Designing Data-Intensive Application - The Trouble with Distributed Systems
October 05, 2019這是Designing Data-Intensive Application的第二部分第四章節: 分佈式系統的麻煩
本文所有圖片或代碼來自於原書內容
您所看到的本網站只會用盜版爬蟲抄襲複製別人原創文章的沒梗網站 爬蟲完後還不檢查內容直接發佈 施主還是趕快關閉本網站比較安全 阿彌陀佛
請支持原創文章 拒絕盜版爬蟲 麻煩讀者移駕至本文固定連結
前言
在前幾章中反覆出現的問題是 系統該如何處理錯誤情況 比如副本故障切換 複製延遲 或是事務控制
即使我們在之前談了很多錯誤 但我們還不夠悲觀 這篇文章我們要把悲觀最大化 假設任何可能出錯的東西都出錯
我們會討論所有分布式系統實踐上可能會遇到的問題 了解哪些東西是我們能依賴的 哪些東西是我們不能過分依賴的
本章對分佈式系統中可能出現的問題進行徹底的悲觀和沮喪的總結 我們會討論
1.網路的問題(不可靠的網路)
2.時鐘和時序問題(不可靠的時鐘)
3.暫停的進程問題(#暫停進程)
4.我們將討論可以怎麼在特定的假設下避免他們的影響 從而得知怎麼思考一個分布式系統的狀態 以及推理會發生的事情
故障與部分失效
單個計算機上的軟件沒有根本性的不可靠原因 當硬體正常工作時 相同的操作總是產生相同的結果 我們稱為deterministic 如果你有硬體上的問題 那你通常會是整個系統故障 所以一個跑軟件的個人計算機 要馬功能完好 要馬整組壞掉 不會介於兩者之間
但如果你是運行在多台計算機上的軟體時 那情況就完全不同 分布式系統並不是理想的模型 很有可能系統的某部分會以不可預知的方式被破壞 我們稱為部分失效(partial failure) 頭痛的地方在於部分失效是不確定性的(nonderterministic)
如果你試圖想做涉及多個節點和網路的事情 這有時會成功有時會失敗 更慘的是如果是網路壞掉 你甚至無法知道你想做的事是否成功了 因為消息通過網路傳播的時間也是不確定的
這種不確定性和部分失效的可能性 使得分佈式系統難以工作
雲計算與超級計算機
關於如何建構一個大型計算機有一個光譜
1.光譜的一端 是使用HPC(High-performance computing) 就是一個擁有數千CPU的超級猛電腦 可以用來計算密集的計算機任務 比如說天氣預報或是分子動力學
2.光譜的另外一端 則是雲計算(cloud computing) 通常是多個數據中心以乙太網路連結 彈性的按照需求/流量計費
3.一般企業使用的數據中心模型就是介於兩者之間
在光譜的不同地方 會導致不同的故障處理方式 在超級計算機的那一端 作業通常會不時地將計算的狀態存盤到持久存儲中 如果一個節點出現故障 通常的解決方案是簡單地停止整個集群的工作負載 故障節點修復後 計算從上一個檢查點重新開始
因此 超級計算機更像是一個單節點計算機而不是分佈式系統 它通過讓部分失敗升級為完全失敗來處理部分失敗
但在本書中 我們希望處理的是互聯網服務的系統 這些系統通常與超級計算機有很多不同
1.許多與互聯網有關的應用程序都是Online的 我們必須要一直available! 讓服務暫停是不可接受的 不像天氣預測的批處理計算 可以隨時停止之後重新啟動
2.超級計算機通常由專用硬件構建而成 每個節點相當可靠 雲服務的節點是由商品機器構建而成的 雖然因為規模經濟一次購買大量比較便宜 但具有較高的故障率
3.超級計算機通常使用專門的網路拓撲結構 例如多維網格和環面 這些為HPC工作負載提供了更好的性能 大型數據中心網路則是基於IP和已太網 以閉合拓撲排列提供更高的二等分帶寬
4.系統越大 其組件之一就越有可能發生變化 當你修好一個壞掉的東西時 別的東西可能也壞了 在一個有成千上萬個節點的系統中 我們可以合理的認為總是有一些東西壞掉了 所以你必須一直分配部分的資源在修理節點上
5.如果系統可以容忍發生故障的節點 並繼續保持整體工作狀態 那麼這對於操作和維護非常有用 比如滾動升級(一次重新啟動一個節點 系統繼續服務用戶不中斷)
6.在地理位置分布部署中(保持數據在地理位置上接近用戶以減少訪問延遲) 通信很可能通過互聯網進行 與本地網路相比 通信速度緩慢且不可靠 超級計算機通常假設它們的所有節點都靠近在一起
如果要使分佈式系統工作 就必須接受部分故障的可能性 並在軟件中建立容錯機制
換句話說 我們需要利用不可靠的組件構建一個可靠的系統 別忘了沒有完美的可靠性 我們需要理解我們可以實際承諾的限制
不可靠的網路
我們在本書中關注的都是無共享的架構 網路就是機器跟機器間唯一的溝通途徑 意思就是說每台機器都不能訪問別台機器的硬碟跟內存
互聯網和數據中心中的大多數內部網路都是異步分組網路(asynchronous packet networks) 在這種網路中 一個節點可以向另一個節點發送一個消息(一個數據包) 但是網路不能保證它什麼時候到達或者是否到達 可能出錯的地方如下
1.請求丟失(有人拔網路線)
2.請求正在queue裡排隊 等待晚點送達(網路超載或收件人超載)
3.遠程節點可能已經失效(崩潰或關機)
4.遠程節點可能暫時停止了響應(垃圾回收暫停等等 參閱暫停進程)
