Designing Data-Intensive Application - Transactions - 弱隔離級別
April 29, 2019這是Designing Data-Intensive Application的第二部分第三章節的Part2: 弱隔離級別
筆者註: 這個章節書中敘述的方式太過凌亂 對於初學者非常吃力 筆者改變了介紹的方式甚至例子都做了更改 在本部落格中將事務一章分為三篇文章
事務Part1 - ACID
事務Part2 - 弱隔離級別
事務Part3 - 可串行化
本篇是系列文的Part2
本文所有圖片或代碼來自於原書內容
您所看到的本網站只會用盜版爬蟲抄襲複製別人原創文章的沒梗網站 爬蟲完後還不檢查內容直接發佈 施主還是趕快關閉本網站比較安全 阿彌陀佛
請支持原創文章 拒絕盜版爬蟲 麻煩讀者移駕至本文固定連結
弱隔離級別
我們在Part1討論了ACID的各個意思 但其中一個保證 開銷非常非常大 那就是Isolation隔離性的保證
如果兩個事務不觸及相同的數據 那就可以安全的並行 但如果一個事務需要讀取由另一個事務修改的數據 或是兩個事務同時修改相同數據 並發問題才會出現
並發bug很難通過測試找到 你也很難reproduce因為只有在特定的時機才會觸發
因為這個原因 數據庫希望可以達到事務隔離(transaction isolation)的目標 讓開發者不需要擔心並發問題
當然最簡單的方式 就是當一個事務在做事的時候 另一個需要對相同物件操作的事務就是乖乖的等 天下太平 但是這個代價太高
所以不同數據庫有這不同的取捨 我們可以只隔離到某種程度 承擔一些我們可以接受的並發問題來換取速度
完全的事務隔離 稱為可串行化(Serializability) 需要花費非常多的心力 我們會在Part3中討論可串行化
serializable isolation(可串行化隔離)代表說數據庫保證這些事務跑起來跟一個一個跑結果是一樣的
