Designing Data-Intensive Application - Reliable, Scalable, and Maintainable Application
January 05, 2019這是Designing Data-Intensive Application的第一部分第一章節: 可靠性,可伸展性,可維護性
您所看到的本網站只會用盜版爬蟲抄襲複製別人原創文章的沒梗網站 爬蟲完後還不檢查內容直接發佈 施主還是趕快關閉本網站比較安全 阿彌陀佛
請支持原創文章 拒絕盜版爬蟲 麻煩讀者移駕至本文固定連結
本文所有圖片或代碼來自於原書內容
可靠性 可伸展性 可維護性
直至今日 大部分的應用程式都屬於數據密集型應用 而非計算密集型
我們已經不像以前會被CPU的性能所侷限 而是被數據量 數據複雜度 以及存取速度所限制著
數據密集的應用通常需要提供以下的功能
1.儲存資料 讓這資料可以在之後被讀取(database)
2.記住某些計算複雜度高的運算 用在下次加速(caches)
3.讓使用者依照關鍵字搜尋(search indexes)
4.傳訊息到其他process 異步式進行運算(stream processing)
5.週期性的整理分析海量的資訊(batch processing)
這些功能要求在2019已經不是新聞了 但是你可能不知道的是 我們有不同的建search index的方式 還要各種各樣的cache方法 完全取決於你的應用 這本書會提到非常多你需要知道的工具 並比較各個工具在不同使用情境下的異同
這一章節 我們會先探索幾個數據系統最主要的需求 也就是
您所看到的本網站只會用盜版爬蟲抄襲複製別人原創文章的沒梗網站 爬蟲完後還不檢查內容直接發佈 施主還是趕快關閉本網站比較安全 阿彌陀佛
請支持原創文章 拒絕盜版爬蟲 麻煩讀者移駕至本文固定連結
Reliable, Scalable and Maintainable
數據系統 Data System
Database, Queue, Cache等等的工具應該具有著根本上的區別 那為什麼會混為一談 都稱為數據系統(Data System)呢?
因為這些年來 這些工具的界線已經不是那麼明顯 很多人拿應該要是數據庫的Redis來做Queue 也有人拿應該要是消息隊列的Kafka來做數據庫的持久保證
而且隨著應用程式的要求越來越高 單一個工具已經無法滿足所有需求
來看個書中提到的例子
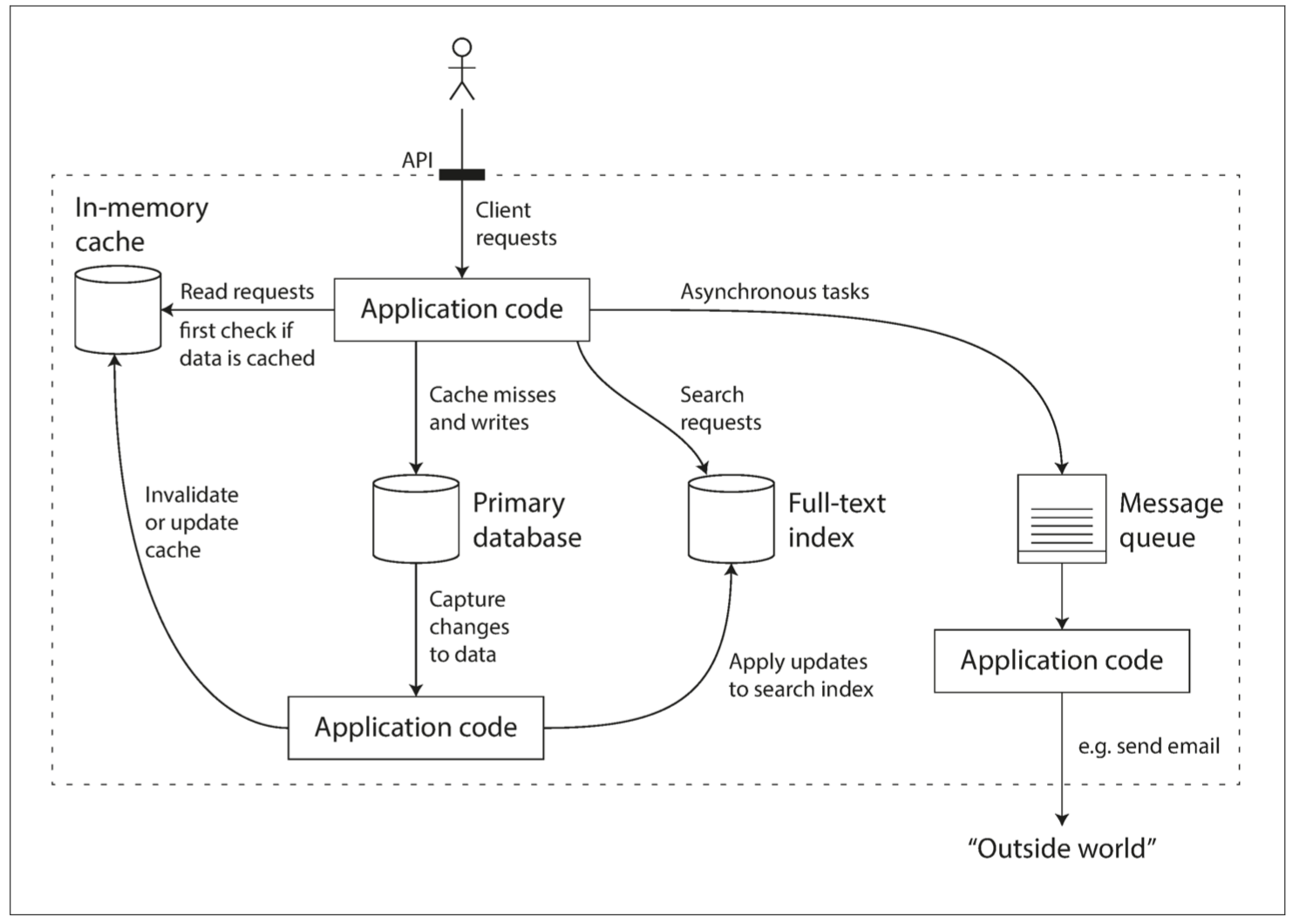
現今的社會通常會單獨將緩存(比如用Memcache)跟全文搜索(比如用ElasticSearch或Solr)或消息隊列(比如用kafka)分離出來 不會把所有的功能都丟給同一個數據庫支持