5.遠程節點可能已經處理了請求 但是網路上的響應已經丟失(網路交換機配置錯誤)
6.遠程節點可能已經處理了請求 響應已經被延遲 稍後才會送達(網路超載或寄件人超載)
當你發送一個封包且沒有得到回應 你並不知道是哪步出錯 可能(a)請求丟失 (b)遠端節點關閉 (c)響應丟失
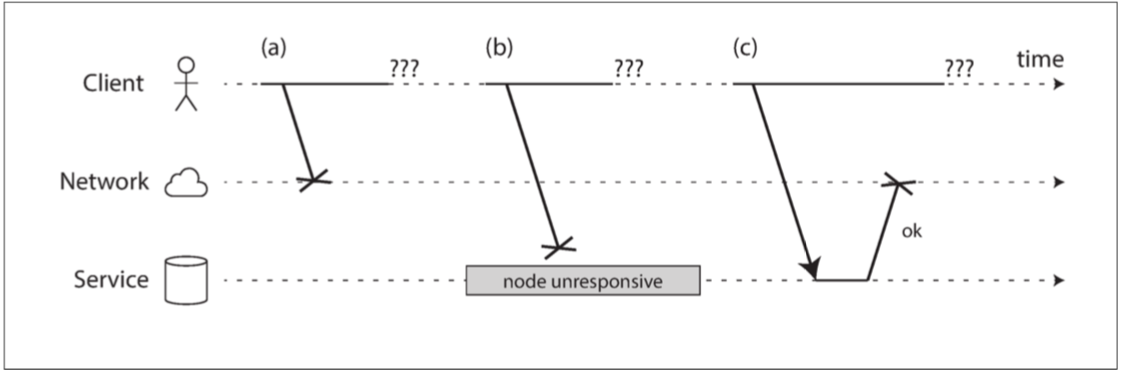
處理這個問題的通常方法是超時(Timeout) 也就是過一段時間沒收到響應就放棄 但也不是放棄就沒事 你並不知道對方有沒有正確地收到這個消息並處理
檢測故障
許多系統需要自動檢測故障節點 比如說
1.負載平衡器需要停止向已死亡的節點發送請求 並把他移出輪值表(out of rotation)
2.單主複製功能的分佈式數據庫中 如果主庫失效 則需要將從庫之一升級為新主庫
不幸的是 因為網路的不確定性 使得你很難判斷一個節點是否工作 但在某些特定的網路故障我們有些明確的feedback
1.如果你可以到達運行節點的機器 但沒有進程正在listen to the port 這我們就可以從HTTP Status Code明確的知道是遠端問題不是網路問題
2.有可能在router那端它就知道你想要連接的ip位置已經死了 那就會給你一個特別的response
總的來說 如果出了什麼問題 你可能會在某個level得到有關錯誤的回應(router level, tcp level, application level) 但一般來說最常見的狀況 就是你根本沒有得到任何回應 你唯一能做的就是重試幾次 每次都timeout的話就基本可以確定對面節點掛了
超時與無窮的延遲
如果超時是檢測故障的唯一可靠方法 那麼超時應該等待多久? 不幸的是這題沒有簡單的答案
超時設定的太短 可能遠端節點只是處理得慢點你就說他掛了 把請求發給別人 到最後這個請求就會被做兩次
而且當你把請求轉移到其他節點時 會給其他節點和網路帶來額外的負擔 特別是那個你以為他死掉的節點 他會讓你覺得死掉很可能就是因為他現在手上的工作太多 你過早宣告他死亡只會讓事情更嚴重 因為他其實沒死掉 但你把他的工作交給別人 然後你就會以為別人死掉 然後就一連串的一個接一個真的死掉 我們稱為cascading failure
來一點可愛的參數吧!
d: 網路可以保證一個數據被傳遞的最大延遲 每個數據包要碼在d內傳送 要麼丟失 但是傳遞永遠不會比d更長
r: 保證一個非故障節點總是在r時間內處理一個請求
在這種情況下 你就可以保證每個成功的請求在2d + r時間內都能收到響應 如果您在此時間內沒有收到響應 你就可以說網路或遠程節點掛了
網路擁塞和排隊
計算機網路上數據包延遲的變數通常是由於排隊 而且有不少地方需要排隊
1.如果多個不同的節點同時嘗試將數據包發送到同一目的地 則網路交換機必須將它們排隊並將它們逐個送入目標
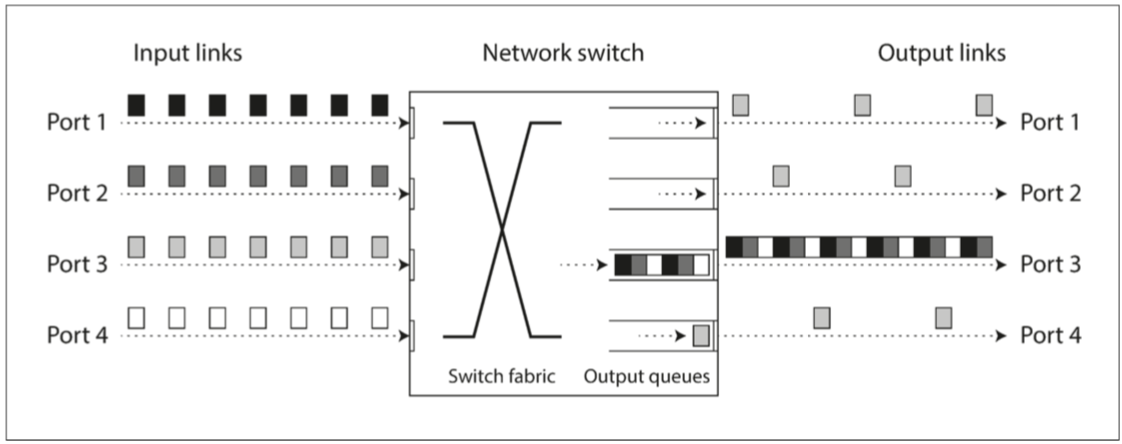
在請求很多的時候 數據包可能需要等待一段時間才能獲得一個插槽slot 如果傳入的數據太多 交換機隊列已經被填滿的話 數據包將被丟棄(需要重新發送數據包) 即使是在網路運作良好正常的情況下
2.而且當數據包到達目標機器時 如果所有CPU內核當前都處於繁忙狀態 則來自網路的傳入請求將被送到操作系統排隊 直到應用程序準備好處理它為止
3.在虛擬化環境中 正在運行的操作系統經常暫停幾十毫秒 由另一個虛擬機使用CPU內核 在這段時間內,虛擬機不能從網路中消耗任何數據 所以傳入的數據也需要排隊
4.TCP執行流量控制(flow control) 也稱為擁塞避免(congestion avoidance)或背壓(backpressure) 其中發送節點限制自己的發送速率以避免網路或接收節點過載
TCP vs UDP
一些對延遲敏感的應用程序(視訊 講電話等等) 使用UDP而不是TCP 這是在可靠性和和延遲可變性之間的折衷 由於UDP不執行流量控制並且不重傳丟失的分組 所以避免了可變網路延遲的一些原因
以上提的這些因素都會造成網路延遲的變化 通常你需要透過不斷的實驗 來測量延長的網路往返時間和多台機器的分佈 再考慮應用程序的特性 來決定故障檢測延遲與過早超時風險之間的適當折衷
延遲和資源利用 Latency and Resource Utilization
你可以把延遲變化(variable delays)視為動態資源分區(dynamic resource partitioning)的結果
假設兩台電話交換機之間有一條線路 可以同時進行10000個呼叫 通過此線路切換的每個電路都佔用其中一個呼叫插槽 因此 您可以將線路視為可由多達10000個並發用戶共享的資源 資源以靜態方式分配: 意思就是即使您現在是電話上唯一的電話 並且其他9999個插槽都未使用 您的電路仍將分配與所有插槽都被使用時相同的固定數量的帶寬
相比之下 互聯網動態分享網路帶寬 發送者互相推擠來儘可能快地通過網路傳送 這種方法最大的好處就是無時無刻都最大化了資源的使用
CPU也會出現類似的情況 如果您在多個線程間動態共享每個CPU內核 則有一個線程有時必須等待操作系統的運行隊列 而另一個線程正在運行 這樣線程可以暫停不同的時間長度 但跟每個線程分配靜態數量的CPU週期相比 這會更好地利用硬件 而更好的硬件利用率也是使用虛擬機的重要動機
