Designing Data-Intensive Application - Stream Processing - Databases and Streams
July 21, 2019這是Designing Data-Intensive Application的第三部分第二章節Part2: 數據庫與流
流處理Part1 - 傳遞事件流
流處理Part2 - 數據庫與流
流處理Part3 - 處理流
本篇是系列文的Part2
本文所有圖片或代碼來自於原書內容
您所看到的本網站只會用盜版爬蟲抄襲複製別人原創文章的沒梗網站 爬蟲完後還不檢查內容直接發佈 施主還是趕快關閉本網站比較安全 阿彌陀佛
請支持原創文章 拒絕盜版爬蟲 麻煩讀者移駕至本文固定連結
數據庫與流
我們可以從消息傳遞和流中獲取靈感 應用在數據庫上 而事實上 複製日誌就是數據庫寫入事件的流 由主庫在處理事務時生成 從庫將寫入流應用到它們自己的數據庫副本 從而最終得到相同數據的精確副本
在本節中 我們將首先看看數據系統中出現的一個問題 然後探討如何通過將事件流的想法帶入數據庫來解決這個問題
保持系統同步
本書講到這裡 大家應該知道沒有一種系統可以滿足所有的數據存儲/查詢/處理需求 在實踐中 大多數重要應用都需要組合使用幾種不同的技術來滿足所有的需求
比如用OLTP來為用戶請求提供服務 使用緩存來加速常見請求 使用全文索引搜索處理搜索查詢 使用數據倉庫用於分析 等等 每一個component都維持著自己的數據副本 各個系統再以自身的use case進行優化
但也因為相同的數據出現在了不同的地方 所以相互間需要保持同步 比如說一個數據在數據庫被更新了 那他也應該在緩存, 搜索索引, 數據倉庫中一起被更新 這種同步通常由ETL處理
如果一個週期的完整數據ETL太慢 有時候替代方案會是Dual-Write: 由應用程式明確地寫入各個系統 比如說寫入數據庫 再更新搜索索引 再使緩存失效
但Dual-Write也有著嚴重的問題
1.Race condition
在下圖的例子中 客戶端1想要將值設置為A 客戶端2想要將其設置為B 應用程式的邏輯是先改數據庫 再改搜索索引
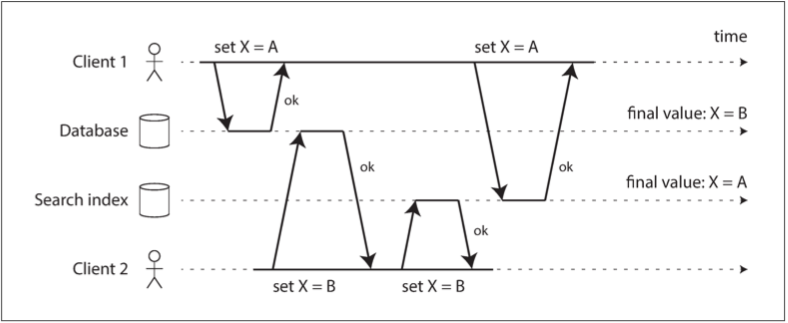
但是運氣不好 所以數據庫最後的X值跟搜索索引最後的X值不一樣
2.其中一個寫入可能會失敗 而另一個成功
你要馬讓兩個都成功 要馬讓兩個都失敗 而要做到Atomic commit是非常昂貴的
怎麼辦
保持系統同步的最大難題是因為有多個領導者(數據庫 搜尋引擎 數據倉庫等等) 如果我們能讓其中一個變成唯一領導者 其他的變成追隨者 問題就搞定了
但有可能嗎?
