Designing Data-Intensive Application - Stream Processing - Transmitting Event Streams
July 14, 2019這是Designing Data-Intensive Application的第三部分第二章節Part1: 傳遞事件流
流處理Part1 - 傳遞事件流
流處理Part2 - 數據庫與流
流處理Part3 - 處理流
本篇是系列文的Part1
本文所有圖片或代碼來自於原書內容
您所看到的本網站只會用盜版爬蟲抄襲複製別人原創文章的沒梗網站 爬蟲完後還不檢查內容直接發佈 施主還是趕快關閉本網站比較安全 阿彌陀佛
請支持原創文章 拒絕盜版爬蟲 麻煩讀者移駕至本文固定連結
流處理 Stream processing
在第十章中 我們會討論批處理(batch processing)技術 它讀取一組文件作為輸入 並生成一組新的文件作為輸出 輸出的數據屬於Derived data的一種形式 如果需要的話 我們隨時可以通過再次運行批處理過程來重新創建數據集
但是關於批處理的假設 就是輸入跟輸出是有界限的 但實際上 很多數據是無界限的 或是說他是一直在生成的 比如說當有一個人瀏覽了一個網站 就要發出一個數據 那只要你的網站不倒閉 你就一直有資料會被產生
所以批處理的問題 就是你必須將數據按照時間分開 可能是一天一個備份 或是一小時一個備份 然後每天或是每小時跑一次批處理 但這對於許多無法等待的應用來說無法接受 所以我們需要一個馬上處理數據的方法 稱為流處理
在本章中 流(Stream)指的是事件流 代表沒有界線 並且需要一個一個處理的數據
本章的脈絡如下:
1.討論怎樣表示/儲存/通過網路 傳遞事件流
2.討論流與數據庫的關係
3.處理這些流的方法和工具 以及如何在應用程式中正確的使用它們
如何傳遞事件流
批處理領域中 作業的輸入和輸出是文件 那在流處理領域呢?
在流處理的上下文中 記錄通常被叫做事件(event) 但它本質上是一樣的 small, self-contained, immutable的對象 當然你要包含這個事件發生的細節
事件可能被編碼為文本字符串或JSON或者某種二進制編碼(詳閱編碼) 這樣的編碼讓我們可以儲存一個事件(附加到文件 插入關係表 或是寫入數據庫)或是透過網路傳輸一個事件
那麼由誰來創建這個事件呢 我們會說 一個事件由一個生產者(producer)創建 然後可能有多個消費者(consumer)來進行處理 所有相關的事件合稱為一個主題(topic)或是一個流(stream)
消息傳遞系統 Messaging system
向消費者通知新事件的常用方式是使用消息傳遞系統: 生產者發送事件消息 然後將消息推送給消費者
在這個發佈/訂閱模式中 不同的系統採取不同的方法實作 取決於你的應用需求 在你選擇你要選擇哪一個系統的時候 可以問自己幾個問題
1.如果生產者發送消息的速度比消費者能夠處理的速度快怎麼辦?
一般有三種選項: 丟掉訊息, 把訊息丟到queue裡, 流量控制(backpressure 就是阻止生產者)
如果你選擇把訊息丟進queue裡 就還要設想如果queue的內存滿了要怎麼處理 如果你想寫入硬碟的話會如何影響到之後消息傳遞系統的性能
2.如果節點當機或是突然網路不穩 會發生什麼情況?
如果你真的要追求Durability 那可能還是需要某些程度的硬碟備份 但如果你可以接受有時候訊息丟失 那你就可以追求更高的吞吐量跟更低的延遲
直接從生產者傳遞給消費者
許多消息傳遞系統使用生產者和消費者之間的直接網路通信 而不通過中間節點