如果資源是靜態分區的(專用帶寬分配) 則在某些環境中可以實現延遲保證(就是我保證多久可以送的到) 但是 這是以降低利用率為代價的 換句話說就是比較昂貴
另一方面 動態資源分配的多租戶提供了更好的利用率 所以它更便宜 但它具有可變延遲的缺點
網路中的可變延遲不是一種自然規律 而只是成本/收益權衡的選擇
不可靠的時鐘(Clock)
應用程序以各種方式依賴於時鐘來回答以下問題
1.這個請求是否超時
2.這項服務的P99是多少
3.在過去五分鐘內 該服務平均每秒處理多少個查詢
4.用戶在我們的網站上花了多長時間
5.這篇文章在何時發佈
6.在什麼時間發送提醒郵件
7.這個緩存何時到期
8.日誌文件中此錯誤消息的時間戳是什麼
前四項測量的是持續的時間 後四項測量的是一個明確的時間點
在分佈式系統中 時間是一件棘手的事情 因為通信不是即時的 消息通過網路從一台機器傳送到另一台機器需要時間(收到消息的時間總是晚於發送的時間) 但網路上的每台機器都有自己的時鐘 這是一個實際的硬件設備(通常是石英晶體振盪器) 這些設備不是完全準確的 每台機器都還會有自己的時間概念 可能比其他機器稍快或更慢
我們可以利用網路時間協議(NTP)一定程度上同步時鐘 它允許根據一組服務器報告的時間來調整計算機時鐘
單調鐘(Monotonic clock)與時鐘(Time-of-day clock)
現代計算機至少有兩種不同的時鐘: 時鐘和單調鐘 儘管它們都衡量時間 但區分這兩者很重要
時鐘Time-of-day clock
時鐘是你直觀地瞭解時間的依據: 它根據某個日曆(wall-clock time) 返回當前日期和時間 比如Linux的clock_gettime(CLOCK_REALTIME)或Java的System.currentTimeMillis()
單調鐘 Monotonic clock
單調鐘適用於測量持續時間(時間間隔) 比如超時或服務的響應時間
Linux的clock_gettime(CLOCK_MONOTONIC) 或Java的System.nanoTime()都是單調鐘 單調鐘的意思是 它們保證總是前進的事實(而Time-of-day clock有可能會被往回調)
你可以在某個時間點檢查單調鐘的值 做一些事情 且稍後再次檢查它 這兩個值之間的差異告訴你兩次檢查之間經過了多長時間
注意!單調鐘的絕對值是毫無意義的: 它可能是計算機啟動以來的秒數 或類似的任意值 特別是比較來自兩台不同計算機的單調鐘的值是沒有意義的 因為它們並不是一回事 比如開始計算的時間根本不一樣
如果NTP協議檢測到計算機的本地石英鍾比NTP服務器要更快或更慢 則可以調整單調鐘向前走的頻率(稱為slewing the clock) 預設情況是可以讓時鐘速率加快或減慢5%(但不能突然往前跳或往後跳)
在分佈式系統中 使用單調鐘測量經過時間(elapsed time)(比如超時)通常效果很好,因為它不假定不同節點的時鐘之間存在任何同步 並且對測量的輕微不準確性不敏感
邏輯時鐘Logical Clock
Time-of-day clock和Monotonic clock也被稱為物理時鐘 還有一種是邏輯時鐘 它是基於遞增計數器而不是振盪石英晶體 對於排序事件來說是更安全的選擇 邏輯時鐘不測量一天中的時間或經過的秒數 而僅測量事件的相對順序(無論一個事件發生在另一個事件之前還是之後)
時鐘同步與準確性
Monotonic clock不需要同步 但Time-of-day clock就需要根據NTP服務器來對時 不幸的是 利用NTP對時沒有想像中的那麼簡單 基於以下幾個原因:
1.計算機中的石英鍾不夠精確 它會漂移(drifts): 運行速度比預期快或是慢 取決時機器的溫度 漂移的數字是多少呢 Google假設其服務器時鐘漂移為200ppm(10^-6) 也就是每過30秒 就是飄移6ms
2.如果計算機的時鐘與NTP服務器的時鐘差別太大 計算機時鐘會拒絕同步 或是強制重置 如果剛好在這段時間有軟件在觀察時間的話會看到時間倒退或時間跳耀
3.NTP的準確度還被網路的延遲給限制 當你透過互聯網同步 最小的誤差就是35ms
4.閏秒會導致某分鐘只有59秒或是61秒 在過去閏秒已經讓不少系統崩潰過
5.一個軟件甚至不能完全相信硬件上的時鐘 比如有人為了手機遊戲的某個app拿獎金 可以作弊調整手機時間等等
眾多的理由讓我們相信同步時間是挺困難的
依賴同步時鐘
關於時鐘最大的問題 就是他們看起來很直觀 基本上不會出什麼錯 可是麻煩的地方在於 一天可能不會有精確的86400秒 時鐘可能會前後跳躍 更慘的是當時鐘出錯的時候很容易會被視而不見
如果是一個機器的CPU出錯或是網路出錯 可能根本就無法工作 所以很快就會有人來修 但如果是時鐘出錯 大部分事情都還可以正常運作 即使時鐘是很慢很慢的越差越多 那麼一個依賴於時鐘的軟件可能會就會無聲無息的一直做錯的事情 很久後才被注意到 而不是一次性的大崩潰
因此 如果你使用需要同步時鐘的軟件 必須仔細監控所有機器之間的時鐘偏移 時鐘偏離其他時鐘太遠的節點應當被宣告死亡 並從集群中移除
這樣的監控可以確保你在損失發生之前注意到破損的時鐘
有序事件的時間戳
考慮一個很依賴時鐘的程序 - 依賴時鐘來對節點的事件進行排序 比如說有兩個客戶端同時寫入分布式數據庫 誰先到達?