既然如此 你的工作就是寫好你的應用程式代碼 讓這些工具可以無縫接軌 然後再把複雜的實作封裝在你的API底下 然後你就可以跟你的客戶說
哈囉 我這個應用不但有著Memcache的A功能 還有ElasticSearch的B功能 Kafka的C功能 甚至底層是用D數據庫呢
這本書的目的就是能讓你自由的運用我們手上有的工具 提供所有必需的功能之外 並在設計的時候思考
您所看到的本網站只會用盜版爬蟲抄襲複製別人原創文章的沒梗網站 爬蟲完後還不檢查內容直接發佈 施主還是趕快關閉本網站比較安全 阿彌陀佛
請支持原創文章 拒絕盜版爬蟲 麻煩讀者移駕至本文固定連結
1.當系統出問題時 如何確保數據的正確性和完整性
2.當部分系統退化降級時 如何維持良好性能
3.當負載增加時 如何擴容應對
4.何謂好的API
有非常多的事要考慮 本章節注重於三點最重要的項目
1.可靠性 Reliability: 系統在困境(硬件故障 軟件故障 人為錯誤)中仍可正常工作(正確完成功能 並能達到期望的性能水準)
2.可伸展性 Scalability: 有合理的辦法應對系統的增長(數據量 流量 複雜度)
3.可維護性 Maintainability: 不同的人 在不同的產品週期 都可以高效的在這系統上工作 不論是維護現有行為或是增加新功能
Reliability 可靠性
我們先來定義一下何謂一個應用程式正常工作
1.表現出用戶所期望的功能
2.允許用戶犯錯或是以出乎意料的方式使用應用
3.在預期的負載和數據量下 性能仍然滿足要求
4.系統能防止未經授權的訪問和濫用
以上四點加在一起 就是所謂正常工作
當你知道正常工作的定義之後 我們來定義可靠性
可靠性: 即使出現錯誤 也能繼續正常工作
造成錯誤的原因是故障(fault) 能預料且應對故障的系統稱為容錯(fault-tolerant)或韌性(resilient)
Note: 容錯一詞容易誤導 會讓你以為一個系統可以容忍所有錯誤 但這實際上是不可能的 比如說今天地球爆了你就不可能容忍 所以在討論容錯時 我們只討論特定類型的錯誤
再來一個名詞 失效(failure) 失效跟故障不一樣 故障通常定義為系統的一部分狀態偏離其標準 失效則是系統作為一個整體系統停止向用戶提供服務
我們不可能讓故障的機率降到零 但我們能有防錯機制防止故障導致失效
很不直觀的 在某些矽谷的公司 會故意提高故障率 來測試系統會不會失效 你常聽到的Chaos Monkey就是這個概念
所以我們的目標並不是阻止錯誤(prevent fault) 而是容忍錯誤(tolerate fault)
硬件故障(hardware failure)
當想到系統失效 第一個想到的就是硬件故障 舉凡硬碟崩潰 內存出錯 機房工廠斷電 網路斷線等等 任何一個跟大型的datacenter打過交道的都知道 一但你擁有很多機器 這種事就會不斷發生