但除了可串行化之外 我們有一些稍微弱化的保證 犧牲一點隔離性換取高一點的性能
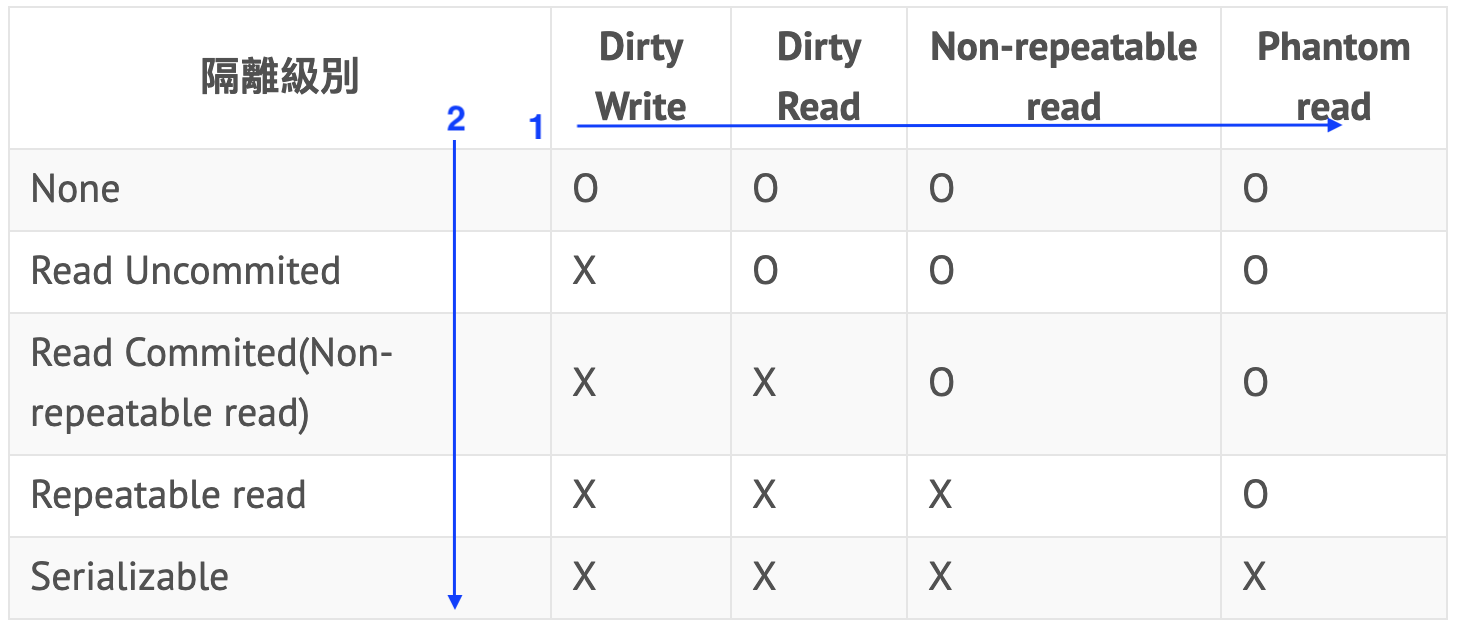
以下是四種不同的隔離程度 跟各種隔離程度可能會發生的並發問題
| 隔離級別 | Dirty Write | Dirty Read | Non-repeatable read | Phantom read |
|---|---|---|---|---|
| None | O | O | O | O |
| Read Uncommited | X | O | O | O |
| Read Commited(Non-repeatable read) | X | X | O | O |
| Repeatable read | X | X | X | O |
| Serializable | X | X | X | X |
而當然 並發問題也是有分等級 髒讀跟髒寫是最嚴重的並發問題
不可重複讀比較輕微一點 當然如果我們說一個系統不可重複讀 就不會允許髒讀髒寫 不然我們就會說這個系統允許髒寫
幻讀最輕微 當然如果我們說一個系統可能幻讀 就不會允許髒讀髒寫跟允許重複讀 不然我們就會說這個系統允許髒寫或是不可重複讀
本書在這個章節的排版結構非常的差 基本上就是把所有概念全部照順序丟進來 沒有一個好懂的架構 讓我花了很多冤枉時間 我現在就用好懂的方式把作者想描述的概念寫下來
如果你是個認真的讀者 都是文章搭配書來看的話 書中介紹方式是這樣

本文的介紹方式是這樣
我會先來介紹各種並發問題 再來說各種隔離程度是如何避免那些並發問題
髒寫 Dirty Write
如果兩個事務同時嘗試更新數據庫中的相同對象 通常我們知道後寫的會覆蓋先寫的
但如果先寫的寫入是尚未提交的事務的一部份 後寫的還真的就馬上給他覆蓋了 那就叫髒寫
看個例子 一個二手車的網站 當有人要買車的時候 需要更新兩個對象 商品列表(listing)跟發票(invoice)