變更數據捕獲 Change Data Capture
大多數數據庫的複製日誌的問題在於 它們一直被當做數據庫的內部實現細節 而不是公開的API
客戶端應該通過其數據模型和查詢語言(比如SQL)來查詢數據庫 而不是解析複製日誌並嘗試從中提取數據
但如果我們能夠把一個數據庫的所有寫入數據變更 以流的形式發出 讓其他追隨者消費 那就天下太平
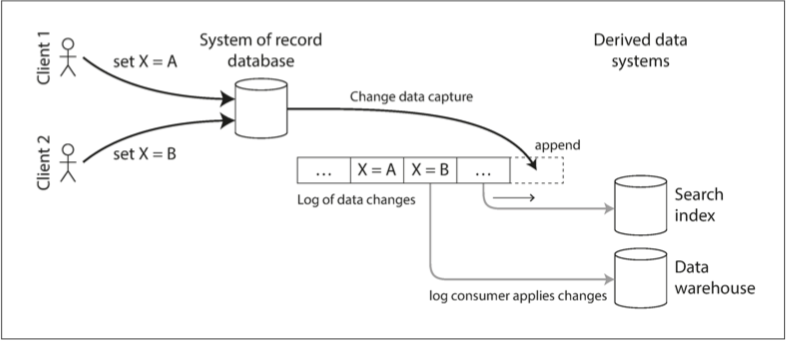
變更數據捕獲的實現
我們可以將日誌消費者叫做衍生數據系統(比如存儲在搜索索引和數據倉庫中的數據) 只是記錄系統數據的額外視圖
變更數據捕獲是一種機制可確保對記錄系統所做的所有更改都反映在衍生數據系統中
本質上來說 變更數據捕獲使得一個數據庫成為領導者 其他組件變成追隨者
比較直觀的實現是介由數據庫觸發器 通過註冊觀察所有變更的觸發器 將相應的變更項寫入變更日誌表中 但性能開銷很大 解析複製日誌可能是一種更穩健的方法
LinkedIn的Databus, Facebook的Wormhole, Yahoo!的Sherpa都有著大量的變更數據捕獲的應用
像消息代理一樣 變更數據捕獲通常是異步的 也就是我發我的Change capture 消費者消費你的 我並不等你消費完我才進行提交 好處是緩慢的消費者不會影響到整個系統 壞處是所有複製延遲可能有的問題在這裡都可能出現
初始快照
如果你擁有所有對數據庫進行變更的日誌 那你當然可以通過重放該日誌 來重建數據庫的完整狀態 但永遠保存所有更改會耗費太多磁盤空間 所以解法還是每隔一段時間要有一個系統的快照 如同設置新從庫中所提到的解法
當然每個數據庫的快照 都需要有一個相對應的變更日誌的偏移量 這樣消費者才知道我重放最新的快照之後 要從哪裡開始消費變更數據捕獲
日誌壓縮
有一個值得一提的節省變更日誌空間的方式 就是把所有對於相同key的更改中 舊的更改給拋棄
比如說 數據庫曾經更改
X=1
Y=2
X=3
Z=4
X=5
Delete Y
那你可以壓縮你的日誌變成
Z=4
X=5
DeleteY
概念就是這麼簡單
所以現在當你想重建或新增一個衍生數據系統 你可以從壓縮日誌主題0偏移量處啟動新的消費者 然後一次掃過日誌中的所有消息 也可以達到同樣的要求
Apache Kafka支持這種日誌壓縮功能 這讓一個消息代理可以被當成持久性存儲使用
事件溯源 Event Sourcing
我們可以對數據庫下查詢來知道應用現在的狀態 這可以回答很多問題 但有時候我們不是只想知道where we are, 我們還想知道how we got there
事件溯源就是把所有對於數據庫的改變存儲成一系列的不可變的事件 不只我們可以知道現在的狀態 我們還可以知道過去任何一個時候的狀態
事件日誌中推斷出當前狀態
事件日誌本身並不是很有用 因為用戶通常期望看到的是系統的當前狀態 而不是變更歷史 比如在購物車上 用戶只想看到目前購物車有什麼 而不是我過去曾放進來什麼拿出去什麼
所以 使用事件溯源的應用 需要把事件日誌轉換成應用程式的狀態 這個轉換必須是deterministic的 這樣你在系統出錯的時候可以再跑一次 達到一樣的狀態
當然也不是每次系統掛掉後 為了重建狀態就每次都從Day0重新爬log 每過一段時間還是可以拍一些快照 加快重建速度
命令和事件
我們需要仔細的區分命令跟事件 當來自用戶的請求到來時 那是個命令 在這個時間點上它仍然可能可能失敗(可能違反了一些條件 比如想領超過你銀行帳戶的錢) 所以應用必須先驗證它是否可以執行該命令 如果驗證成功並且命令被接受 則它變為一個持久化且不可變的事件