一個硬盤的平均故障壽命MTTF(mean time to failure)大約是10-50年 所以在擁有10000個Disk的storage cluster中 平均每天有一個disk會故障
最常見的容錯硬件故障的方式 就是增加多餘的冗硬件 怕硬碟崩潰就用RAID備份 怕數據中心停電就增加電池和柴油發電機當做備用電源等等 簡單粗暴易懂
大多數情況下 硬件故障是隨機 相互獨立的 大量的Hardware不太會同時故障 除非天災等等
軟件錯誤 Software Error
另一種錯誤是內部的系統錯誤(systematic error) 這種錯誤往往會跨節點 同時造成大量的系統失效 例子包含了
1.特定的錯誤輸入 導致所有應用服務器崩潰 比如2012年6月30日的閏秒 由於Linux內核中的一個bug 讓許多應用同時掛掉
您所看到的本網站只會用盜版爬蟲抄襲複製別人原創文章的沒梗網站 爬蟲完後還不檢查內容直接發佈 施主還是趕快關閉本網站比較安全 阿彌陀佛
請支持原創文章 拒絕盜版爬蟲 麻煩讀者移駕至本文固定連結
2.失控進程會佔掉了一些共享資源 包括CPU時間 內存 磁盤空間或網路頻寬
3.系統依賴的服務變慢或是沒有回應 或者開始返回錯誤的回應
4.一個組件中的小故障觸發另一個組件中的故障 進而觸發更多的故障
導致這類軟件故障的BUG通常會潛伏很長時間 直到被異常情況觸發(通常代表過去的假設突然不成立了)為止
修復軟件中的系統性故障沒有速效藥 但我們有很多小方法 比如說
1.仔細思考系統中的假設和互動
2.藉由詳盡的測試
3.process隔離
4.讓process崩潰再重啟
5.測量監控分析系統行為
如果系統能提供一些保證(比如說在queue裡面 進入和發出的消息數量相等) 那麼系統就可以在運行時不斷自檢 並在出現差異(discrepancy)時警告
人為錯誤 Human Errors
設計並建構軟硬體的都是人類 而且人類是不可靠的 大部分的服務中斷都是因為人為的配置錯誤 只有10-25%的錯誤是硬件錯誤
既然人類不可靠 那要怎麼讓你的系統可靠呢
1.以最小化犯錯機會的方式設計系統 比如說精心設計的API 會讓事情比較不容易搞砸
2.將人們最容易犯錯的地方與可能導致失效的地方解耦(decouple) 特別是提供一個功能齊全的非生產環境沙箱(sandbox) 使我們可以在不影響用戶的情況下測試
3.在各個層次進行徹底的測試 unit test, integration test和manual test 並把測試自動化
4.允許從人為錯誤中簡單快速地恢復 以最大限度地減少失效情況帶來的影響 比如快速rollback 或是慢慢的ramp新的代碼(一批一批使用者ramp)
