Designing Data-Intensive Application - Storage and Retrieval
January 19, 2019您所看到的本網站只會用盜版爬蟲抄襲複製別人原創文章的沒梗網站 爬蟲完後還不檢查內容直接發佈 施主還是趕快關閉本網站比較安全 阿彌陀佛
請支持原創文章 拒絕盜版爬蟲 麻煩讀者移駕至本文固定連結
這是Designing Data-Intensive Application的第一部分第三章節: 存儲與檢索
本文所有圖片或代碼來自於原書內容
存儲與檢索
一個數據庫最基本要完成兩件事 當給你數據的時候你存的下來 跟當跟你要數據的時候你給的出來
在數據模型和查詢語言中 我們討論了程序員寫入數據庫的格式 和要回數據的機制 這一章則是從數據庫的視角 來聊聊數據庫是如何存儲我們的數據 以及如何在需要時提供數據
存儲引擎分成兩大類 事務性負載(transactional workload) 和 分析性負載(analytics workload) 我們會在事務處理還是分析?探討區別 並在列存儲中討論一系列針對分析存儲引擎的優化
我們會研究兩大類的存儲引擎 日誌結構(log-structured)的存儲引擎 以及面向頁面(page-oriented)的存儲引擎
您所看到的本網站只會用盜版爬蟲抄襲複製別人原創文章的沒梗網站 爬蟲完後還不檢查內容直接發佈 施主還是趕快關閉本網站比較安全 阿彌陀佛
請支持原創文章 拒絕盜版爬蟲 麻煩讀者移駕至本文固定連結
抓穩 出發囉
數據庫的數據結構
跟所有系統設計一樣 從最簡單的開始優化
世上最簡單的數據庫 可以用兩個Bash函數實現
#!/bin/bash
db_set () {
echo "$1,$2" >> database
}
db_get () {
grep "^$1," database | sed -e "s/^$1,//" | tail -n 1
}執行
> db_set key value就可以把(key, value)存進database
然後使用
> db_get key就可以得到你的value
key跟value甚至可以是任意的Json
> db_set 123456 '{"name":"London","attractions":["Big Ben","London Eye"]}'
> db_set 42 '{"name":"San Francisco","attractions":["Golden Gate Bridge"]}'
> db_get 42
{"name":"San Francisco","attractions":["Golden Gate Bridge"]}道理很簡單 我們把它存進一個檔案裡 每行是用逗號分隔的key-value pair
每次呼叫db_set 都往檔案的最後加新行 所以我們找的時候找最後一個(tail -n 1)
> db_set 42 '{"name":"San Francisco","attractions":["Exploratorium"]}'
> db_get 42
{"name":"San Francisco","attractions":["Exploratorium"]}
> cat database
123456,{"name":"London","attractions":["Big Ben","London Eye"]}
42,{"name":"San Francisco","attractions":["Golden Gate Bridge"]}
42,{"name":"San Francisco","attractions":["Exploratorium"]}您所看到的本網站只會用盜版爬蟲抄襲複製別人原創文章的沒梗網站 爬蟲完後還不檢查內容直接發佈 施主還是趕快關閉本網站比較安全 阿彌陀佛
請支持原創文章 拒絕盜版爬蟲 麻煩讀者移駕至本文固定連結
很好懂 看起來不起眼的實作 卻已經描述了日誌結構的精神
許多數據庫內部都是使用日誌(log) 也就是一個append-only的文件 當然真的數據庫有很多問題需要處理(如並發控制, 回收Disk空間以避免日誌無限增長, 處理錯誤與部分寫入等等) 但基本原理一樣 且之後在本書中你會重複看到
大部分地方log指的是Application log 也就是即應用程序輸出的一份描述發生什麼事的一個檔案 本書會在更廣義的情況下用這個詞 :
An append-only sequence of records
不需要是人類讀得懂的 他甚至可能是二進制格式
現在開始優化 當這個文件越來越大的時候 性能會越來越差 因為每次的db_get會從頭到尾掃過整個文件 複雜度O(n)
為了要高效率的查找 我們需要呼叫大名鼎鼎的英雄 - 索引(index) 本章會介紹一系列的索引結構並進行對比 中心思想是把每個數據留下一些metadata當作路標 幫助你找到想找的數據
當然 一個數據庫不一定只能有一個或一種索引 你可以用不同的方式找到相同的數據
索引是從主要數據衍生出來的附加結構 有不少的數據庫允許你加入或刪除索引 這本身不影響數據的內容 影響的只是查詢的性能
但是當然有得就有失 你需要索引幫助你查詢得快一點 那你在寫入的時候 就要多寫久一點(留下路標) 所以這就是索引的難題 你要如何取捨讀和寫的性能 這取決於你對你數據庫的了解 才知道該對誰索引 如何索引 才可以得到你最想要的讀寫性能
Hash索引
最簡單的開始 Key-Value索引 雖然簡單但也是其他複雜索引的底子
中心思想很簡單 與其每次都把檔案從頭找到尾 我為什麼不用一個Hash Map把每個key的位置記下來就好了?
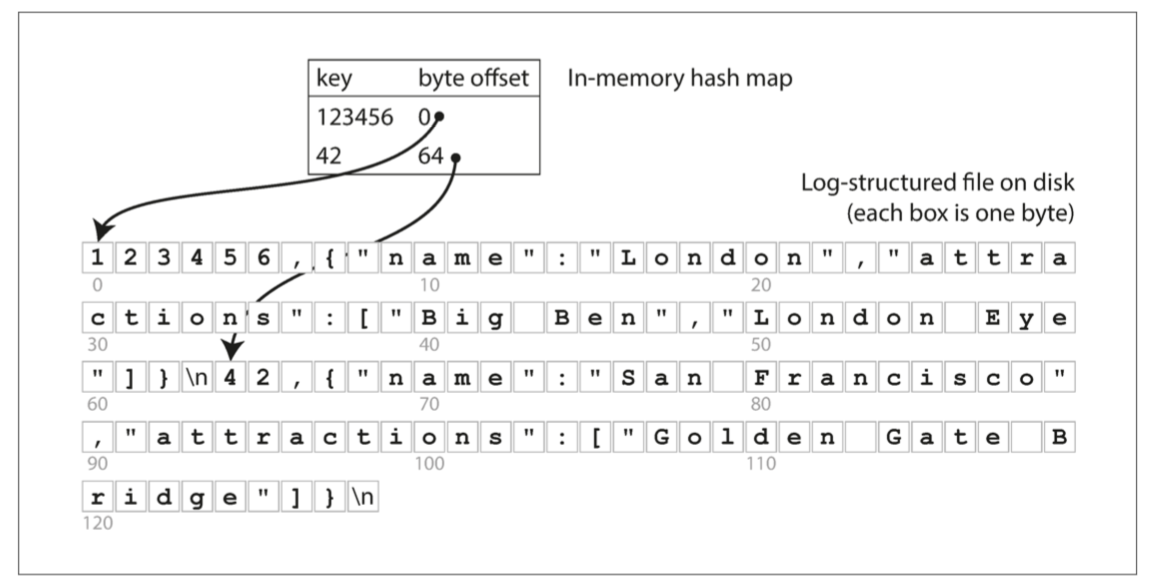
輕輕鬆鬆 我要查找的時候 就先去看這個Hash Map 找到檔案的offset之後 從那裡開始讀value就搞定!