在這個例子裡 Node3的時間慢了0.003秒
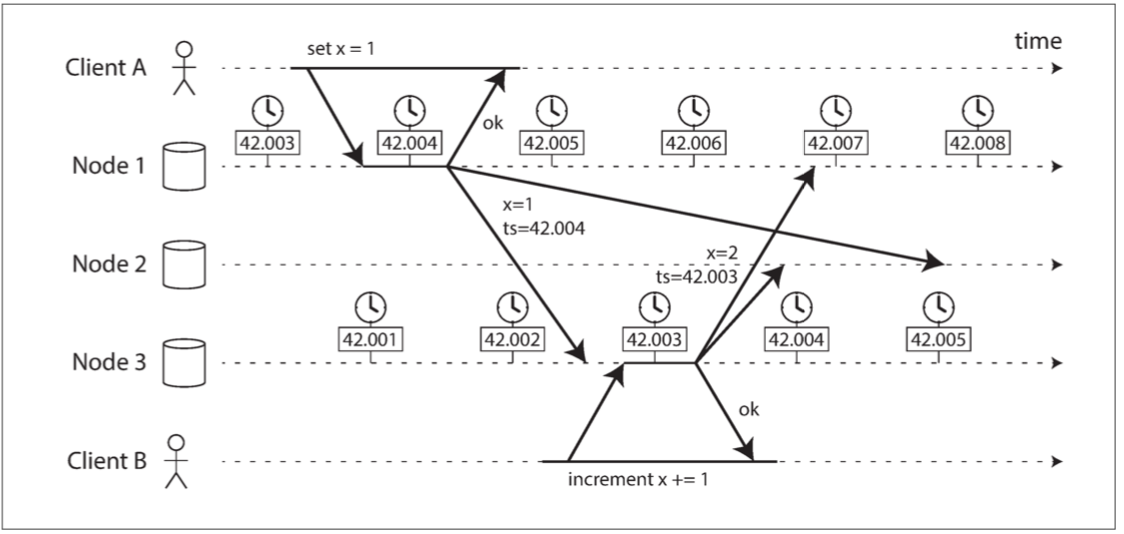
首先 客戶A先在Node1寫了x=1 寫入被複製到Node2跟Node3
此時客戶B在節點3寫了x++ 然後再被複製到Node1跟Node2 注意客戶B的寫入比較早到達Node2
對Node2而言 他發現兩個寫入 一個發生在42.004 一個發生在42.003 那這時候Node2怎麼辦呢 一個常見的解法是LWW(last writer win) 很暴力的捨棄客戶B的寫入
雖然LWW是很常見的解法 但還是有不少問題
1.一個時鐘落後的節點 他的寫入很常被忽視 直到這個時鐘被校準 在那之前很多寫入自然而然地被忽視也不會有人發現
2.LWW無法區分真正高頻的寫入跟並發寫入 需要額外的因果關係跟蹤機制 請參考檢測並發寫入
3.兩個節點還是可能可以獨立生成具有相同時間戳的寫入 這時就需要一個隨機數來決定誰贏
儘管通過保留最最近的值並放棄其他值來解決衝突是很誘惑人的 但是要注意 最近的定義取決於本地的時鐘 這很可能是不正確的
時鐘讀數存在信賴區間
您可能能夠以微秒或甚至納秒的分辨率讀取機器的時鐘 但將時鐘讀數視為一個時間點是沒有意義的 它更像是一段時間範圍 比如一個clock_gettime() 應該不是回傳一個0.4 應該回傳 [0.3, 0.5] 可惜的是大多數的系統不公開這種不確定性 跟你說多少就是多少
Spanner中的Google TrueTime API 明確的告訴了你本地時鐘的信賴區間 當你跟他問時間時 他會告訴你最早跟最晚 至於區間有多大取決於他上次跟準確的來源對時已經過了多久
全局快照的同步時鐘
我們曾經討論過快照隔離 可以支持小型的快速讀寫事務 和大型的讀事務(用於備份或分析) 它允許只讀事務看到特定時間點的處於一致狀態的數據庫 且不會鎖定和干擾讀寫事務
快照隔離最常見的實現需要單調遞增的事務ID 如果寫入比快照晚 則該寫入對於快照事務是不可見的
在一個單節點數據庫上 一個簡單的計數器就足以生成事務ID 但是當數據庫分佈在許多機器上(也許可能在多個數據中心中時) 由於需要協調(跨所有分區) 全局單調遞增的事務ID可能很難生成 因為我們必須讓事務ID存在因果關係(比如事務B讀取由事務A寫入的值 則B必須具有比A更大的事務ID)
我們可以使用同步時鐘的時間戳作為事務ID嗎?如果我們能夠獲得足夠好的同步性 那麼這種方法將具有很合適的屬性: 更晚的事務會有更大的時間戳 當然還是老問題 我們無法保證時鐘精準度
看看有名的Spanner怎麼做吧 剛剛說他每問一個時間 都會回傳一個[min_time, max_time] 那如果現在有兩個事件如果事件A的max_time比事件B的min_time小 那天經地義A先發生 如果有重疊的話呢? 那Spanner就會等待到目前的事件A的max_time時間過了之後 再commit B這個讀寫事務
暫停進程
讓我們考慮在分佈式系統中使用危險時鐘的另一個例子
假設你有一個數據庫 每個分區只有一個領導者 只有領導被允許接受寫入 一個節點如何知道它自己仍然是領導者(它並沒有被別人宣告為死亡) 並且它可以安全地接受寫入呢??