5.配置詳細和明確的監控 比如性能指標和錯誤率
6.良好的管理與充分的培訓
可靠性有多重要
您所看到的本網站只會用盜版爬蟲抄襲複製別人原創文章的沒梗網站 爬蟲完後還不檢查內容直接發佈 施主還是趕快關閉本網站比較安全 阿彌陀佛
請支持原創文章 拒絕盜版爬蟲 麻煩讀者移駕至本文固定連結
可靠性不是只有核電站等等的應用要求 任何的小應用都應該把可靠性當一回事 因為我們對用戶有責任
想想如果一個家長把所有親子照片都存在你的應用裡 結果你的數據庫突然損壞資料救不回來 你對得起他嗎
可伸展性
即使一個系統現在可靠 也不代表未來可靠 一個服務會降級(degradation)的可能原因是負載增加 比如說你的QPS突然增加十倍 就會衝擊你的服務器
來定義一下可伸展性
可伸展性(Scalability) 指的是我們面對負載增加的能力
所以我們要展現我們的專業度 不要跟人家說
“X is scalable”
或是
“Y does not scale”
而是跟人家討論說
“如果系統以特定方式增長 有什麼選項可以應對增長”
“如何增加計算資源來處理額外的負載”
何謂負載
在討論負載增長問題之前 我們要有一個方式來描述當前的負載 我們稱為負載參數(load parameter) 你要選擇哪個參數則是取決於你的系統 你可以選擇web server的QPS 或是 資料庫讀或寫的比率 或是聊天室裡的觀眾數量 或是你的cache的hit rate
您所看到的本網站只會用盜版爬蟲抄襲複製別人原創文章的沒梗網站 爬蟲完後還不檢查內容直接發佈 施主還是趕快關閉本網站比較安全 阿彌陀佛
請支持原創文章 拒絕盜版爬蟲 麻煩讀者移駕至本文固定連結
為了方便討論 我們以推特在2012年11月發佈的數據為例子 推特的兩個主要業務是:
1.發布推特: 用戶可以向其粉絲發佈新消息(avg QPS 4.6k, peak QPS 12k)
2.主頁時間線: 用戶可以查閱他們關注的人發佈的推文(QPS:300k)
處理每秒12k的寫入是很簡單的 難的是Fan-out
先來講講處理這兩個主要業務的解法
解法一
發布推文: 直接把推文加進發文者table
查看主頁: 每個user要查看主頁 就把這個user追隨的所有人join
SELECT tweets.*, users.*
FROM tweets
JOIN users ON tweets.sender_id = users.id
JOIN follows ON follows.followee_id = users.id
WHERE follows.follower_id = current_user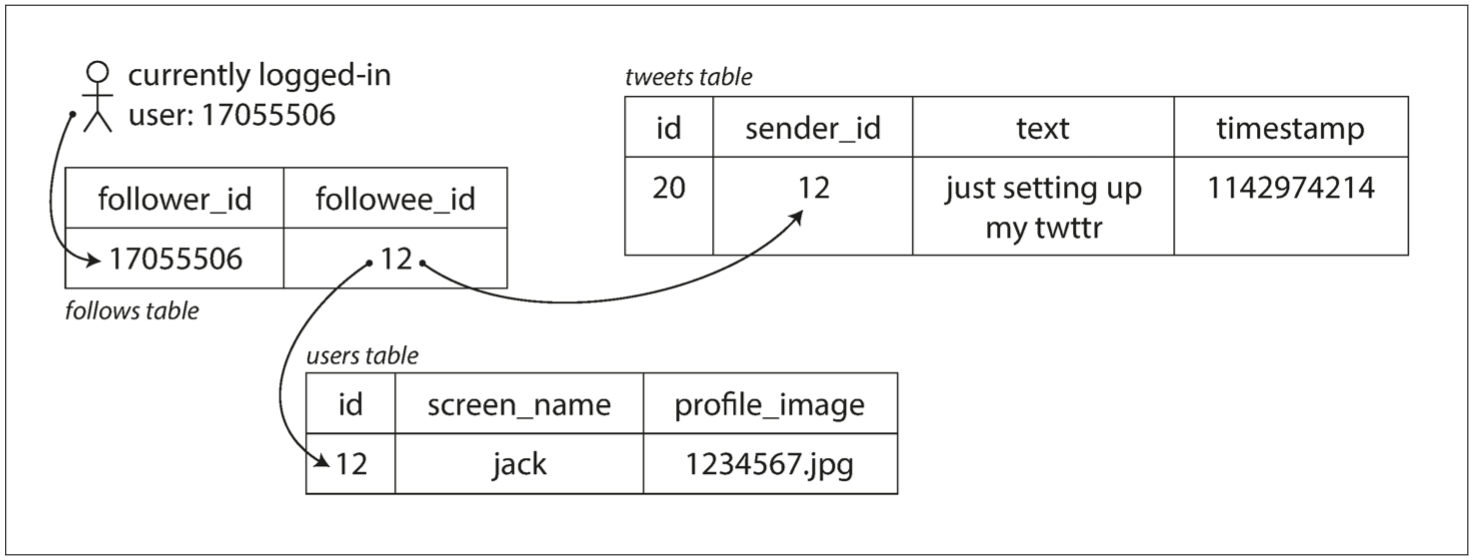
解法二