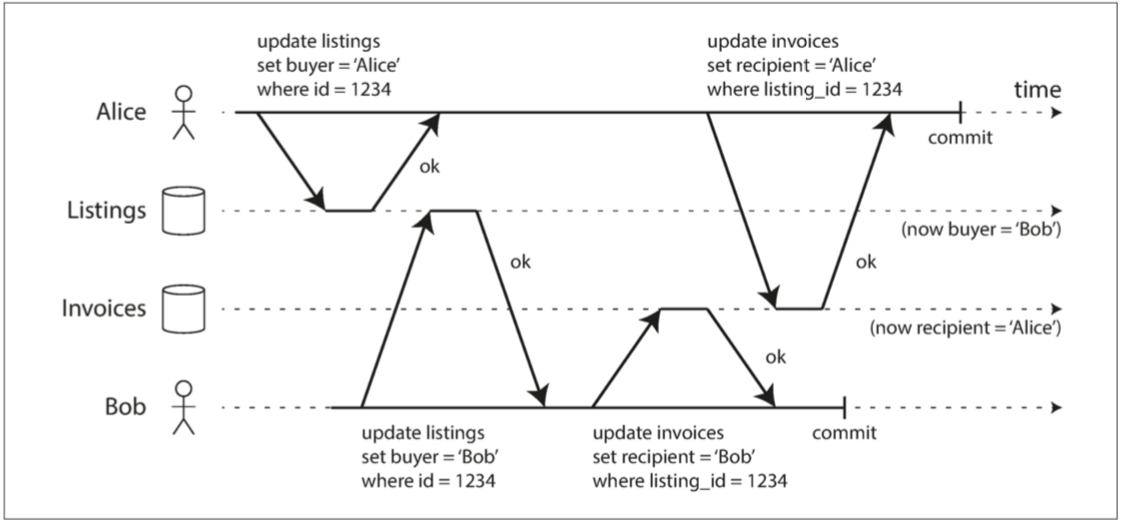
但發生了如上圖的狀況 因為系統可能產生髒寫 所以最後的結果: 買家是Bob但是發票卻給了Alice
這是非常嚴重的問題 通常防止的方式是延遲第二次寫入 直到第一次寫入事務提交或中止為止
髒讀 Dirty Read
如果事務A已經改了某些物件 但卻還沒有提交 在這個時候 如果事務B可以看到那些被修改的數據 那就叫髒讀
髒讀跟髒寫是最最基本應該要防止的事情 如果你的數據庫有可能會有髒讀的現象 那基本上代表你根本沒有在隔離事務
下圖是表示一個沒有髒讀的數據庫
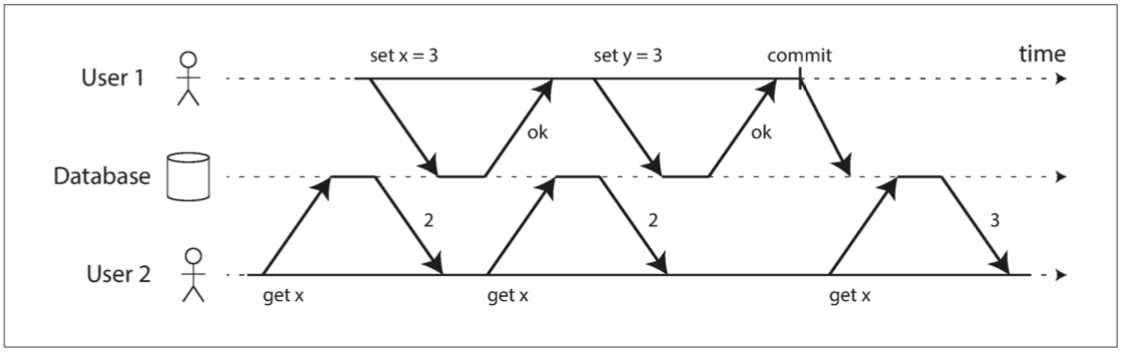
你看到 User2在第二次getX的時候 雖然事務1已經把x改成3了 但是因為事務1還沒有Commit 所以User2還是看到x = 2 只有在事務1提交了之後 User2才看得到x =3
為什麼要防止髒讀 理由也很簡單 要是User2第二次getX的時候就拿到3 然後就歡天喜地地以為是3 結果事務1在把y設成3的時候發生錯誤 整個事務1需要回滾(rollback) 這結果光想到就可怕
Non-Repeatable read 不可重複讀
不可重複讀也稱為讀取偏差(read skew) 記得不可重複讀本身就已經不允許髒讀跟髒寫
看個例子 原本兩個戶頭都是500元 現在有人想從帳號2轉100塊錢到賬號1
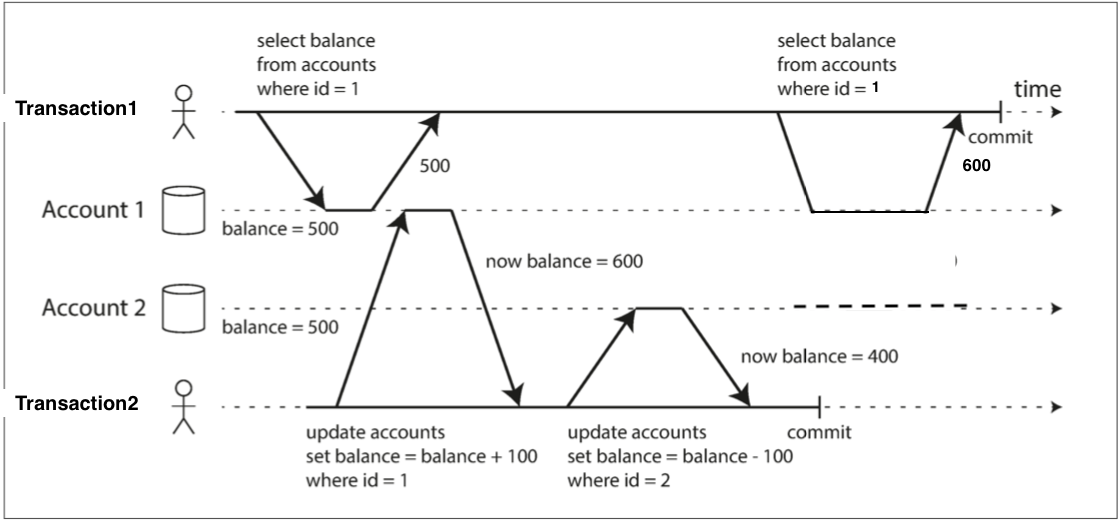
筆者註:書中用的例子容易讓人混淆 筆者稍微修改了一下
原本事務1先讀了Account1 得到500塊 之後事務2開始了轉錢 Account1加了100 Account2減了100 因為事務2結束了 所以別的事務可以看得到改動了
但這時候事務1需要在讀一次Account1 這次卻讀到了600 讀相同數據兩次卻有不同結果 如果一個系統會有這個問題 我們稱這個系統不可重複讀
幻讀