現實生活中 Riak的搜尋引擎Bitcask就是使用這個方式 那使用時機是什麼呢 就是擁有的key數目不多 但每個value很常被更新的情況
來個例子 比如說你是一個小youtube 你的key是存影片的網址 value是觀看次數 這種類型的數據 更新舊數據的需求遠遠大於增加新數據 而且key不多的話 只要放得進內存 這個簡單的實作會意外的適合
開始優化 目前為止我們都是寫入同一個文件 我們要怎麼避免Disk被用光呢 一個常見方法是設一個檔案的最大size 當你的log成長到這個大小 就開一個新的檔案寫 舊的檔案就可以壓縮(compaction) 壓縮就是把不要的東西拿掉 這裡就是只留每個key最新的value
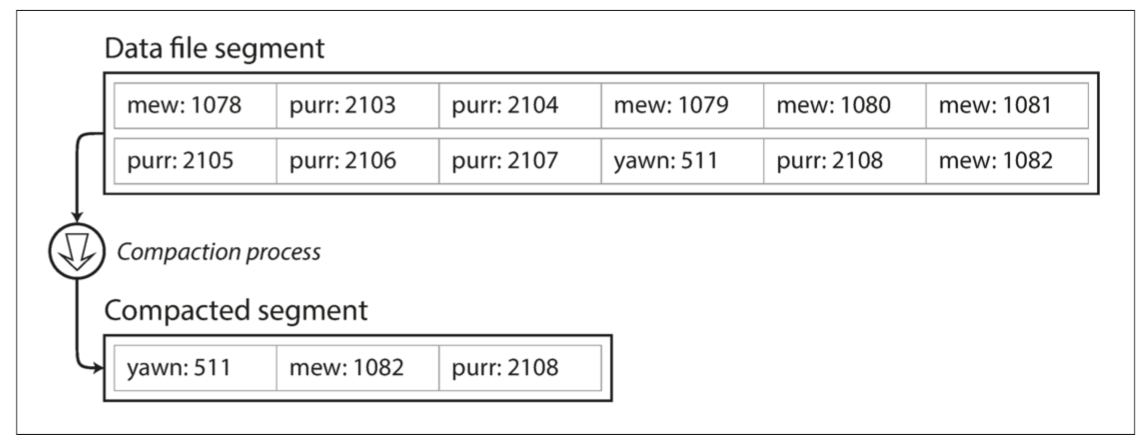
當然也可以壓縮+合併

當我有很多個檔案 就代表我有很多個Hash map 所以查詢的時候 要從最新的map開始找 再一路往回找
難點
要把這個簡單的想法真正在現實生活中應用 還需要克服幾個難點
1.文件格式: CSV不是儲存log最好的方式 最好的方式是二進制格式 更快更簡單
2.刪除記錄: 如果要刪除一個key-value pair 必須在檔案中加入一個特殊的刪除記號(tombstone) 當檔案合併時 這個特殊記號會告訴process放棄所有相同key的記錄
3.崩潰恢復: 如果數據庫重新啟動 Hash-map直接不見(因為被保存在內存) 你會需要把文件全部遍歷一遍來recover你的hash map 這讓數據庫重啟變得十分痛苦 Bitcask的解法是把每個檔案的snapshot不定期存起來 讓重啟變快
4.部分寫入記錄: 數據庫隨時可能崩潰 如果正在寫log的時候數據庫崩潰了 就需要用一些checksum等等的機制去修復/刪除部分寫入的記錄
5.並發控制: 寫的thread只能有一個 但是讀的thread可以有很多個
難點講完了 接下來討論幾個問題 你可以想像是面試官問你問題
問題
1.為什麼一定要append-only? 我有hash-map可以快速找到舊key的位置 我overwrite不行嗎??
A1. Sequential Write的速度 » Random Write 在磁盤旋轉硬盤上差異就很大 在SSD上差距小一點 我們會在比較B樹和LSM樹裡討論
A2. 並行比較容易做 要是可以Random Write 幾乎不可能併行化
A3. 崩潰回復(Crash recovery)比較簡單 Random Write到一半回覆的話基本沒救 沒什麼機制能挽回
A4. merge舊的檔案的時候 也不用擔心數據隨著時間跑來跑去的問題
侷限
1.Hash map必須要能放的進內存
2.範圍查詢效率差 你無法查詢kitty0000 - kitty9999之間的所有key 你必須在hash-map中單獨找每個key
接下來我們會來討論比較沒限制的索引結構
SSTables和LSM樹
剛剛的Hash索引 每個紀錄都照順序被寫入檔案 越晚寫的同樣key的記錄比早寫的優先 除此之外 文件中的記錄順序不重要
現在我們來做一點小變化 我們現在要求文件的順序按照key排序 這就是Sorted String Table(SST) 除了保證順序的同時 還不讓key重複
缺點就是寫入比較慢
您所看到的本網站只會用盜版爬蟲抄襲複製別人原創文章的沒梗網站 爬蟲完後還不檢查內容直接發佈 施主還是趕快關閉本網站比較安全 阿彌陀佛
請支持原創文章 拒絕盜版爬蟲 麻煩讀者移駕至本文固定連結
優點如下:
1.合併檔案簡單又高效: 其實就是merge sort

當key有重複 就拿比較晚生成的segment
2.你的索引不需要有所有的key: 你的key可以sparse一點 比如說你要找handiwork這個字 而你的hash map裡有handbag -> 102134和handsome -> 104667 你就可以直接從102134開始掃
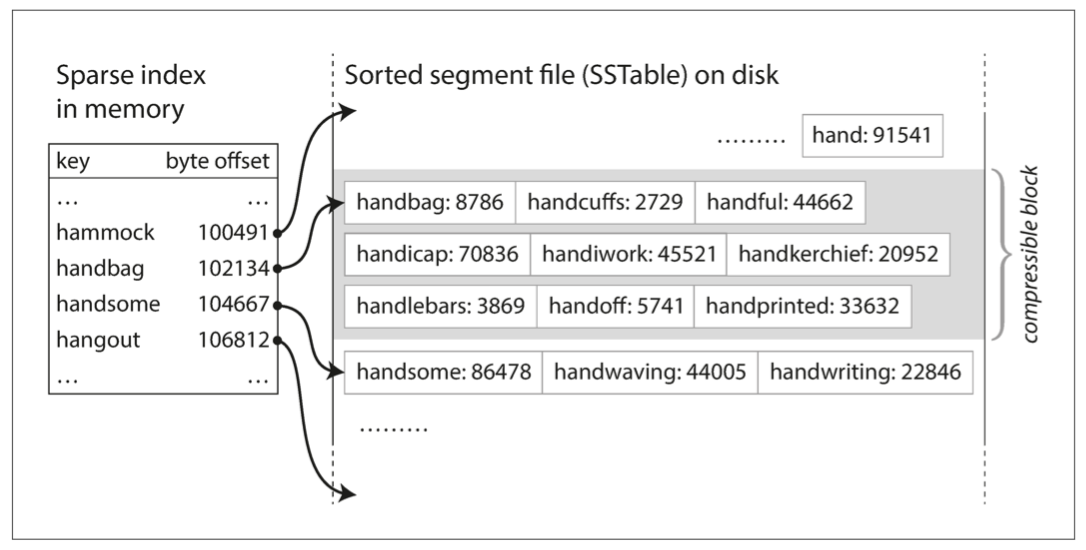
3.key跟key的offset之間的文件可以壓縮: 如同上圖的灰色區段 等到需要掃灰色區域的時候再拿出來 不用的時候可以壓縮後放在disk裡 省空間 省IO開銷
構建和維護SSTables
那麼要如何讓你的數據照key排序呢?