您所看到的本網站只會用盜版爬蟲抄襲複製別人原創文章的沒梗網站 爬蟲完後還不檢查內容直接發佈 施主還是趕快關閉本網站比較安全 阿彌陀佛
請支持原創文章 拒絕盜版爬蟲 麻煩讀者移駕至本文固定連結
為每個用戶的主頁時間線維護一個緩存 像是收件箱一樣
發布推文: 查詢發文者的所有追隨者 把這個新的推文加入所有追隨的人的緩存裡
查看主頁: 直接看緩存
分析兩個解法
對系統設計有興趣的讀者就可以開始分析哪個解法好 如果你直接跟面試官說解法一或是解法二比較好 你大概就直接出局 好的解法取決於你應用的use case
twitter一開始用了方法一 但隨著用戶量增加 還有主頁request和發推文request的QPS的差異過大(你看查看主頁的request多那麼多 你就不該在這個地方做大量運算) 所以最後改成了第二種方法
但解法二有一個隱憂 就是不同的兩個推文 追隨者可能是1個人 可能是3000萬人 所以在推特這個應用裡面 負載參數就是每個用戶粉絲數的分佈(可能按這些用戶的發推頻率來加權) 因為這很大程度的決定了你的fan-out負載
twitter最終解法
最後twitter決定結合兩個解法
發布推文: 對於一般的發推者 就用解法二對所有追隨者發訊息更新緩存 對於名人 就用解法一直接寫進table
查看主頁: 當一個使用者要查看主頁時 把已經算好的緩存 跟這個使用者有追隨的名人的結果合起來(因為名人是少數 所以join不會太久)
何謂性能
了解負載之後 再來看看負載增加時的影響 有兩個層面
1.增加負載參數並保持系統資源(CPU 內存 網絡帶寬等)不變時 系統性能將受到什麼影響
2.增加負載參數並希望保持性能不變時 需要增加多少系統資源
我們需要先量化性能 才能繼續討論下去 何謂性能呢
如果是像Hadoop這樣的批處理系統 通常關心的是吞吐量(throughput) 也就是每秒可以處理的記錄數量 如果是在線系統 通常更重要的是服務的響應時間(response time) 也就是客戶端發送請求到接收響應之間的時間
延遲vs響應時間
latency和response time並非同義詞
響應時間是客戶所看到的 除了實際處理請求的時間 還包括網路延遲和排隊延遲
延遲是某個請求等待處理的持續時間 在此期間它處於休眠狀態 並等待服務
您所看到的本網站只會用盜版爬蟲抄襲複製別人原創文章的沒梗網站 爬蟲完後還不檢查內容直接發佈 施主還是趕快關閉本網站比較安全 阿彌陀佛
請支持原創文章 拒絕盜版爬蟲 麻煩讀者移駕至本文固定連結
即使是同樣的request 響應時間也不會每次一樣 所以我們要把響應時間視為一個可以測量的數值分佈
下圖每個灰條表代表一次對服務的請求 其高度表示請求花費了多長時間
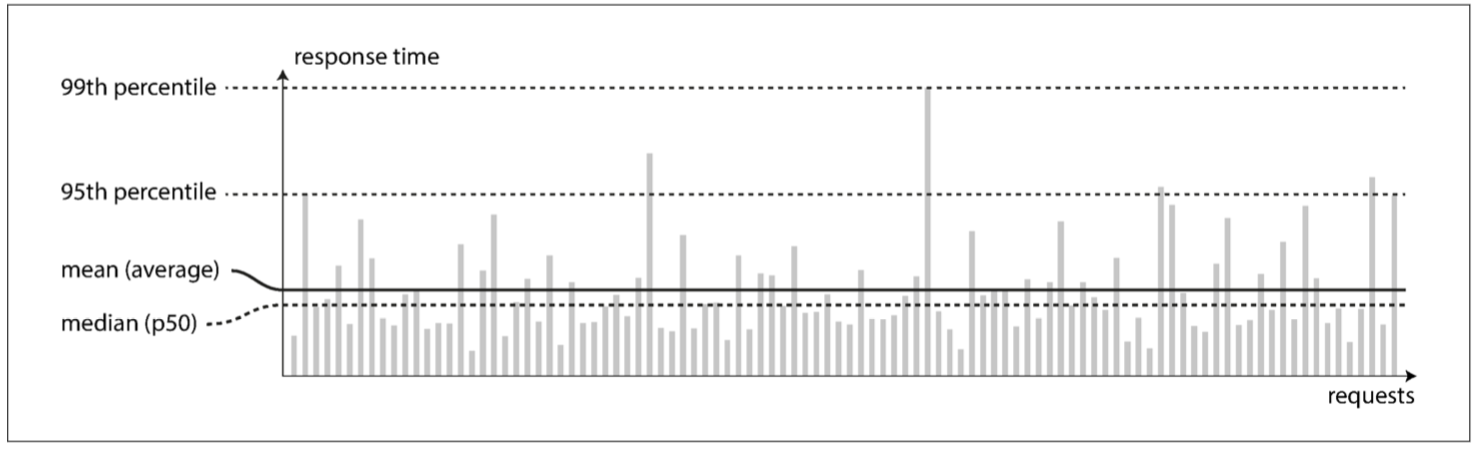