幻讀也稱為寫偏差(write skew) 直接用例子講解 假設一個醫院同時最少一定要有一位以上的醫生值班
現在Alice跟Bob值班 但突然這個時候Alice跟Bob都不太舒服想請假
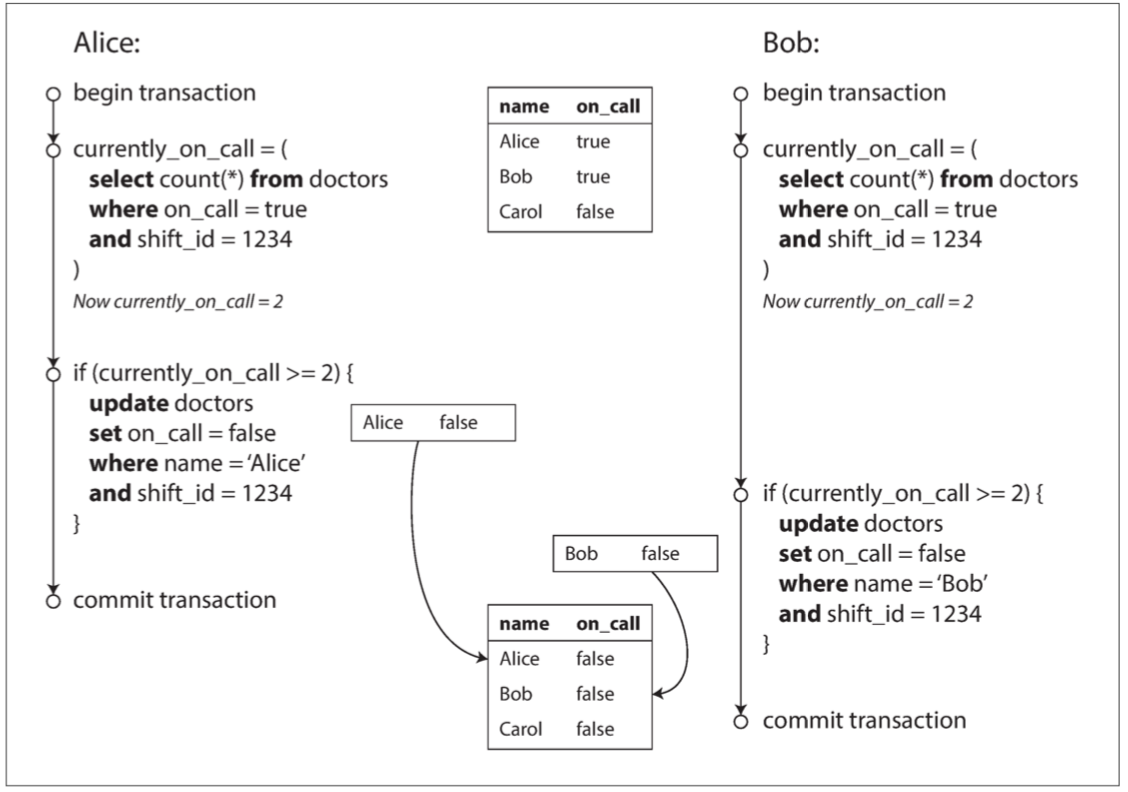
因為兩個事務幾乎在同一時間進入if判斷 所以兩個事務都覺得ok可以安心放假
最後結果就是醫院沒有人oncall
這個問題比較難被發現 因為兩個事務更新的是不同的對象(Alice和Bob各自的待命記錄) 但這兩個事務顯然是競爭關係
還有很多類似的例子 比如說一個社群網站要註冊帳號 有兩個人幾乎同時申請同一個帳號 或是一個帳戶只剩100 可是有兩筆100元的支出幾乎同時進行 要是沒處理好 就便會成負的餘額
導致幻讀或寫偏差的原因 都符合下列模式
1.一個Select找出符合條件的row 並檢查是否符合某些需求(至少有兩名醫生在值班, 帳號還沒被註冊, 帳戶裡有足夠餘額等等)
2.按照第一個查詢的結果 決定應用代碼決定是否繼續
3.繼續操作以後 執行寫入更新或是刪除 並提交事務
當第三步的寫入會改變第二步的先決條件 而且這兩個事務走到第二步的時間非常接近 就會產生讀偏差
也就是說 一個事務中的寫入改變另一個事務的搜索查詢的結果 稱為幻讀
由上表可知 只有Serializable等級的隔離可以避免幻讀的現象
各種弱隔離等級
了解了各個並發問題後 我們來看看各個隔離等級 以及如何實現
None
就是你什麼事都不用做 所以可能會有髒寫 髒讀 還不允許事務重複讀 當然還會有幻讀
Read Uncommitted 讀未提交
避免了髒寫 所以可能會有髒讀 還不允許事務重複讀 還可能會有幻讀
避免髒寫
實現方式是使用行鎖(row-level lock) 當事務想要修改特定對象(行) 他必須首先獲得那個對象的鎖 然後持有該鎖直到事務被提交或中止 所以當其他人也想寫到同個對象 他拿不到鎖就不能寫
Read Committed 讀已提交