在Disk上維護的方法 可以參照B樹 而在內存上維護的方法有很多 常聽到的就是紅黑樹跟AVL樹 使用這些數據結構 你可以用任何順序插入key
所以現在我們優化後的存儲引擎可以做以下的事
1.寫入key時 將其添加到內存的平衡樹結構 這個內存數也稱為內存表(memtable)
2.當內存表的size大於某個門檻(幾兆byte) 可以把它當作SSTable檔案寫進disk 在存的過程中發生的寫入就寫到另外一個新的內存表
3.怎麼處理讀request呢 就先從memtable找 找不到在再最近的disk segment找 一路往回找
4.後台一直有個process在對文件segment進行壓縮
這個方案的唯一問題 就是如果系統突然crash 內存的東西會全部消失 所以每個寫需求除了寫進memtable 還要額外寫進一個log file 讓你在崩潰後可以回復你的內存 當這次的memtable被寫進Disk時 這個log file就可以刪了
Lucene
剛剛描述的算法也叫做LSM-tree(Log-Structured Merge Tree) 也是LevelDB和RocksDB中使用的key-value存儲引擎的算法 Cassandra和HBase也用到了這個算法(經由Google的BigTable paper)
Lucene是Elasticsearch和Solr使用的一種全文搜索的索引引擎 他也使用類似的方法來存儲辭典 全文索引的做法就是 存一個key-value的mapping key是搜尋的term value是出現過這個term的文件id的列表
在Lucene裡 這個key-value結構就是存在SSTable中 然後根據需要在後台合併
性能優化
再來繼續優化
1.我們說一個讀需求 先在內存找 找不到再去硬碟裡最新的segment找 一路往回找 要是一個讀需求找一個不存在的key 那會找非常久
為了優化這一個use case 存儲引擎會再maintain一個Bloom filter(可以快速讓你知道一個key在不在所有硬碟裡 不用真的一個一個找)
2.壓縮的優化 主要分兩種 size-tiered跟leveled 壓縮
size-tiered壓縮 就是比較新比較小的SSTable會被併進比較老比較大的SSTable
leveled壓縮 又是按照資料的新舊程度分層處理(我們預期早期被輸入的資料比晚期被輸入的資料更少被查詢) 所以新的SSTable就劃分成比較細的檔案 舊的SSTable就往上層合併
吞吐量
LSM樹的中心思想 就是可以保存一系列可以在後台合併的SSTables 就這麼簡單
即使之後資料量變大 數據量比內存大很多也沒關係 因為數據在硬碟裡是有序的 所以可以高效的進行範圍查詢
而且硬碟的寫入是sequential的(我們當內存通過一個門檻才會寫入硬碟 每次都是append) 所以LSM樹可以支持很高的吞吐量
B-tree
在幾乎所有的關係數據庫中 B-tree是標準的索引實現 許多非關聯數據庫也在用
就像SSTable一樣 B-tree保持著照key排序的key-value pair 但是背後設計的理念很不一樣
我們之前看到的日誌結構索引都將數據分解成可變大小的段 且按照順序寫進硬碟segment 但B-tree則是把數據庫分成很多大小一樣的segment(通常是4KB) 而且一次只能讀取或寫入一個page 這樣的設計更接近底層的硬碟(因為disk也被安排在固定大小的block中)
每個頁面 都可以使用一個地址來標示 這讓一個頁面可以引用到另一個頁面 就像在硬碟裡的pointer 而我們利用這些指針來建構一個樹
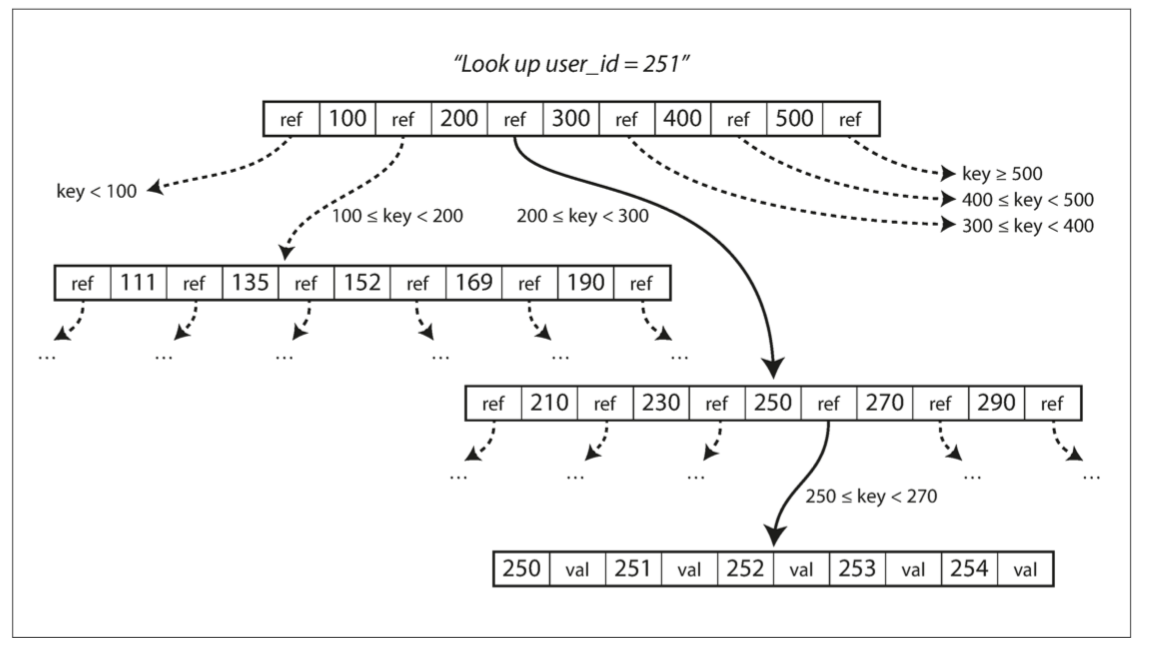
每一個頁面都包含了幾個key和幾個對子頁面的指針