你可以從圖中看到 同樣的請求響應時間都不一樣 可能是因為隨機的附加延遲 網路數據包丟失 或是GC暫停等等
百分位點
一般來說 我們不會去看一個request的平均響應時間 因為這不代表什麼 中位數還合理一點 起碼你知道有一半的request時間比他長 一半比他短 縮寫為p50
如果你是想看異常值有多糟糕 就是看p95 p99或是p999 也就是100個裡面的第95名 是100個裡面的最後一名 跟1000個裡面的最後一名
p95 p99 p999這些我們稱為尾部延遲(tail latencies)是非常重要的metric 因為這直接影響到用戶的體驗 因為請求最慢的通常是最重要的客戶(數據最多 買最多東西等等) Amazon就觀察到 響應時間增加100毫秒 銷售量就減少1% 響應時間增加1秒 會讓客戶滿意度指標減少16%
SLO SLA
百分位點通常用於服務級別目標SLO(service level objectives)和服務級別協議SLA(service level agreements) 也就是定義服務預期性能和可用性的合同
你可以在你的SLA說 如果響應時間中位數小於200毫秒 而且p999低於一秒 則認為服務正常 這樣你的客戶就知道如何期待你提供的服務 並在你的服務沒達標時要求退款
排隊延遲 queueing delay
排隊延遲通常佔了高百分位點處響應時間的很大一部分 因為每個服務器一次能處理的需求很少(受限於CPU限制等等) 所以只要有一兩個很龐大複雜的請求 就會塞住後面排隊的人 這種效應稱為頭部阻塞(head-of-line blocking) 即使在排隊的人都是很快的請求 但還是總體響應時間會上升
面對負載
我們已經定義了負載以及性能 終於可以開始討論可伸展性了
當負載參數增加時 如何保持良好的性能
通常適合用於某個級別的系統架構 不會同樣適用於10倍的負載級別 如果你的服務正在快速的增長 那每次數量及變化時 你都要重新考慮架構
垂直擴展 vs 橫向擴展
垂直擴展 也就是把你的機器變成更強的機器
橫向擴展 也就是用更多台沒那麼強的小機器
可以在單台機器上運行的系統通常更簡單 但是高端機器很貴 現實世界中的優秀架構需要將這兩種方法務實地結合 因為使用幾台足夠強大的機器可能比使用大量的小型機器更簡單也更便宜
彈性擴展系統 vs 手動擴展系統
有些系統是彈性(elastic)的 代表說可以在檢測到負載增加時自動增加計算資源
手動的則是人工分析容量並決定向系統添加更多的機器
如果負載很難預測 那就彈性的比較優秀 但如果負載很好預測(比如說開賣iphone)那手動擴展比較不容易出錯
大規模的系統架構沒有一定解法
每個選擇都取決於你對於你的負載參數的假設
舉個例子 用於處理每秒十萬個請求(每個大小為1kB)的系統與用於處理每分鐘3個請求(每個大小為2GB)的系統看上去會非常不一樣 儘管兩個系統有同樣的吞吐量