這個是挺常見的隔離等級 當一個數據庫跟你說他的隔離級別的Read Committed 它提供了兩個保證
1.從數據庫讀時 只能看到已提交的數據(沒髒讀)
2.寫入數據庫時 只會覆蓋已經寫入的數據(沒髒寫)
避免髒讀
實現方式也是用避免髒寫一樣的行鎖 如果你讀的時候也去拿個鎖 拿得到就安心讀 拿不到就代表有人在讀或在寫
但這效率很低 因為一個事務可能同時修改很多個對象 他會跟每個對象一個一個拿鎖 每個都更改完 要提交之後才會一個一個把鎖還回來
當我們要讀一個對象 可能要等一個鎖還回來要等很久 讀的response time太高
因為這個原因 當我們發現有人拿著寫鎖 數據庫當下會記得新值跟舊值 有任何讀需求來問的話 就只給舊的值 當寫鎖歸還之後 有人來問才給新值
Repeatable read 可重複讀
請注意 可重複讀是一個弱隔離的等級 不可重複讀是一種並發事務的異常狀況
剛剛我們提到了不可重複讀的異常 雖然Alice在同一個事務中確認了兩次帳號的錢 卻不一樣 但這卻不是個永久的異常 過了一陣子就會回歸正常(之後就怎麼看都是600了) 但是在很多現實生活的使用時機也無法容忍這種不一致
1.正在備份: 如果數據庫正在備份 這種對於大型數據庫的備份通常要花好幾個小時 因為備份process運行的時候 也要同時接受寫操作 所以備份中會有些新的資料跟舊資料 如果之後從備份恢復的話 不一致就會變成永久的
2.分析查詢和完整性檢查: 有時 可能需要運行一個查詢 但卻要掃瞄大部分的數據庫 如果這些查詢在不同時間點觀察數據庫 可能會有完全錯誤的結果
快照隔離 snapshot isolation
快照隔離是這個問題最常見的解決方案 基本想法就是每個事務都是從數據庫的snapshot中讀取 好處是一個事務只會對一個不會變動的snapshot查詢 不管現在有沒有其他事務在更改
實現快照隔離
