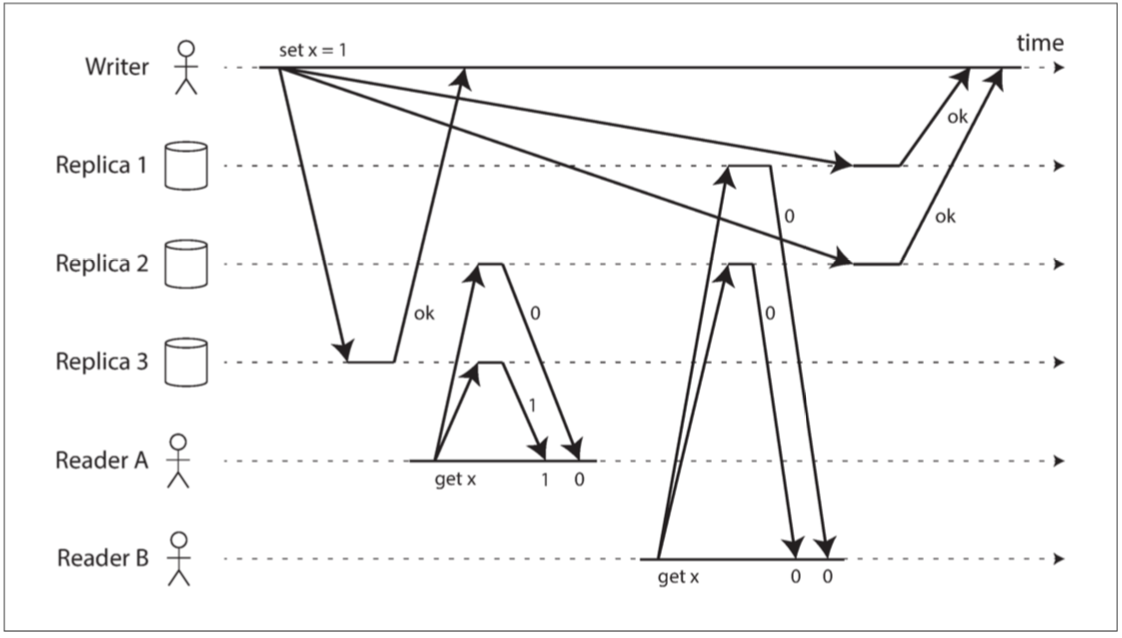
上圖中
x的初始值是0 有人向三個副本都寫入1 只是寫到副本1跟副本2的時候有延遲 現在讀者A讀了其中兩個 發現一個是0一個是1 讀者B讀了其中兩個 發現兩個都是0這個例子可以看得出來 即使我們嚴格規定
w+r>n但這個執行卻還是非線性一致 因為讀者B的請求開始於讀者A的請求結束之後 但是B拿到舊值 A拿到新值當然 你可以犧牲效能來使Dynamo風格的法定人數線性化 做法是讀取者必須在將結果返回給應用之前 同步執行修復
可惜的是 這是在只有”一個人”寫的情況 我們還可以有機會決定犧牲效能達到線性一致 如果是多人寫的話還是不可能線性一致 因為LWW就是需要解衝突
而且也只有一個人”寫”才可能 如果是比較且設置(CAS) 那也不能透過讀者修復達到線性一致
所以安全一點的做法 就是假設採用Dynamo風格無主複製的系統不能提供線性一致性
共識算法(線性一致)
一些在本章後面討論的共識算法 與單領導者複製類似 但是這些共識算法包含防止腦裂(split brain)和陳舊副本的細節 這些細節讓我們可以安全地實現線性一致性存儲 就如同Zookeeper和etcd
線性一致性的代價
我們在第五章中 討論了不同複製方法 以多數據庫而言 多主複製是個不錯的選擇
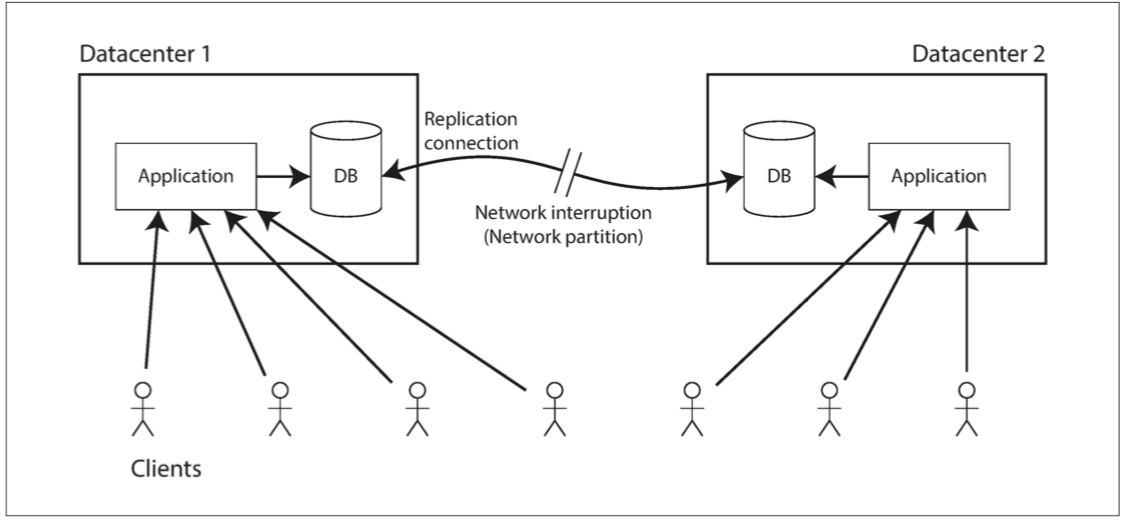
但如果今天兩個數據中心的網路中斷怎麼辦 兩個單獨都還是可以運作 但數據中心之間無法交換資料
在多主複製的情況下 客戶在修改完後 這個修改請求會異步的被傳到另一個資料中心 但因為網路掛了 所以這些請求就會在queue裡排隊 線性一致性無法滿足