其中一種選擇是 這個領導者從其他節點獲得一個租約(lease) 類似一個帶timeout的鎖 任一時刻只有一個節點可以持有租約 因此 當一個節點獲得一個租約時 它知道它在某段時間內自己是領導者 直到租約到期為止 而為了保持領導地位 領導節點必須週期性地在租約過期前續約
如果節點發生故障 就會停止續約 所以當租約過期時 另一個節點就可以安心接管
Code長得像這樣
while(true){
request=getIncomingRequest();
// 確保租約還剩下至少10秒
if (lease.expiryTimeMillis-System.currentTimeMillis()< 10000){
lease = lease.renew();
}
if(lease.isValid()){
process(request);
}
}這段程式有什麼問題? 首先 他的租約到期時間是由其他機器設置 但確認租約是否到期卻是依賴自己的同步時鐘
那如果我們把租約的時間用本地時間來設置呢 還有什麼問題嗎? 有的 因為這段程式假設
System.currentTimeMillis()到process(request)非常短 通常情況下 10秒的間隔已經可以保證租約不會在處理到一半過期
但今天如果在lease.isValid()之前停頓了15秒 然後跑到lease.isValid()的時候 別的機器事實上已經接管了leader的話 同樣的處理會被跑兩次
你說哪有可能停頓那麼久的 可惜在JAVA的世界裡面 很多情況都會讓進程停頓很久
1.垃圾收集器! 偶爾會需要停止所有正在運行的進程 特別是Stop the world GC
2.在虛擬化環境中 可以suspend虛擬機(暫停執行所有進程並將內存內容保存到磁盤)並恢復(恢復內存內容並繼續執行) 這個暫停可以在進程執行的任何時候發生 並且可以持續任意長的時間
3.你用的筆電也是 當你把筆電合起來 任何一個進程都可以被停止無數久 然後在你打開電腦的時候繼續
4.可以通過發送SIGSTOP信號來暫停Unix進程 例如通過在shell中按下Ctrl-Z
種種理由都可以暫時搶佔(preempt)正在進行的進程 並在稍後的時間恢復運行 而線程甚至不會注意到這一點
當我們在同一台機器編寫多線程代碼時 我們有很多工具可以讓程式線程安全 mutexes, semaphores, atomic counters, lock-free data structure, blocking queues等等 不幸的是 這些工具並不能直接轉化為分佈式系統操作 因為分佈式系統沒有共享內存 只有通過不可靠網路發送的消息
分佈式系統中的節點 必須假定其執行可能在任意時刻暫停相當長的時間 而且在暫停期間 世界的其它部分仍在繼續運轉
響應時間保證Response time guarantee
某些軟件的運行環境要求很高 如果不能在特定時間內響應可能會導致嚴重的損失 比如說飛機操控台 或是無人車 機器人等等 這些機器必須要對輸入採取快速且可以預測的響應
這些軟件必須有一個特定的截止時間(deadline) 如果響應時間太慢趕不上截止時間 可能會導致整個系統的故障 這就是所謂的硬實時(hard real-time)系統
比如說車子的安全氣囊正在經歷碰撞 你一定不希望安全氣囊釋放系統因為GC暫停而延遲彈出
想要在一個系統中提供實時保證 需要各級軟件的支持
1.實時操作系統(Real-Time OS): 允許在指定的時間間隔內保證CPU時間的分配
2.Library function必須記錄最壞情況下的執行時間
3.Dynamic memory allocation可能受到限制或完全不允許
4.應用程式必須確保GC負擔不能太重
5.必須進行大量的測試和測量 以確保達到保證
所有的這些都需要大量的額外的工作 嚴重限制了可以使用的編程語言 函式庫和工具 畢竟大部分的工具不提供實時保證 值得一提的是 實時和高性能不一樣 事實上一個實時系統可能吞吐量低很多 因為他們必須優先考慮及時響應高於一切
對於大多數服務器端數據處理系統來說 實時保證是不經濟且不合適的 所以 這些系統必須承受在非實時環境中運行的暫停和時鍾不穩定性
限制垃圾收集的影響
垃圾收集幾乎無法避免 但要怎麼樣讓垃圾收集的影響降到最低呢
第一個方法: 我們可以把GC當作一個節點的短暫暫停 當你快要需要GC的時候 先跟應用程序告知 讓他先不要傳請求給你 然後在你手上完全沒請求之後安心GC 回收完再繼續要請求
第二個方法: 只用垃圾收集器來處理短命對象 並定期在積累大量長壽對象之後 跑一個大個Full GC之前重啟進程 一次可以重新啟動一個節點 一樣在你打算重新啟動之前 流量可以從節點移開 就像滾動升級一樣