從一個根頁面(最上面那個)開始 假設要找userId = 251 那就會找200-300中間的指針找到下一個頁面 一路找下去 就會找到251 你就可以再去看251的值是什麼(可能直接在那個entry裡 可能是指到value的指針)
一個頁面對子頁面引用的數量稱為branching factor 上圖的例子branching factor就是6 實戰中 branching factor通常是好幾百
算法
1.更新: 就是找到那個entry 把value改掉
2.加入新key: 找到屬於這個範圍的子page 加到子page裡 如果子page沒有空間容納新key 就分成兩個
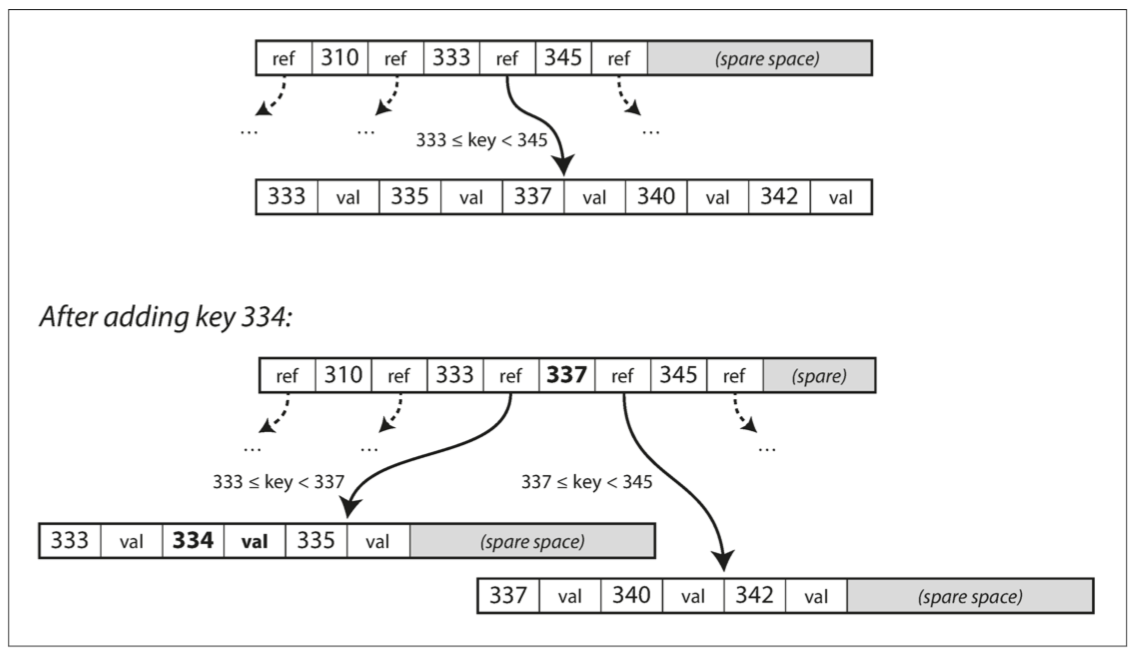
這個算法必須保持樹的平衡 有N個key的樹高度應該是logN 而大多數的數據庫都是3-4層就搞定(BF500 一頁4KB的數據四層 可以存256TB)
一樣 開始優化
讓B-tree更可靠
B-tree基本的底層操作 就是用新數據覆蓋Disk上的頁面 這和LSM樹形成強烈對比 後者只append到硬碟 而不修改硬碟
而要在磁性硬碟中修改硬碟的檔案 你必須將磁頭移動到正確的位置 等待旋轉盤上的正確位置出現 然後用新的數據覆蓋適當的扇區 在SSD上會更複雜
覆蓋硬盤檔案只是理想情況 某些情況我們還必須要平衡樹 這代表需要拆分兩個頁面 並在兩個頁面都要寫 還要改parent頁面的引用 這是一個危險的操作 如果在這一系列複雜的操作中途崩潰 那會導致一個損壞的索引(比如一個孤兒頁面沒有被父頁面連到)
要怎麼讓崩潰可被修復呢
我們可以多維護一個數據結構 預寫式日誌(WAL write-ahead-log) 也是一個append-only的檔案 在實際修改B-tree時先在這WAL上寫下來 要是之後崩潰 以WAL為主來回覆內存
還有一個複雜的情況就是並行 如果多個線程要一起修改B-tree 需要仔細地處理並發問題 通常可以用個輕量級鎖(latches)來保護樹的結構
比較B樹和LSM樹
通常LSM樹的寫入速度更快 而B樹的讀取速度更快
LSM樹的優點
第一點 是寫入的速度
B樹的寫入 必須寫入至少兩個資料結構 先寫入WAL 再寫入樹頁面(也許還需要再分頁)
而LSM樹通常能夠比B樹支持更高的寫入吞吐量 因為它是順序寫的 不需要重寫樹中的多個頁 這種特性在磁性硬盤上很重要 sequential write比random write快得多
第二點 是磁碟空間的應用
因為LSM Tree可以被更好的壓縮 所以硬碟空間的使用通常比B樹索引更小一些 而因為LSM Tree不是頁面取向的實作 而且會時不時的做壓縮 因此磁盤消耗更低一些 相比而來 B樹的一個頁被切分或是一行裝不進一頁時 頁中的一些空間就沒有被利用到 常常會導致磁盤碎片
LSM樹的缺點
雖然LSM很常壓縮來省空間 但缺點就是如果壓縮到一半有讀請求 就會需要等很久 這種特殊情況不會影響到p50 但卻對p999有要命的延遲 相較而言 B樹的性能就比較好預測
如果寫的throughput很高 而且壓縮策略沒好好處理 可能會有壓縮趕不上新數據的情況 這樣讀的性能也會連帶影響
其他索引結構
目前我們只討論了key-value索引 就像是關聯數據庫中的primary-key索引 primary-key代表的table唯一的一行 或是document數據庫的一個的檔案 或是圖形數據庫中的一個頂點
二級索引(Secondary index)也很常見 你可以在關聯數據庫中用CREATE INDEX 在同一個表上創建多個二級索引 這些二級索引對於join的效率至關重要
比如說熟悉的比爾蓋茲
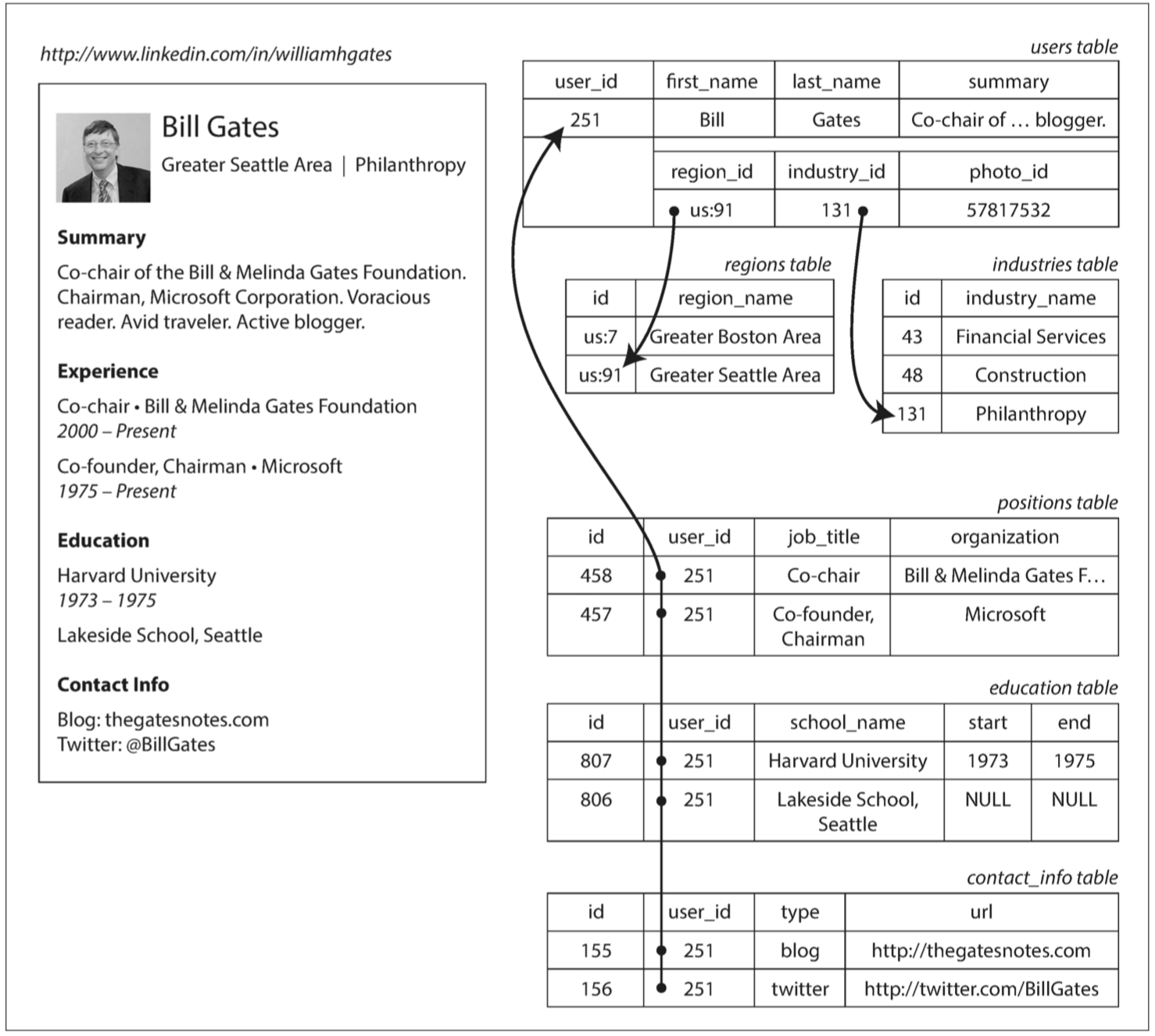
如果我們對每個表(regions table, positions table, education table)中都對user_id做了二級索引 我們很快就可以找到某個user_id在每個table的row