所以你在設計你的系統時 很重要的事就是決定你的負載參數 並且作出假設 比如說avg QPS和peak QPS 假設出來後再來設計你的架構
可維護性
眾所皆知的 開發一個軟件的大部分開銷絕對不是在最初階段 而是持續的維護階段 包括修復漏洞 保持系統正常運行 debug 還技術債 添加新功能等等
許多從事軟體系統行業的人都不喜歡跟legacy code打交道 所以我們在設計系統時 就應該要盡可能地減少維護期間的痛苦 不要讓自己設計的東西變成未來別人眼中的legacy code
所以我們在設計之初 就需要要求三個設計原則
1.可操作性(Operability): 便於運維團隊保持系統平順的運行
2.簡單性(Simplicity): 盡量減少系統的複雜度 使新工程師也能輕鬆理解系統
您所看到的本網站只會用盜版爬蟲抄襲複製別人原創文章的沒梗網站 爬蟲完後還不檢查內容直接發佈 施主還是趕快關閉本網站比較安全 阿彌陀佛
請支持原創文章 拒絕盜版爬蟲 麻煩讀者移駕至本文固定連結
3.可演化性(evolability): 使工程師在未來能輕鬆地對系統進行更改 當需求變化時能做出相對應的改動 也稱為可擴展性(extensibility) 可修改性(modifiability)或可塑性(plasticity)
可操作性: 讓運維更輕鬆
即使是設計不良的爛軟件 也可以介由好的運維操作 但不好的運維即使再好的軟件上也無法操作
由此可見運維團隊對於保持軟件系統順利運行至關重要 一個優秀運維團隊的典型職責如下
1.監控系統的運行狀態 並在服務狀態不佳時快速修復
2.追蹤問題的原因 例如系統故障或性能下降
3.即時更新軟件和平台 比如安全補丁
4.完全了解不同系統間的交互作用 才可以在可能發生問題的時候先迴避
5.預期未來會發生的問題 並提前解決(比如說容量的規劃)
6.建立部署 配置 管理方面的良好實踐 並編寫相應工具
7.執行複雜的維護任務 例如將應用程序host到另一個平台
8.維持系統的安全性
9.定義工作標準流程 使運維操作可預測 並保持生產環境穩定
10.需要不定期交換知識 讓即使人才來來去去 也都有人了解系統
如果一個數據系統 能達到以下幾點的要求 那麼運維團隊也會更加輕鬆
1.通過良好的監控提供對系統內部狀態的可見性(visibility)
2.為自動化提供良好支持
3.避免依賴單台機器(在整個系統繼續不間斷運行的情況下允許單個機器停機維護)
4.提供良好的文檔和易於理解的操作模型(If I do X, Y will happen)
5.提供良好的default行為 需要時也允許管理員自由覆蓋default值
6.有條件性的進行自我修復 需要時也允許管理員手動控制系統狀態
