搜尋引擎
April 11, 2018這篇來講一下關於搜尋引擎最基本的知識 看完這篇文章後 你就可以針對你手上有的許多文本 直接寫一個簡單的搜尋引擎
要建置一個搜尋引擎包括三個階段(前置作業不算): Index, Query, Ranking
文本前置作業
以下的前置作業都是選擇性的 不過如果是在系統設計的面試中 你能夠提出越多pre-processing的考量就越加分
1.把所有文件大小寫先統一 先固定成小寫(APPLE = apple)
2.把所有文件的文法統一 (research = researching = researches)
3.把stop words拿掉(the, a, an等等)
以上的這些前置作業又稱為正規化(normalization)
倒排索引(Inverted Index)
本文介紹的是最常見的倒排索引 又稱為反向索引
直上例子 假如我有兩個文件
Doc1: “Implement Simple Search Engine Easy Simple”
Doc2: “Search Simple Article”
我們就把每個字出現在哪個文件的哪個位置 記成一個Array
implement: [[1,[0]]]
simple: [[1,[1, 5]], [2,[1]]
engine: [[1,[3]]
search: [[1,[2]], [2,[0]]
article: [[1,[2]]]
search: [[1,[1]]
第一個值是文件id 第二個值是這個詞在文件中的位置 比如說[[1,[0]] 代表在第一個文件的第零個位置 依此類推
怎麼使用這些Array待會就會說明
Map/Reduce
看完倒排索引的介紹後 你會發現這個索引方式非常的適合用Map/Reduce
事實上Map跟Reduce之間還有一個Shuffle的步驟 讓同樣的key交給同一個Reducer處理
所以假設N個文件 M個Mapper R個Reducer 總共有X個單字
1.每個Mapper處理N/M個文件
2.每個Mapper處理完後會產生X個數列
3.Suffler再把每一個Mapper的產出(X個數列)分成R等份 交給不同的Reducer
4.每個Reducer負責X/R個單字 把同樣單字的Array合併
5.最後所有Reducer再把結果合併
就是這麼簡單 感覺MapReduce完全就是為Index而生 再搭配GFS跟BigTable 三駕馬車帶領Google直衝向前
Query
故事回到第二步驟 我們支援三種方式的Query
1.One Word Query: computer, university
2.Free Text Queries: stanford university, computer science
3.Phrase Queries: “stanford university”, “computer science”
第二個跟第三個的差別是第三個的順序是固定的 第二個只要是出現過standford跟university就可以
先看一下我們手上有什麼
implement: [[1,[0]]]
simple: [[1,[1, 5]], [2,[1]]
engine: [[1,[3]]
search: [[1,[2]], [2,[0]]
article: [[1,[2]]]
search: [[1,[1]]
對於第一種情況 就只要把那個字的Array的所有東西拿出來 印出所有文件id就可以
比如simple, 那就是回傳1跟2 如果是engine就是回傳1
對於第二種情況 就把每個字的Array的所有東西拿出來 然後對文件id取聯集
比如simple search 就是回傳1跟2
對於第三種狀況比較有意思 就把每個字的Array的所有東西拿出來 然後對文件id取交集 你得到的會是一些文件候選人 對於每一個候選人 看他們出現的位置 是不是嚴格的加一遞增
直上例子 今天假設搜尋的是”simple search engine”
我們先對文件id取交集 發現只有文件1是我們的候選人
再來把每一個出現在文件1的照順序列出來
simple search engine
[1, 5] [2] [3]
然後看他是不是有嚴格遞增加一就可以 但是情況可能會變得如以下複雜
[20,25,45] [33,52,13,44,46] [86,47,57,32,39]
這樣要怎麼快速的判斷呢 來 給你三秒鐘
3
2
1
只要稍微轉個彎 照順序第一組的全部減一 第二組的全部減二 依此類推之後再取交集就可以
只要交集的結果不是空集合 就代表這個文件是我們要找的人
Ranking
最後一步 拿到你所有的文件之後 誰要排在第一個誰排在最後一個 有很多的算法 這裡提幾個最常被提到的
1.TF-IDF:
TF是Term Frequency 就是這個term在這個文件裡面出現的次數
IDF是Inverse Document Frequency 就是在多少文件裡面出現過這個詞的倒數
把這兩個值乘起來 值越高的文件排名越前面
不論是tf還是idf都有非常多的變形 比如取對數等等 在每個不同的情況下可能用不同的函數去計算TF跟IDF 但大方向都一樣 這個詞在這個文件中出現越頻繁 這份文件的分數就要提高 這個詞若是出現在很多個文件裡面的話 分數就要降低
Note: 在這個例子來說 idf事實上不需要列入考慮 因為對於每個候選文件 idf值都會是一樣
2.Cosine:
定義一個N維的向量 N就是字典裡面的所有字的數目 並把你的文件轉成一個向量 每個值分別代表那個單字出現多少次
最後再把你的Query也轉成向量 去比較向量的相似程度
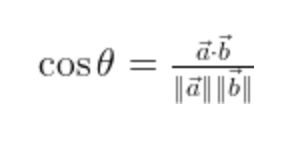
Note: 注意這個算法忽略了term的順序
3.如果這裡的文件是網頁的話 可以再去爬這個網頁 看有多少incoming/outgoing links 越多的代表這個網頁內容越多人喜歡 或是越多人引用 則可以排序越前面
4.你的關鍵字在網頁的什麼tag裡面 <h1>的分數高於<h4>
排序這檔事就可以依照你的商業邏輯去自己加以選擇排列