二級索引跟key-value索引差別就是 索引的值不是唯一的(比如說如果我想對last name作二級索引 那我每次搜尋James找到的數據不會只有一個) 這有兩種方式可以解決
1.讓索引的值是一個list of matching rows
2.把每個entry加上一個row number 讓他變成不是唯一
不論哪種方式 B樹和日誌結構索引都可以用作二級索引
將值存儲在索引中
我們知道索引的key是用來搜尋用的 但索引的值應該放什麼呢? 有兩個可能 一個是實際的文檔/頂點/記錄 另一個則是實際紀錄的引用 後者情況的話 實際的row被存放的地方稱為堆元件(heap file) 而且紀錄沒有絕對的順序(可以都是append-only 也可以overwrite舊紀錄) 這個做法的好處是 如果有不同的二級索引指到同一個記錄 這個記錄不需要duplicate到各個二級索引中
如果要update某一個key 分兩種情況 如果新value的size不比舊value大 那就直接覆蓋 如果新value的size更大的話 那可能這個heap-file要換地方存 那要碼所有曾經指到舊heap-file的索引都修改 或是在舊heap-file的位置留下一個指針到新位址
在某些情況下 從索引到堆文件的額外引用對讀取來說性能損失太大 所以你可以考慮把所有的row的data都存在索引裡 稱為Clustered index
筆者註: 這個定義跟我認知的Clustered index不太一樣 我認知的是如果硬碟裡的資料順序跟index的key的順序一樣 才叫Clustered index 我猜想是不同地方對於相同的詞有這不同定義 如果有讀者知道正確定義或是看出我哪裡搞混 請告訴我 感激不盡
在Clustered index(在索引中存儲所有row數據)和Nonclustered index(僅在索引中存儲對數據的引用)之間的折衷稱為包含列的索引(index with included columns)或覆蓋索引(covering index) 你可以只把部分比較常被query的訊息存在索引內 而不是所有數據都存在索引內
當然 缺點就是增加額外的存儲空間開銷
多列索引 multi-column indexes
目前的索引的是一個key對到一個value 如果我們需要同時查詢一個表中的多個列(或文檔中的多個字段) 這顯然不夠
最常看到的多列索引被稱為連接索引(concatenated index) 它通過將一列的值追加到另一列後面 將多個字段組合成一個鍵 比如說 你在一個電話簿中 加一個多列索引(lastName, firtName) 你可以用這個索引找出所有特定lastName的人(因為索引有sort) 你也可以用這個索引找特定lastName+firstName的人 但如果你想找某個特定firstName的人 抱歉做不到
多維索引 multi-dimensional index
多維索引是一種查詢多個列的更一般的方法 這在地理空間的數據特別重要
比如說 餐廳搜索網站有個數據庫 包含每個餐廳的經緯度
今天如果要支持一個sql空間查詢
SELECT * FROM restaurants
WHERE latitude > 51.4946 AND latitude < 51.5079
AND longitude > -0.1162 AND longitude < -0.1004;B樹跟LSM樹都無法高效的查詢 因為我們有對經度跟緯度分別索引 所以它可以回傳一個經度範圍內的所有餐廳(但緯度可能是任意值) 也可以回傳一個緯度範圍內的所有餐廳(但經度可能是任意值) 無法同時滿足
有兩個選擇
1.用space-filling curve將二維位置轉換為單個數字 再用正常的索引
2.特殊化的空間索引 比如R-tree