在單主複製的情況下 客戶只可以跟主庫要資料 因為從庫的資料很可能已經舊了 既然所有人都只能跟主庫要 那就無法滿足availability
你知道我們下一個小節要提什麼了吧
CAP
所有線性的資料庫系統都面臨著一樣的問題
1.如果應用需要線性一致性 且某些副本因為網路問題與其他副本斷開連接 那麼這些副本掉線時不能處理請求(navailable)
2.如果應用不需要線性一致性 那麼某個副本即使與其他副本斷開連接 也可以獨立處理請求(例如多主複製) 在這種情況下 應用可以在網路問題前保持可用但其行為不是線性一致的
所以對於一個系統 你要馬選擇CP 或是選擇AP
常見的誤導: 很多人說CAP定理指的是CAP只能三選二 其實這樣的說法誤導性很強 因為網路分區並不是個選擇 而網路錯誤是分布式系統的必然 所以CAP正確的說法應該是
either Consistent or Available when Partitioned
線性一致性和網路延遲
雖然線性一致是一個很有用的保證 但實際上線性一致的系統驚人的少 原因很簡單 因為未了達成線性一致 你對每個需求的處理 就必須如本文所說的 多了很多限制
所以現實生活的系統 通常都會放棄線性一致 但主因不是為了容錯 而是為了性能 畢竟線性一致的系統除了慢還是慢(不僅僅是網路不穩定的時候)
Attiya和Welch說了 如果你想要線性一致性 讀寫請求的響應時間至少與網路延遲的不確定性成正比 而大部分的計算機都處在網路速度可變的環境 所以快速的線性一致算法不存在 但更弱的一致性模型可以快得多
總結
我們深入研究了線性一致性: 其目標是使多副本數據看起來好像只有一個副本一樣 並使其上所有操作都原子性地生效
雖然線性一致性因為簡單易懂而很吸引人 它使數據庫表現的好像單線程程序中的一個變量一樣 但它有著速度緩慢的缺點 特別是在網路延遲很大的環境中