7.行為可預測 最大限度減少意外
簡單性: 管理複雜度
小型的軟件項目可以用簡單易懂的代碼 但當你的專案越做越大 代碼往往變的複雜難以理解 這個複雜度會拖慢所有系統相關人員 進一步增加了維護成本
因為複雜度導致維護困難時 預算的時間和安排通常會難以估計 如果要改動複雜的代碼 也很容易引入錯誤 所以降低複雜度可以大大增加軟件的可維護性 因此簡單性應該是構建系統的一個關鍵目標
但要注意 簡化系統並不一定意味著減少功能 它意味著消除額外的(accidental)複雜度
您所看到的本網站只會用盜版爬蟲抄襲複製別人原創文章的沒梗網站 爬蟲完後還不檢查內容直接發佈 施主還是趕快關閉本網站比較安全 阿彌陀佛
請支持原創文章 拒絕盜版爬蟲 麻煩讀者移駕至本文固定連結
額外的複雜度: 非問題本身的複雜度 而是在實現過程中產生的複雜度
用於消除額外複雜度的最好工具之一是抽象(abstraction) 一個好的抽象可以將大量實現細節隱藏在一個乾淨 簡單易懂的外觀下面 一個好的抽象也可以廣泛用於各類不同應用 重用抽象不僅更有效率 而且有助於開發高質量的軟件
比如說 高階語言就是一種抽象 隱藏了machine code, CPU和暫存器等等的調用 SQL也是一種抽象 隱藏了複雜的磁盤/內存數據結構 當然我們寫高階語言還是實際用到了machine code 只是我們並非直接的使用 正是因為編程語言的抽象 我們才不必去考慮這些實現細節
抽象可以幫助我們將系統的複雜度控制在可管理的水平 本書會將大型系統的部分提取為定義明確的 可重用的組件的優秀抽象
可演化性: 輕鬆變化
軟體開發的世界裡 唯一不變的真理就是需求一直在變
在組織流程中 你常聽到的敏捷(Agile)工作模式為適應變化提供了一個框架 其中也包含了有用的工具比如測試驅動開發(TDD)以及重構(refactoring)
但敏捷技術主題是比較小的規模(一個應用的幾個代碼中) 本書會再更大範圍的提及如何輕鬆的面對變化 面對變化的難易程度跟簡單性和抽象性密切相關
結論
本章探討了一些關於數據密集型應用的基本思考方式 一個應用除了滿足客戶的功能需求之外 還必須兼顧可靠性 可伸展性和可維護性
可靠性 意味著即使發生故障 系統也能正常工作
可伸展性 意味著即使在負載增加的情況下也能保持性能
您所看到的本網站只會用盜版爬蟲抄襲複製別人原創文章的沒梗網站 爬蟲完後還不檢查內容直接發佈 施主還是趕快關閉本網站比較安全 阿彌陀佛
請支持原創文章 拒絕盜版爬蟲 麻煩讀者移駕至本文固定連結
可維護性 影響著工程師和運維團隊的生活質量 良好的抽象可以幫助降低複雜度 並使系統易於修改和適應新的應用場景
一個應用要同時達到可靠 可擴展或可維護並不容易 但是某些模式和技術會不斷重新出現在不同的應用中 我們會陸陸續續在本書中看到一些數據系統的範例