本書中沒有特別深入這兩個做法的算法 有興趣的再深入研究 我們只考慮use-case
除了二維空間還能幹什麼呢 我們還可以搜尋顏色! 怎麼做呢 就把(R, G, B)作個多維索引 就可以找到你想找的相近顏色的東西! 或者是任何二維的數據 比如說(時間 溫度) 你就可以找2013年五月氣溫在20-25度的日期
您所看到的本網站只會用盜版爬蟲抄襲複製別人原創文章的沒梗網站 爬蟲完後還不檢查內容直接發佈 施主還是趕快關閉本網站比較安全 阿彌陀佛
請支持原創文章 拒絕盜版爬蟲 麻煩讀者移駕至本文固定連結
全文搜索和模糊索引
目前為止的討論 都是在你有確切的數據 確切的key-value配對 那如果你想找的是拼錯的key 這就需要不同的技術
你常看到搜尋引擎可以在你拼錯或是幫你找你輸入的同義詞 比如Lucene就可以幫你找Edit Distance=1的所有詞(加/減/改 一個字母) 怎麼做到的呢 他用了一種類似SSTable的數據結構來存儲它的字典 只是索引變成一個有限的狀態機(finite automate machine) 然後可以被轉成Levenshtein automaton 這個就支援了一個給定edit distance的搜尋
在內存中存儲一切
目前討論的東西都是如何存取硬碟 硬碟有著很差的讀寫效率 那為什麼我們堅持如此呢 因為兩點
1.硬碟耐用 電源關閉資料還在
2.成本低 便宜
但隨著科技發展 內存變得便宜 把所有東西保存在內存逐漸變得可能(散布在多個機器中達到備份效果)
某些基於內存的key-value存儲(像是Memcached)僅用於緩存 如果重新啟動導致東西不見 也可以接受 但其他內存數據庫需要支持持久性的話 可以有如下方式
1.電池供電的RAM
2.將changes of log寫入Disk
3.不定時把快照snapshot寫入Disk
4.複製到其他機器的memory
當in-memory數據庫重啟時 它需要從disk或是網路重載狀態 雖然為了持久性必須寫log到disk 但讀需求完全由內存處理 而且這個append-only的寫很快
當我們決定主要使用內存後 很多優化都可以做了 比如說Redis為各種資料結構(priority-queue, sets)提供了類似數據庫的接口 這些實作都很簡單
事務處理系統還是分析系統
在高層次上 我們看到存儲引擎分為兩大類
1.優化事務處理(Online Transaction Processing): 訪問模式類似於處理業務事務 搜尋查找少量紀錄 並且需要時更新覆蓋紀錄
2.優化分析(Online Analytics Processing): 需要掃描大量紀錄 每個記錄只讀取幾個column並統計匯總 比如說 一月份我們每個商店的總收入是多少 或是 我們在最近的推廣活動中銷售多少香蕉 等等
| 屬性 | 事務處理 OLTP | 分析系統 OLAP |
|---|---|---|
| 主要讀取模式 | 查詢少量記錄 按key讀取 | 在大批量記錄上聚合 |
| 主要寫入模式 | 隨機訪問 要求低latency write | Bulk import 或是event stream |
| 主要用戶 | 終端用戶 通過Web應用 | 內部數據分析師 |
| 處理的數據 | 數據的最新狀態 | 歷史事件 |
| 數據大小 | GB ~ TB | TB ~ PB |
剛開始 同一個數據庫可以同時提供這兩種用途 但最近的趨勢 則是不在OLTP的系統進行分析 而在一個單獨的數據倉庫(Data warehouse)進行分析
數據倉庫 Data warehouse
為什麼需要把數據倉庫單獨分開呢 因為OLTP的要求就是高度可用性 低延遲處理transaction 這些要求對於業務運作至關重要
通常分析需要很多讀需求掃瞄數據庫 而分析的要求大多數情況是用來優化 沒有重要到需要使用許多昂貴的查詢來影響業務運作的性能