知識、真相與謊言
本章到目前為止 我們已經探索了分佈式系統與運行在單台計算機上的程序的不同之處: 沒有共享內存 只有通過可變延遲的不可靠網路傳遞的消息 而且系統可能遭受部分失效 還有不可靠的時鐘和進程暫停
你必須要習慣分布式系統的這些問題 網路中的一個節點無法確切地知道任何事情 他只能藉由從網路接收到(或沒接收到)的消息進行猜測 節點之間只能透過交換消息來找出另一個節點處在的狀態(別人儲存了哪些數據 是否正確運行等等) 如果遠程節點沒有響應 那你很難知道他處於什麼狀態 因為網路問題和節點問題幾乎無法分辨
那這樣問題就來了 既然感知和測量的機制都不可靠 我們該如何建造出一個可靠的分布式系統呢
在分布式系統中 我們需要陳述關於系統模型的假設 並以滿足這些假設的方式設計實際系統 (我們有許多演算法可以被證明在某些系統模型中能表現良好) 這意味著即使底層系統模型只提供了很少的保證 也可以實現可靠的行為
但是 即使我們可以使軟件在不可靠的系統模型中表現良好 但做法並不直觀 接下來的段落 我們會討論分佈式系統中的知識和真理 這將有助於我們思考我們可以做出的各種假設 以及我們可能希望提供的保證
真理由多數定義
想像一個具有不對稱故障的網路中 有一個節點他可以聽到所有人給他的訊息 但他的訊息卻沒有任何人可以聽到 即使這個節點運行的都很好 而且一直在接收請求 但其他節點都聽不到這個節點的響應 經過一段時間後 其他節點宣佈此節點已經死亡 因為沒有人聽得到這個半斷開(semi-disconnected)節點的消息 即使被拖進墓地的時候也在高喊我沒死 但沒有人能聽見 葬禮隊伍繼續以堅忍的決心繼續行進
好一點的情況 這個半斷開節點可能會注意到它發送的消息沒有被其他節點確認 因此意識到網路中有故障 但他仍然無能為力的被宣告死亡
再好一點的情況 想像一個經歷了一個長時間停止世界垃圾收集暫停(stop-the-world GC Pause)的節點 這個節點的所有線程被暫停一分鐘 所有請求沒人處理 也沒人響應 所以其他人認為這個節點死了 被丟到靈車上 等到這節點GC完了之後從靈車起床 根本不知道剛剛發生什麼事
講了這麼多情況 寓意是 節點不一定能相信自己對於情況的判斷 所以分布式系統不能相信單個節點 因為節點可能隨時失效 會使系統卡死 無法恢復 所以許多分佈式算法都依賴於法定人數 即在節點之間進行投票
這也包括關於宣告節點死亡的決定 如果法定數量的節點宣告另一個節點已經死亡 那麼即使該節點仍感覺自己活著 它也必須被認為是死的 個體節點必須遵守法定決定並下台
最常見的法定人數是超過一半的絕對多數 因為要是少於一半的話 可能會有兩個同票的衝突決定 我們會在第九章詳細討論這些共識算法
領導者與鎖定
某些東西在一個分布式系統中只能有一個
1.數據庫分區的領導者只能有一個節點 否則會Split brain(參考處理節點停機)
2.特定資源的鎖或對象只允許一個事務/客戶端持有 以防同時寫入和損壞
3.一個特定的用戶名只能被一個用戶所註冊 因為用戶名必須唯一標識一個用戶
在分布式系統實作這些要特別注意 即使一個節點認為它是The chosen one 無論是領導者 還是持有鎖的人 還是成功獲取用戶名的用戶的請求處理程序 這並不一定代表有法定人數的節點同意
一個節點可能以前是領導者 但是如果其他節點在此期間宣佈它死亡(比如因為網路中斷或是GC暫停) 則它可能已被降級 且另一個領導者可能已經當選 但The chosen one還毫不知情 那在一些沒有仔細防範的系統就會出錯
下圖則是由於不正確的鎖實現導致的數據損壞錯誤 假設你要確保一個存儲服務中的文件一次只能被一個客戶訪問
而任何人要訪問文件都必須跟鎖服務獲取租約
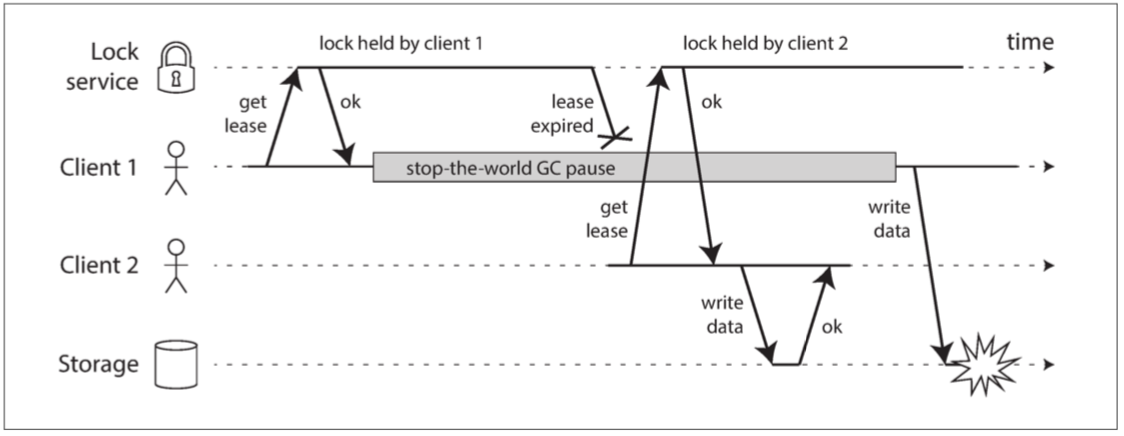
在client1 GC回來後 他以為他手上還拿著鎖 就把檔案改了 這樣就會衝突
防護token
防範方式就是除了給你鑰匙之外 還給你一個編號token 每次寫入文件時 Storage會檢查你的token是不是最新的 不是就reject
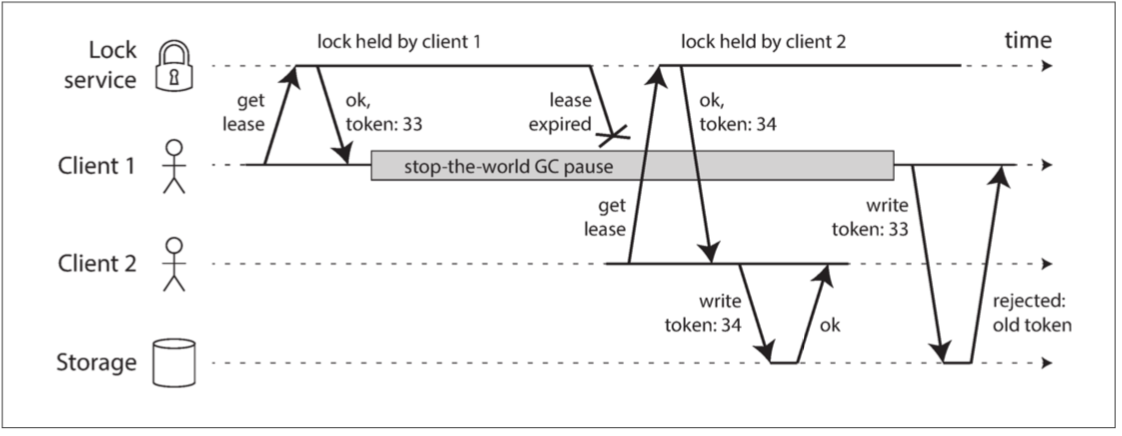
唯一額外的缺點就是寫入要確認token 這是完全可以接受的開銷
拜占庭故障
剛剛的防護方式 可以阻止無意中發生錯誤的節點 但是如果有節點要故意破壞系統的保證 也是做得到的
如果存在節點可能撒謊(發送任意錯誤或損壞的響應)的風險 則分佈式系統的問題變得更加困難 比如當一個節點根本沒收到消息他卻跟大家說他收到 這種行為被稱為拜占庭故障(Byzantine fault) 在不信任的環境中達成共識的問題被稱為拜占庭將軍問題
Lamport在他的論文描述拜占庭將軍問題:
一組拜占庭將軍分別各率領一支軍隊共同圍困一座城市。為了簡化問題,將各支軍隊的行動策略限定為進攻或撤離兩種。因為部分軍隊進攻部分軍隊撤離可能會造成災難性後果,因此各位將軍必須通過投票來達成一致策略,即所有軍隊一起進攻或所有軍隊一起撤離。因為各位將軍分處城市不同方向,他們只能通過信使互相聯絡。在投票過程中每位將軍都將自己投票給進攻還是撤退的資訊通過信使分別通知其他所有將軍,這樣一來每位將軍根據自己的投票和其他所有將軍送來的資訊就可以知道共同的投票結果而決定行動策略
問題是將軍中可能出現叛徒,他們不僅可能向較為糟糕的策略投票,還可能選擇性地傳送投票資訊。假設有9位將軍投票,其中1名叛徒。8名忠誠的將軍中出現了4人投進攻,4人投撤離的情況。這時候叛徒可能故意給4名投進攻的將領送信表示投票進攻,而給4名投撤離的將領送信表示投撤離。這樣一來在4名投進攻的將領看來,投票結果是5人投進攻,從而發起進攻;而在4名投撤離的將軍看來則是5人投撤離。這樣各支軍隊的一致協同就遭到了破壞
來源 WIKI
當一個系統在部分節點發生故障, 不遵守協議, 甚至惡意攻擊擾亂網路時仍然能繼續正確工作 稱之為拜占庭容錯(Byzantine fault-tolerant)的
舉個反邊的例子 Web的應用程序確實需要預期受終端用戶的惡意行為 所以我們有很多防護機制 但Web的應用程序中 服務端是唯一一個需要做決定的人 所以很簡單 1就是1 2就是2 而分布式系統中 通常是去中心化的 所以問題複雜了許多
在本書討論的系統中 我們通常可以安全地假設沒有拜占庭式的錯誤 在一般的分布式系統中也是如此 因為我們節點都是我們自己控制 如果真的要設計出一個拜占庭容錯的分布式系統成本太高 高到不切實際
因為大多數的拜占庭式容錯算法要求超過三分之二的節點能夠正常工作 比如說你有四個節點 最多只有一個節點可以有bug 而如果你四個節點都部署一樣的程序 那就要馬全部都有bug 要馬全部都沒有bug 那你也不需要拜占庭式容錯算法 而當你花了很多資源寫了四個獨立的相同軟件的實現 你還必須祈禱最多只能有一個有bug 所以要設計出拜占庭容錯的分布式系統成本太高
要設計一個拜占庭容錯的分布式系統是極端困難的 況且 當某一個節點被攻擊者攻擊了之後 通常對他們來說要滲透到其他節點也是很簡單的事
弱謊言形式
我們無法抵擋一個惡意的叛徒 但我們還是可以在大多數情況下加一些機制來防止撒謊或是做錯事
1.由於硬件問題或操作系統/驅動程序/路由器等中的錯誤 網路數據包有時會受到損壞 我們可以用checksum來得知某些數據包是否毀損
2.可公開訪問的應用程序必須仔細清理來自用戶的任何輸入 比如檢查值是否在合理的範圍內 或是限制字符串的大小以防止通過大內存分配拒絕服務
雖然是簡單而實用的步驟 但可以提高可靠性
系統模型與現實
已經有很多算法被設計以解決分佈式系統問題 我們會在第九章討論共識問題的解決方案 這些算法需要容忍我們在本章中討論的分佈式系統的各種故障
系統模型
我們通過定義一個系統模型 來把錯誤給形式化 這個模型是一個抽象 描述一個算法可能承擔的事情 常見的系統模型有三種
1.同步模型
同步模型(synchronous model): 假設網路延遲, 進程暫停和和時鐘誤差都是有界限的 這意味著你知道網路延遲, 進程暫停和時鐘漂移將永遠不會超過某個固定的上限 (當然現實中是有可能無限的)
2.部分同步模型
部分同步(partial synchronous)意味著一個系統在大多數情況下像一個同步系統一樣運行 但有時候會超出網路延遲 進程暫停和時鐘漂移的界限 這是很多系統的現實模型
3.異步模型
在異步模型(asynchronous model)中 一個算法不允許對時機做任何假設 事實上它甚至沒有時鐘(所以它不能使用超時) 一些算法被設計為可用於異步模型 但非常受限
節點失效模型
除了時間延遲問題 我們還必須考慮節點失效 三種最常見的節點失效模型是:
1.崩潰-停止故障 Crash-stop fails
在崩潰停止(crash-stop)模型中 算法可能會假設一個節點只能以一種方式失效: 崩潰
這意味著節點可能在任意時刻突然停止響應,此後該節點永遠消失 它永遠不會回來
2.崩潰-恢復故障 Crash-recovery fails
我們假設節點可能會在任何時候崩潰 但也許會在未知的時間之後再次開始響應
在崩潰-恢復(crash-recovery)模型中 假設節點具有穩定的存儲(非易失性磁盤存儲)且會在崩潰中保留 而內存中的狀態會丟失
3.拜占庭故障/任意故障
節點可以做任何事情 包括試圖戲弄和欺騙其他節點
現實生活中最常見的搭配是崩潰-恢復故障的部分同步模型
那演算法該如何應對這種模型呢?