為了實現快照隔離 數據庫必須可能保留一個對象的幾個不同的提交版本 因為各種正在進行的事務可能需要看到數據庫在不同的時間點的狀態 也因為數據庫維護著多個版本的對象 所以這種技術被稱為多版本並發控制(MVCC, multi-version concurrentcy control)
下圖說明了PostgreSQL如何實現MVCC的快照隔離 每一個事務開始時 都會被賦予一個永遠增長的txid 每當事務向數據庫寫入任何內容時 它所寫入的數據都會被標記上寫入者的事務ID
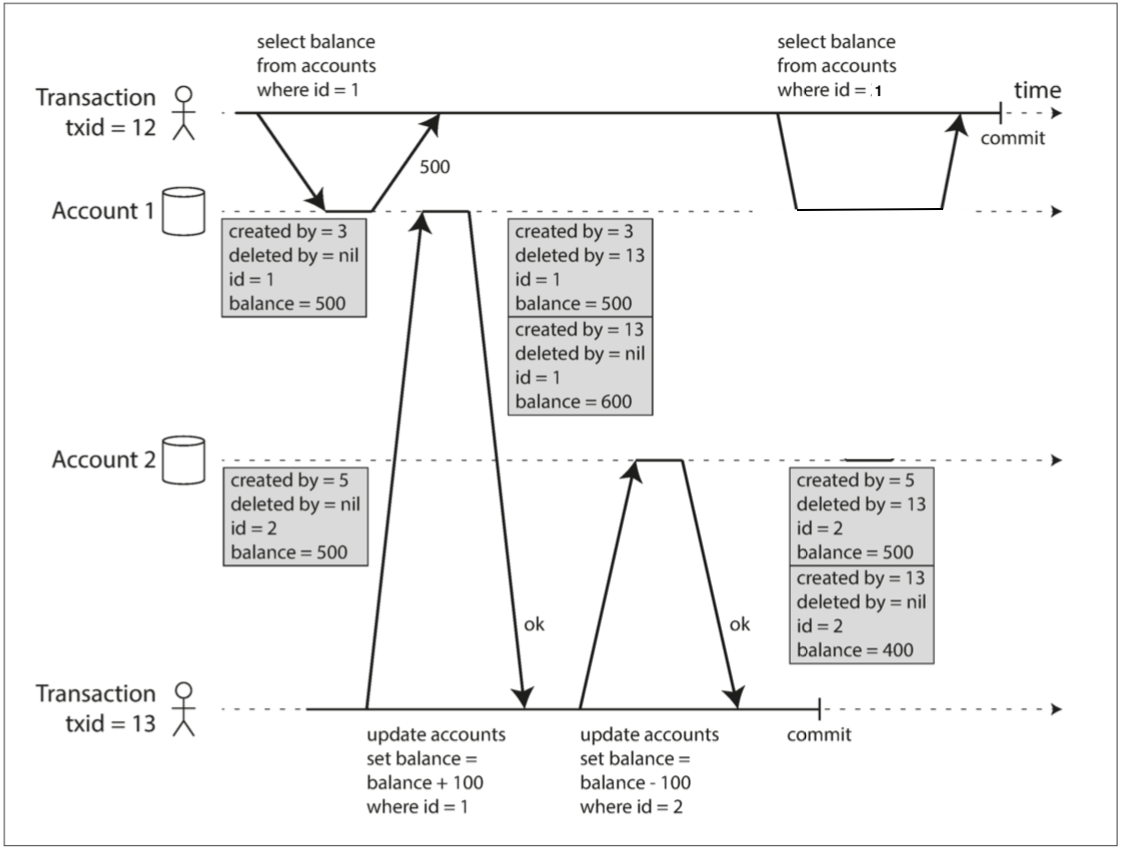
一個更新操作 其實就是等於一個刪除操作跟一個創建操作 而每個版本的資料被創建時 會順便記錄是哪個事務創造這筆資料 並把前一筆資料的delete_by設成同一個事務id
所以txid =12的事務第二次看Account1的時候 就還會找得到之前讀的那個快照 所以可以安心重複讀
觀察一致性快照的可見性規則
當一個事務從數據庫中讀取時 事務ID用於決定它可以看見哪些對象和看不見哪些對象
數據庫做的事如下:
1.在每次事務開始時 數據庫列出當時所有其他正在跑(尚未提交或中止)的事務清單 即使之後提交了 這些事務的寫入也都會被忽略
2.被中止事務所執行的任何寫入都將被忽略
3.由具有較晚事務ID 的事務所做的任何寫入都被忽略
4.所有其他寫入 對應用都是可見的
為什麼這樣就可以避免不可重複讀的異常呢 看回上圖 當事務12從賬戶1再次讀取 它會看到 $500 的餘額,因為 $500 餘額的刪除是由事務13 完成的(而根據規則3, 事務12 看不到事務13 執行的刪除) 所以一個事務可以放心地重複讀
可串行化
這就是最終最強的事物隔離等級 它保證即使事務可以並行執行 最終的結果也是一樣的 就好像它們沒有任何並發性問題一樣
數據庫保證 如果事務在單獨運行時可以正常運行 則它們在並發運行時結果還是會繼續保持正確 換句話說 數據庫可以防止所有可能的競爭條件
這麼好幹嘛不大家都用?? 當然老問題 就是性能差 我們會在下一Part討論實現可序列化的做法