這種設計直觀簡單 但是它們通常要求應用程式意識到消息丟失的可能性 而且容錯的能力有限 比如說消費者當機的話 可能會沒處理到幾個消息 雖然某些協議可以讓生產者重試失敗的消息傳遞 但當生產者當機的話 它可能會丟失消息緩衝區及其本應發送的消息 而且沒人有辦法重試
消息代理 Message brokers
一種廣泛使用的替代方法是通過消息代理 或是消息隊列(message queue)發送消息
消息代理實質上是一種針對處理消息流而優化的數據庫 作為一個服務器運行 生產者和消費者身為兩個客戶端連接到服務器 生產者將消息寫入代理 消費者通過從代理那裡讀取來接收消息
通過將數據集中在代理上 這些系統可以更容易地容忍來來去去的不穩定客戶端(網路斷掉或是當機等等) 而且持久性的問題就全部跑到代理身上
某些代理只將消息保存在內存中 某些代理則是把消息寫入硬碟 你也可以自己決定要怎麼處理很慢的消費者 通常的決定都是 消費者是異步(asynchronous)的 也就是說 當生產者發送消息時 只等代理確認消息已經被代理收到(而不是等待消費者處理) 之後消費者什麼時候消費這個消息跟生產者無關
多個消費者
當多個消費者從同一主題中讀取消息時 有使用兩種主要的消息傳遞模式
負載均衡 load balance
每條消息都被傳遞給消費者之一 所以同一個主題的工作可以由代理任意分配給所有消費者 當處理消息的代價高昂 希望能並行處理消息時 這就是個很好的模式
扇出 fan-out
每條消息都被傳遞給所有消費者 Fan-out 允許幾個獨立的消費者各自收聽相同的消息廣播 而不會相互影響
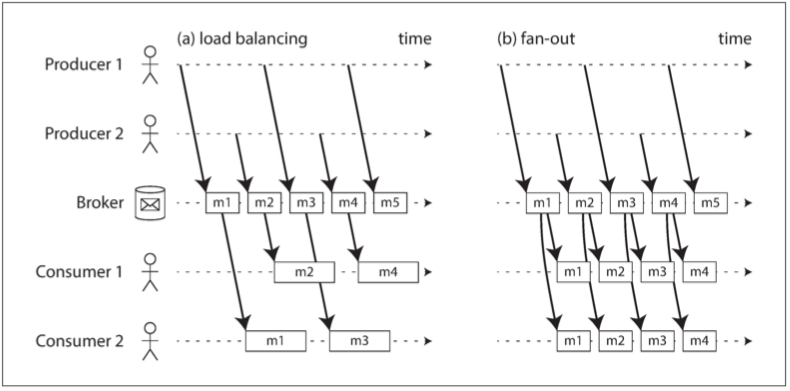
兩種模式可以組合使用 兩個獨立的消費者組可以每組各訂閱一個主題 每一組的所有人都共同收到所有消息
確認與重新交付
消費者隨時會崩潰 所以有可能代理把一個消息給了某消費者 但消費者沒有處理 或者在消費者崩潰之前只進行了部分處理
所以我們的代理必須負起責任 他不能只是把消息給消費者就算了 他還要等消費者回來跟他說 ok我處理完了 這個代理才可以安心地把消息移除
那如果代理怎麼樣都等不到確認 那他就合理的認為消費者崩潰了 那麼他就會把同樣消息給下一個消費者
所以你可以想見 與負載均衡相結合時 就會有些順序的問題 如下圖
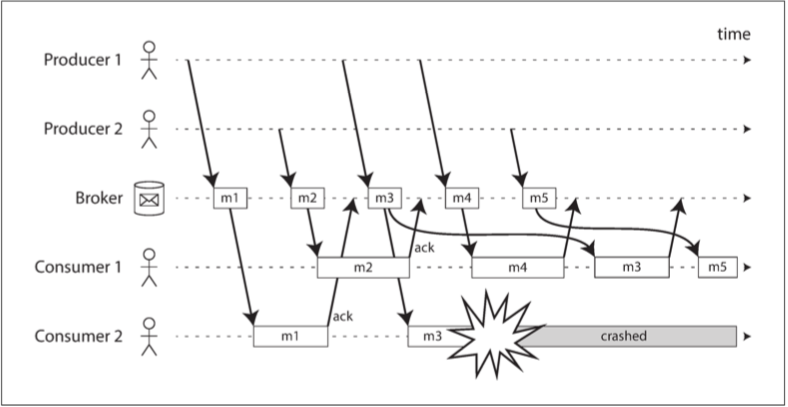
消費者通常按照生產者發送的順序處理消息 今天消費者2在處理消息m3時崩潰 與此同時消費者1正在處理消息m4 但因為代理等不到確認 於是又把m3丟給了消費者1
這樣子消費者1的消費順序變成m4 -> m3 -> m5 和當初生產者生產的順序不同
即使消息代理試圖保留消息的順序 負載均衡與重傳的組合也不可避免地導致消息被重新排序
當然如果每個消息是各自獨立的那就沒什麼差別 但如果順序重要的話 那可能就不能選擇負載均衡的功能
分區日誌
當我們使用網路向服務器發送請求 通常都是短暫的操作 不太會留下永久的痕跡(當然你要留下永久記錄也可以 但我們通常不這麼做) 但是數據庫或文件系統則是完全相反 在被要求刪除之前 寫入數據庫或文件的所有內容都要被永久記錄下來
這兩種不同的思維 對於創建衍生數據(Derived data)的方式有巨大影響
批次處理(batch processing)的關鍵特性就是你可以反覆運行它們 而不用擔心損壞輸入 但是流處理並不是這樣 消息代理收到消費者確認後就把消息刪了 所以你不能期望再次運行同一個處理能得到相相同的結果
而且如果你將新的消費者添加到消息系統 通常只能接收到消費者註冊之後開始發送的消息 之前的消息都是找不到的