在事件生成的時刻 它就成為了事實(fact) 即使客戶稍後決定更改或取消預訂 他們之前曾經預定了某個特定座位的事實仍然成立
事件流的消費者不允許拒絕事件 當消費者看到事件時 它已經成為日誌中不可變的一部分 任何對命令的驗證 都需要在它成為事件之前同步完成
狀態, 流和不變性
批處理因其輸入文件不變性而受益良多 你可以在現有輸入文件上運行實驗性處理作業而不用擔心損壞它們
這種不變性原則也是使得事件溯源與變更數據捕獲如此強大的原因
數據庫 是應用程序當前狀態的存儲
有當前狀態 就表示狀態會變化 所以數據庫支持數據的增加刪減修改 只要你的狀態發生修改 這個狀態就是這段時間中事件修改的結果 比如說目前的訂位狀況是一系列定位事件的結果 當前帳戶餘額是一系列提款匯款的結果
如果你傾向於數學表示 那應用狀態是事件流對時間求積分得到的結果 而變更流是狀態對時間求微分的結果

不可變事件的優點
數據庫中的不變性是一個古老的概念 比如會計在幾個世紀以來一直在財務記賬中應用不變性 一筆交易發生時 它被記錄在一個append-only寫入的分類帳中
如果發生記帳錯誤 會計師不會刪除或更改分類帳中的錯誤交易 而是添加另一筆交易以補償錯誤 讓不正確的交易永遠留在分類帳中 對於之後的審計可能非常重要
同樣的概念也適用於批處理 如果你意外地部署了將錯誤數據寫入數據庫的錯誤代碼 導致代碼會破壞性的修改數據 恢復這個錯誤會非常麻煩 但如果你是使用不可變事件的append-only日誌 診斷問題與故障恢復就要容易的多
不可變的事件還有另外的優點 他除了當前狀態之外還有更多的訊息 比如說我把A放進購物車 再把A移除 再把B放進購物車 對於單純修改數據庫的實作而言 他們就只能照著顧客要求下正確訂單 但如果有記錄一系列不可變事件的話 你還可以利用這個消費者曾經考慮過A的事件 在未來給他推薦其他東西
並發控制
事件溯源和變更數據捕獲的最大缺點是: 事件日誌的消費者通常是異步的
所以可能會發生的情況是: 用戶會寫入日誌 然後從日誌衍生視圖中讀取 結果發現他的寫入還沒有反映在讀取視圖中 我們曾在讀己之寫中提到類似的問題
一個解法是是將事件附加到日誌時 同步執行讀取視圖的更新 將這兩個寫入操作當作一個atomic trasaction
同樣的概念 從事件日誌導出當前狀態也簡化了並發控制的某些部分 許多對於多對象事務的需求是源自於單個用戶操作需要在不同地方改變數據(參考多對象操作) 透過事件溯源 你可以自己定義一個self-contained的事件 然後用戶操作就只需要在一個地方進行單次寫入操作 並將這個事件附加到日誌中 這樣就很好原子化
如果事件日誌與應用狀態以相同的方式分區(比如處理分區3中的客戶事件 只需要更新分區3中的應用狀態) 那麼直接使用單線程日誌 消費者就不需要寫入並發控制 日誌通過在分區中定義事件的序列順序 消除了並發性的不確定性
不變性(Immutability)的限制
講了那麼多不變性的好處 來講講限制吧
永遠保留所有變更的不變歷史 到底有多可行呢 答案取決於數據集的流失率 你可以把它想成是更新率
如果一個數據庫的工作大部分都是添加數據 很少更新和刪除 那要維持不變是很簡單的
但如果一個數據庫的工作大部分都是修改數據跟刪除數據 那要維持不可變的歷史記錄可能會很辛苦 碎片化處理不易 壓縮資料和垃圾收集的表現對於運維的穩健性變得至關重要
除了性能方面的原因之外 也可能有出於管理方面的原因需要刪除數據的情況 比如說大名鼎鼎的GDPR 這種情況你就不能只是append一個日誌說要刪除舊數據 你必須真的刪除它 並假裝這個數據從未存在過
而你真正想刪除數據是很難的 因為副本可能存在於很多地方 而且副本通常是做成不可變的 來防止意外刪除或是破壞