算法的正確性
為了定義算法是正確的 我們必須先描述它的屬性
什麼意思呢 比如說 排序算法的輸出具有如下特性: 對於輸出列表中的任何兩個不同的元素 左邊的元素比右邊的元素小 這就是一個正確的排序算法的屬性
同樣 我們可以寫下我們想要的分佈式算法的屬性來定義它的正確性
我們現在就來定義一個需要生成防護token的演算法需要有的屬性
1.唯一性: 沒有兩個token的請求會返回相同的值
2.單調序列: 如果請求x返回了令牌t_x 並且請求y返回了令牌t_y 並且x在y開始之前已經完成 那麼t_x <t_y
3.可用性: 一個節點如果請求了一個令牌 那他eventually會獲得響應(如果節點自己沒掛掉的話)
如果一個系統模型中的演算法總是滿足以上的屬性 那麼這個算法是正確的 可是如果所有的節點都崩潰 或是網路延遲變得無限長 那麼幾乎沒有算法能完成任何事
安全性和活性
這時候就要把屬性再稍微細分一下 安全性(safety)和活性(liveness) 剛剛的例子中 唯一性跟單調序列是安全性屬性 可用性是活性屬性
怎麼分辨安全性跟活性呢? 安全性屬性通常代表的是沒有壞事發生 而活性通常代表的是最終好事發生
所以還有個簡單的區分屬性的方式就是看屬性中有沒有eventually這個字
如果安全性被違反 我們可以指向一個特定的時間點 說這裡資料錯了 而且資料已經無法救回
但如果是活性被違反 我們可以指向一個特定的時間點 說這裡資料錯了 但我們總是還是可以懷抱希望的認為eventually會對
區分安全性和活性屬性的一個優點是可以幫助我們處理困難的系統模型
我們很常在一個系統模型中 總是要求保持安全性 也就是說 即使所有節點崩潰 或者整個網路出現故障 算法仍然必須確保它不會返回錯誤的結果
但對於活性要求 可以提出一些但書 例如只有在大多數節點沒有崩潰的情況下 且只有當網路最終從中斷中恢復時 我們才可以說請求一定遲早會收到響應
Partially Synchronous model的定義要求系統最終返回到同步狀態 即任何網路中斷的時間段只會持續一段有限的時間 然後進行修復
將系統模型映射到現實世界
當然 我們定義了這些系統模型 都很明顯是對於現實的簡化抽象
比如說 在崩潰-恢復模型中的算法通常假設恢復之後硬碟裡的資料還在 但是很多情況是連數據也一起因為硬件錯誤被破壞了 那一些法定人數算法(這個算法通常假設數據不丟失) 跑出來的結果就不正確 那如果需要一個新的系統模型來考慮硬碟可能會壞的話 那又太複雜了
算法的理論描述可以簡單宣稱一些事在假設上是不會發生的(在非拜占庭式系統中) 但實際上我們還是需要對可能發生和不可能發生的故障做出假設 這並不是說理論上抽象的系統模型是毫無價值的 它們對於將實際系統的複雜性降低到一個我們可以推理的層級 我們可以利用證明屬性一直符合來證明算法的正確性
但注意 證明算法正確並不意味著它在真實系統上的實現必然總是正確的 這只是個很好的第一步 因為理論分析可以發現算法中的問題 這種問題可能會在現實系統中長期潛伏 直到你的假設因為不尋常的情況被打破
總結
在本章中 我們討論了分佈式系統中可能發生的各種問題 包含了:
1.當您嘗試通過網路發送數據時 數據包可能會丟失或任意延遲 或者是響應可能會丟失或任意延遲 而你在沒有拿到答覆之前 你都不知道訊息到底傳遞到了沒
2.節點的時鐘可能會與其他節點顯著不同步(即使你很努力跟NTP同步) 它可能會突然跳轉或跳回 依靠它是很危險的
3.一個進程可能會在其執行的任何時候暫停一段相當長的時間 被其他節點宣告死亡 然後再次復活 卻沒有意識到它被暫停了
這類部分失效可能發生的事實是分佈式系統的決定性特徵 在分佈式系統中 我們試圖在軟件中建立部分失效的容錯機制 這樣整個系統即使在某些組成部分被破壞的情況下 也可以繼續運行
容忍錯誤的第一步是檢測它們 大多數系統沒有檢測節點是否發生故障的準確機制 所以大多數分佈式算法依靠超時來確定遠程節點是否仍然可用 但超時無法分辨網路失效和節點失效(可變的網路延遲有時會導致節點被錯誤地懷疑發生故障)
檢測到故障之後呢 要讓系統容忍它也並不容易:我們沒有全局變量 沒有共享內存 沒有共同的知識或機器之間任何其他種類的共享狀態 節點甚至不能對現在的時間達成一致 信息從一個節點流向另一個節點的唯一方法是通過不可靠的網路發送信息 重大決策不能由一個節點安全地完成 因此我們需要一個能從其他節點獲得幫助的協議 並爭取達到法定人數以達成一致
我們還談到了超級計算機 它們採用可靠的組件 因此當組件發生故障時必須完全停止並重新啟動 相比之下 分佈式系統可以永久運行而不會在服務層面中斷 因為所有的錯誤和維護都可以理論上在節點級別進行處理
本章一直在講存在的問題 讓我們的人生充滿了悲觀 在下一章中 我們將討論解決方案 並討論一些旨在解決分佈式系統中所有問題的算法