如果有個獨立的數據倉庫 你做分析的愛怎麼跑就怎麼跑 而不影響到OLTP的操作
數據倉庫包含了OLTP系統的read-only的copy 使用定期的數據dump或是data stream從OLTP系統fetch數據 轉換成適合分析的模式後存進數據倉庫 此過程稱為Extract-Transform-Load(ETL)
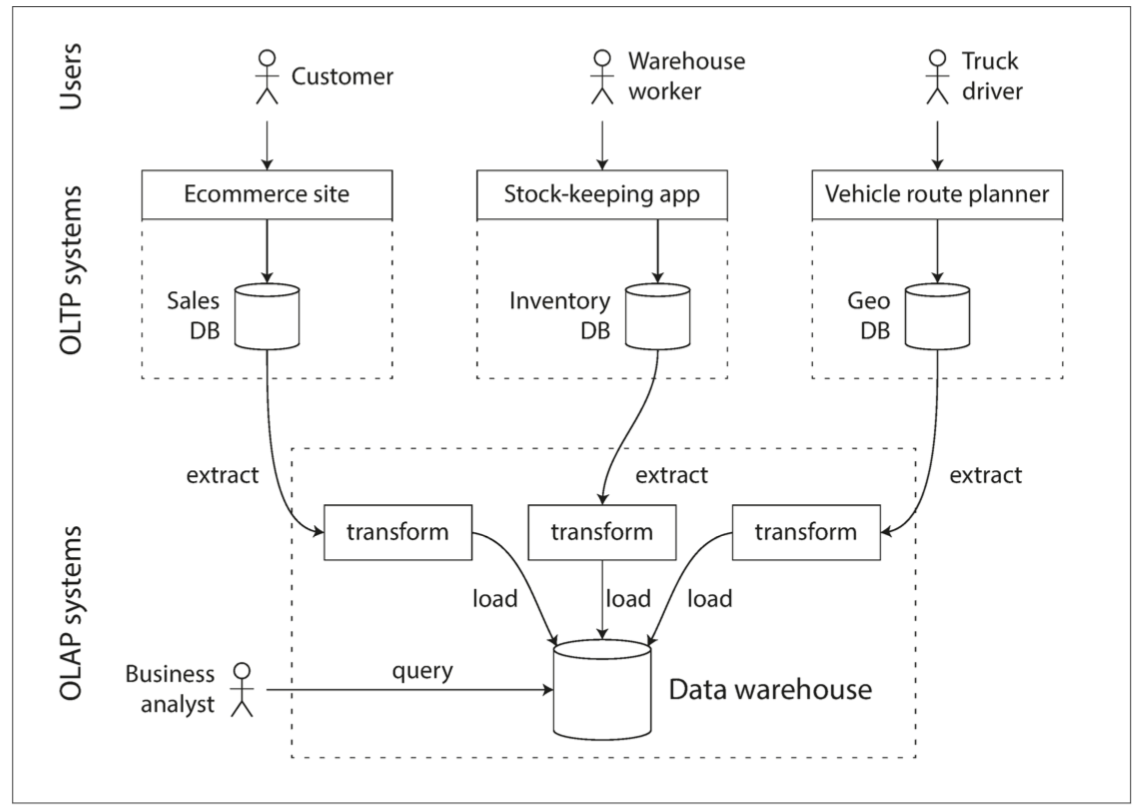
數據倉庫在大公司是非常常見的 一個大優勢 是可以針對分析模式進行優化 本章目前為止提到的索引算法對於OLTP來說都工作的很好 但對於OLAP就沒那麼好 在剩下的章節 我們來看為了分析而優化的存儲引擎
星型和雪花型
在事務處理領域中 可以因為你應用程式的需要 使用不同的數據模型 但在分析領域中 數據模型的選擇就少了很多 許多數據倉庫都很制式化 稱為星型模式
以下例子是食品零售商處的數據倉庫 中心是一個fact_table fact_table每一行指的是一個事件
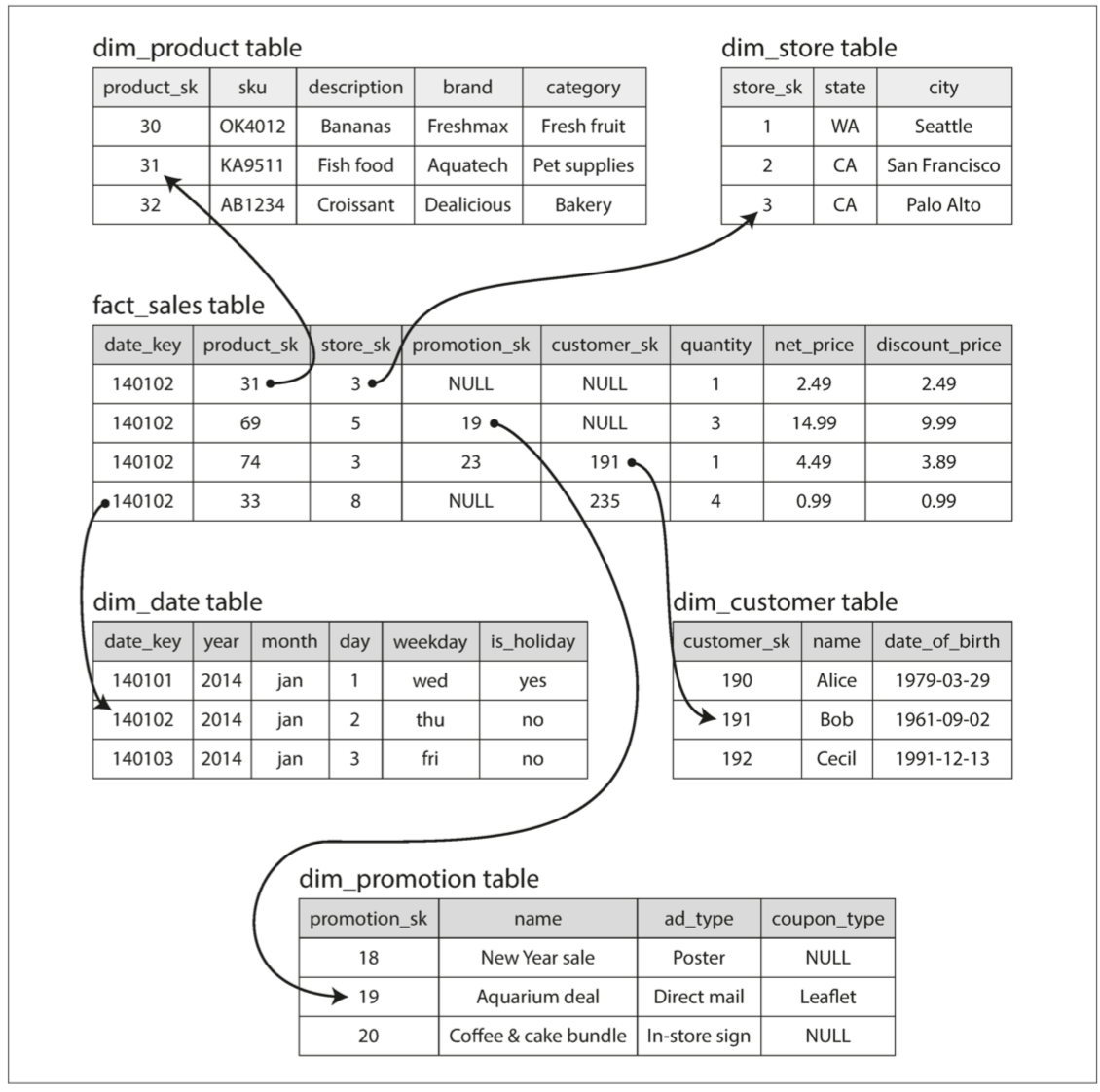
fact_table的某些列是屬性 例如產品的銷售價格或成本 其他列則是對於其他表的引用(foreign key) 其他表在此稱為維度表(dimensional table)
這樣讓你可以在查詢fact_table的基礎中 當你需要的時候再使用一些join來decorate你的查詢 甚至連日期都可以建一個維度表 你可以多記錄一些資訊比如國定假日之類的
星形模式名稱由此而來 當表關係可視化時 事實表在中間 由其他dimensional table包圍
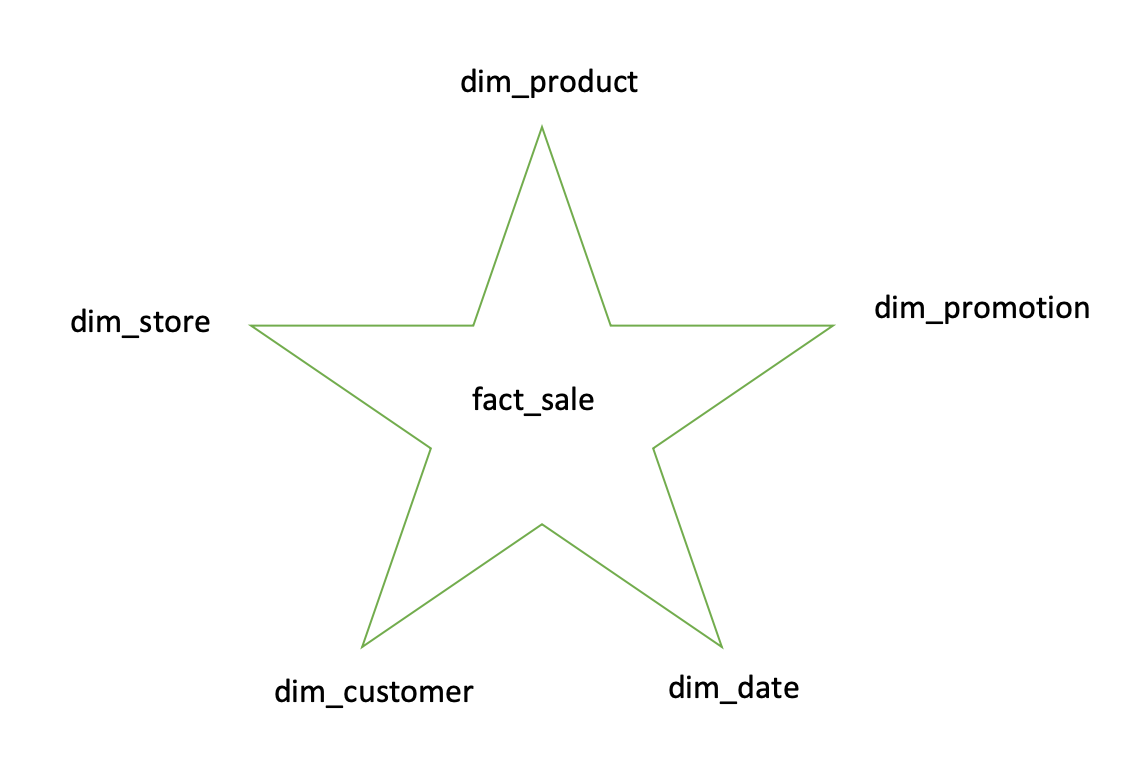
你也可以再把dim_product table再細分下去 比如說把brand變成brand id成為foreign key 再由更細微的dimensional table包圍 這就是雪花模式

列存儲
可想而知的 維度表通常比較小(數百萬行) 但是fact_table通常有數萬億行數PB的數據 如何高效的存儲和查詢很有挑戰性 本節主要針對事實表的存儲進行優化
儘管事實表通常超過100個column 但用於分析的查詢 大多情況只需要其中的4-5個列 (你不會在分析查詢看到SELECT *)
以下的查詢 查詢了大量的row 但卻只拿了事實表中的3個column
SELECT
dim_date.weekday,
dim_product.category,
SUM(fact_sales.quantity) AS quantity_sold
FROM fact_sales
JOIN dim_date ON fact_sales.date_key = dim_date.date_key
JOIN dim_product ON fact_sales.product_sk = dim_product.product_sk
WHERE
dim_date.year = 2013 AND
dim_product.category IN ('Fresh fruit', 'Candy')
GROUP BY
dim_date.weekday, dim_product.category;要如何有效的執行此查詢呢? 複習一下OLTP 存儲都是以row為方向進行佈局 表格一行中的所有值都存在一起 要處理以上查詢 可能要在fact_sales.date_key跟fact_sales.product_sk上面建立索引 但即使這麼做 還是必須把所有符合date_key條件跟product_sk條件的row從硬碟移到內存 然後再開始filter 還是需要很久 因為資料量實在太大
如果我們以column方向進行存儲佈局呢? 不是把所有同一行的東西存在一起 而是把同一列的東西存一起 如果每一個column都是一個分開的檔案 那其實只需要pasre那個檔案就可以