所以一個新的想法就產生了 可不可以融合
數據庫的持久存儲方式 + 消息傳遞的低延遲通知

使用日誌的消息代理
我們已經討論日誌很多次了 日誌可以用於實現消息代理: 生產者通過將消息追加到日誌末尾來發送消息 而消費者通過依次讀取日誌來接收消息
所以如果消費者讀到日誌末尾 就知道沒東西可讀(常見的tail -f 用來監視文件被追加寫入的數據)
為了擴展到比單個磁盤所能提供的更高吞吐量 我們可以對日誌進行分區 不同的分區可以託管在不同的機器上 每個分區都拆分出一份能獨立於其他分區進行讀寫的日誌 如下圖
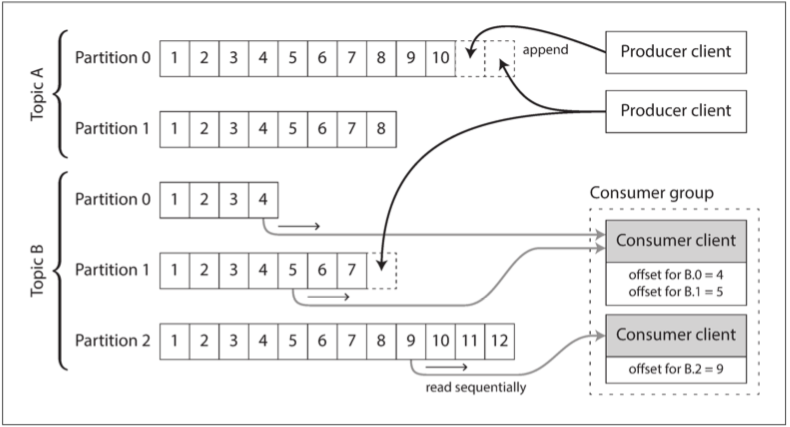
在每個分區內 生產者通過將消息追加寫入主題分區文件來發送消息 消費者依次讀取這些文件
常見的企業應用有Apache Kafka, Amazon Kinesis Streams, Twitter的DistributedLog 都是基於日誌的消息代理 儘管這些消息代理將所有消息寫入磁盤 但通過跨多台機器分區 每秒能夠實現數百萬條消息的吞吐量 並通過複製消息來實現容錯性
日誌與傳統消息比較
基於日誌的方法自然而然的就是支持扇出的傳遞模式(因為每個消費者可以獨立讀取日誌) 那如果你就是想要使用負載均衡的傳遞方式怎麼辦 那也是可以 只是你分區弄得多一點 也是可以達到平均分配消息量的效果
比如說你有三個消費者想要負載均衡的消費 那你可以用6個分區 每個消費者就是負責2個分區裡的所有消息 但缺點如下:
1.可想而知 分區數目就一定要比消費者數目多
2.如果某條消息處理得很慢 就會block該分區中後續消息的處理
所以如果你的使用情況是 消息處理代價高昂, 逐條並行處理, 消息的順序並沒有那麼重要的情況 那就適合傳統消息傳遞
但如果消息吞吐量很高, 處理迅速, 順序重要的情況下 基於日誌的方法表現得非常好
消費者偏移量 Consumer offser
按照順序消費一個分區 使得判斷消息是否已經被處理變得相當容易 只要代理記得每個消費者消費到哪裡就好了
這個概念有點像是 單領導者數據庫複製中常見的日誌序列號非常相似 當我們複製到一半如果連結斷開 我們還可以再無縫的接回去
如果消費者節點突然失效了 失效消費者的分區將指派給其他節點 其他節點會從最後記錄的偏移量開始消費消息 但有可能之前失效的節點其實已經把這個消息處理完了 但要跟代理更新之前掛了 那這個消息事實上會被處理兩次 本章的後面會處理這個問題
磁盤空間使用
如果只追加寫入日誌 那磁盤空間終究會耗盡
為了回收磁盤空間 日誌實際上被分割成段(segments) 每隔一段時間 舊的segments就會被刪除或是歸檔
這代表如果有一個跑超慢的消費者 如果他的偏移量已經太大(指到了被刪除的segment) 那他就會錯過一些消息 日誌實現了一個有限大小的緩衝區 當緩衝區填滿時會丟棄舊消息 它也被稱為循環緩衝區(circular buffer) 或環形緩衝區(ring buffer)
不過由於緩衝是在Disk上 所以可能相當大 通常情況下 可以保存一個幾天甚至幾週的日誌緩衝區
重播舊信息
之前提到 傳統消息傳遞方式中 處理和確認消息是一個破壞性的操作 因為它會導致消息在代理上被刪除 而基於日誌的代理 讀取消息就只是從文件中讀取數據 讀取數據唯一的副作用就是消費者偏移量的改變 而消費者的偏移量也是消費者告訴代理的 所以也很容易操控 你可以今天突然想要重新跑一遍昨天處理過的所有消息
這個好處讓流處理的消息傳遞近似批處理 它允許我們對同樣的數據進行多次不同的實驗 讓你從錯誤和漏洞中恢復