下圖試著把每一個colume分開存到另一個檔案
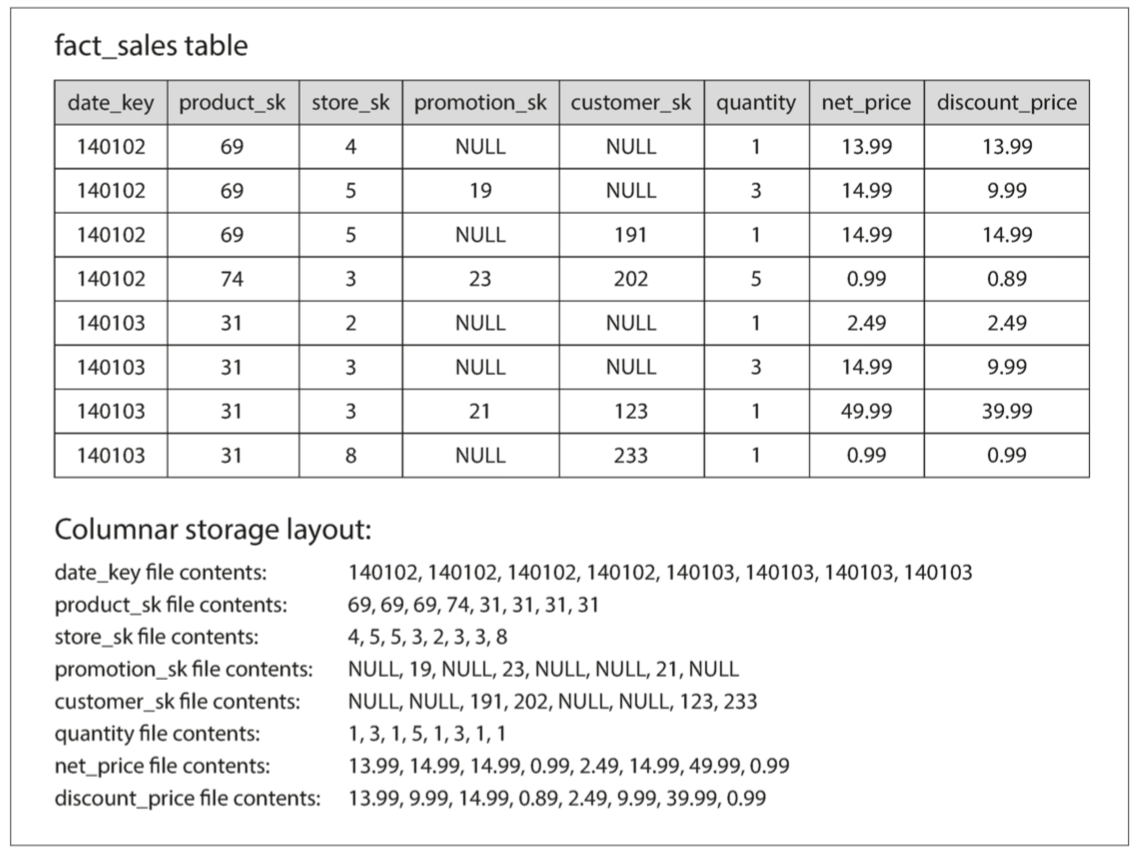
如果你需要組裝起真正的row 就把每個檔案的row number組合起來就可以
列壓縮
除了只需要從硬碟讀出需要的列的檔案之外 我們還可以通過壓縮數據來進一步降低對磁盤吞吐量的需求
一樣的例子 有許多重複的值 這就很好利用bitmap encoding壓縮

通常情況 distinct的值的數目會比總row的數目少很多(你可能有數十億的交易 但卻只有十萬個商品) 我們對於每個出現過的value都建了一個bitmap 如上圖所示
您所看到的本網站只會用盜版爬蟲抄襲複製別人原創文章的沒梗網站 爬蟲完後還不檢查內容直接發佈 施主還是趕快關閉本網站比較安全 阿彌陀佛
請支持原創文章 拒絕盜版爬蟲 麻煩讀者移駕至本文固定連結
而大多數情況下 每一個bitmap都會有大量個0(sparse) 這又讓我們可以再次使用Run-length encoding壓縮
而且這種存儲很適合這種操作
WHERE product_sk IN(30,68,69)你只要讀出value=30, 68, 69的三個bitmap 把這三個bitmap OR 一下 就搞定
WHERE product_sk = 31 AND store_sk = 3你只要讀出value=31, 3的兩個bitmap 把這兩個bitmap AND 一下 就搞定
列存儲中的排序順序
基本上在列存儲中 我們不介意row的順序 照insert順序就可以 我們就只要每次一有新的紀錄 就把每個列文件append一個值而已
但是我們也可以強制排序 就像我們對SSTable做的那樣 並加上索引
注意針對每個列文件單獨排序是沒有意義的 因為之後拼不起來 我們只能選擇一個我們認為最重要的列排序 比如說你發現很多分析都是用日期當作WHERE的條件 你就可以把日期那個文件這日期排序 其他文件都跟著相同順序存
再者 對於相同的日期 你可以再選第二的要比較的列文件(比如說product_name) 再更精準的排序
這樣子你的列存儲就可以很有效率的回應類似需要在特定日期範圍內按產品對銷售進行分組或過濾的查詢
排序的另一個好處 是可以再幫助壓縮 如果主要排序列(比如日期)沒有那麼多不同的值 那同樣的值在排序完後會重複很多次
總結
我們看到存儲引擎分為兩大類:優化事務處理(OLTP)和優化分析(OLAP)
-
OLTP系統通常面向用戶 這意味著他們可能會看到大量的請求 應用程序給定key來請求記錄 存儲引擎使用索引來查找所請求的key的數據 bottleneck往往是Disk Seek Time
-
OLAP系統主要由業務分析人員使用 它們處理比OLTP系統少得多的查詢量 但是每個查詢通常要求很高 需要在短時間內掃瞄數百萬條記錄 bottleneck往往是Disk Bandwidth 列存儲是這種工作負載越來越流行的解決方案
OLTP方面 有兩個主要的流派
1.日誌結構學派: 只允許附加到文件和刪除過時的文件 但不會更新已經寫入的文件 BitcaskSSTables LSM樹 LevelDB Cassandra HBase Lucene等都屬於這個組
2.直接更新學派: 將磁盤視為一組可以覆蓋的固定大小的頁面 最鼎鼎大名的就是B樹
日誌結構學派是比較最近的發展 他們主要把隨機寫入轉換成順序寫入 實現高血吞吐量 而我們也介紹了一些索引結構來優化查詢
OLAP方面 因為我們需要在大量的row之中掃描 索引的重要性就降低很多 反之 緊湊的編碼壓縮就變得重要 因為這影響了我們從Disk拉出多少資料 我們也討論了列存儲 來達到這個目標
身為一個專業的程序開發員 如果您掌握了有關存儲引擎內部的知識 你就能更瞭解哪種工具最適合你的應用程序 當你需要調整參數 也知道怎麼樣最符合你的需求